Языковые модели как компиляторы: Возможно ли?
Автор: Денис Аветисян
Исследование потенциала больших языковых моделей для прямой компиляции кода без традиционных этапов обработки.
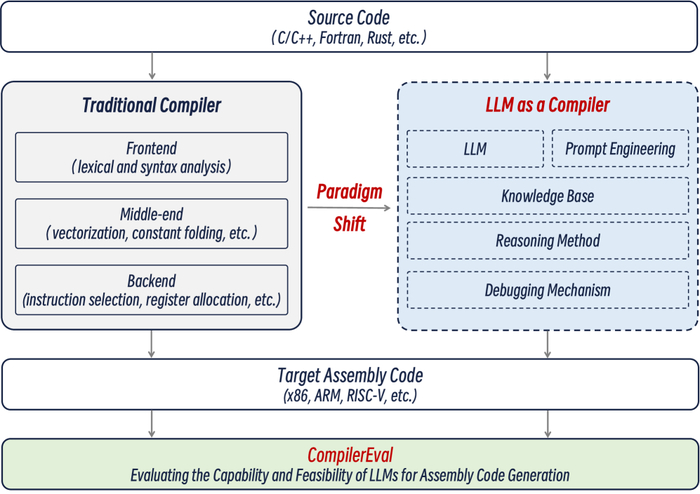
Традиционная парадигма компиляции претерпевает сдвиг, уступая место языковым моделям как новым компиляторам, чьи возможности валидируются посредством комплексного набора данных и фреймворка CompilerEval.
В статье рассматривается возможность использования больших языковых моделей для end-to-end компиляции, включая генерацию ассемблерного кода и кросс-платформенную поддержку, с анализом результатов на наборе данных CompilerEval.
Несмотря на значительные успехи в различных областях, возможность использования больших языковых моделей (LLM) в качестве полноценных компиляторов оставалась малоизученной. Данная работа, 'Exploring the Feasibility of End-to-End Large Language Model as a Compiler', посвящена исследованию потенциала LLM для прямой трансляции исходного кода в машинный, с акцентом на разработку датасета CompilerEval и фреймворка LaaC. Эксперименты показали, что LLM демонстрируют базовые способности к компиляции, однако текущий процент успешной компиляции остается низким. Возможно ли, путем оптимизации запросов, масштабирования моделей и внедрения методов рассуждения, создать LLM, способные генерировать высококачественный ассемблерный код и изменить парадигму компиляции?
Эволюция Компиляции: От Надежности к Гибкости
Традиционная компиляция, несмотря на свою надежность, представляет собой сложный и ресурсоемкий процесс. Растущий спрос на кроссплатформенность и поддержку специализированного оборудования требует адаптивных решений. Технологии искусственного интеллекта, в частности, большие языковые модели (LLM), предлагают принципиально новый подход к компиляции, способный упростить и ускорить разработку. Прозрачность алгоритмов – ключ к безопасному и эффективному программному обеспечению.
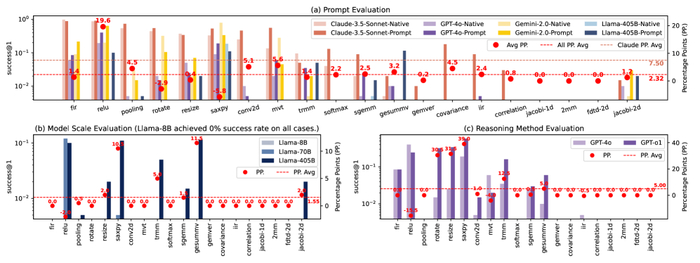
Исследование демонстрирует влияние методов промпт-инжиниринга, масштаба модели и методов рассуждения на успешность компиляции с использованием больших языковых моделей.
Возможность сквозной компиляции с использованием LLM демонстрирует потенциал для упрощения процесса разработки.
LLM как Компилятор: Новый Парадигма
Предлагаемый подход основан на непосредственном преобразовании исходного кода в машинный язык с использованием больших языковых моделей (LLM), минуя традиционные этапы компиляции. Разработанная платформа LaaC (LLM as a Compiler) является развитием данной идеи, ключевым компонентом которой является база знаний, содержащая информацию об исходных языках и наборах инструкций целевых архитектур. Несмотря на перспективность, текущие показатели успешной компиляции остаются относительно невысокими.
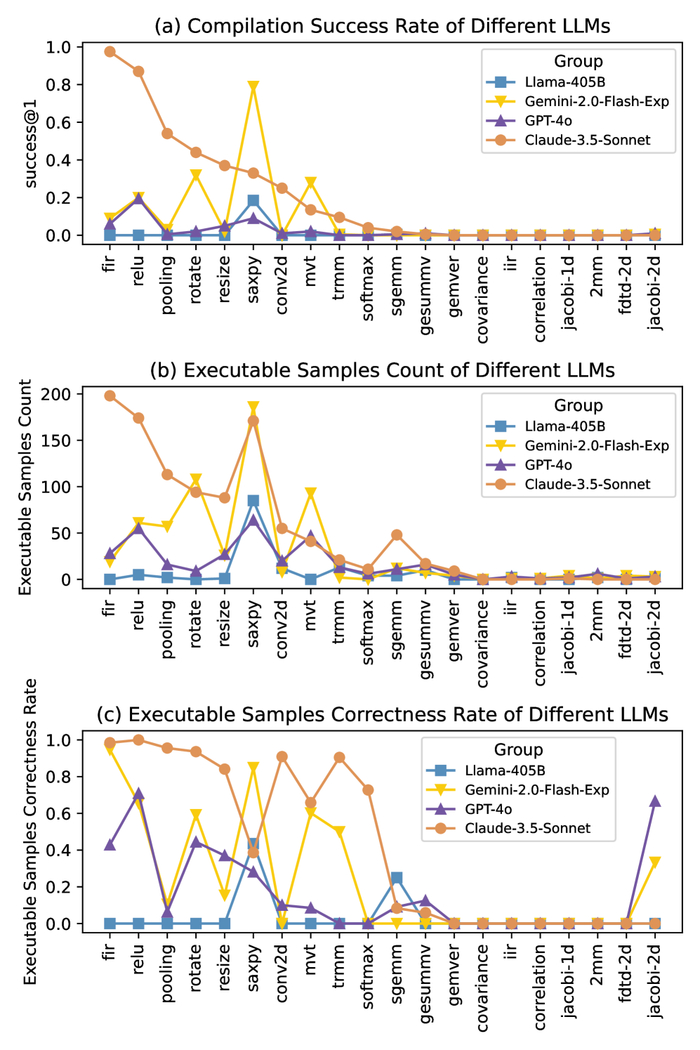
Анализ результатов, полученных для основных больших языковых моделей на наборе данных CompilerEval, выявляет общие тенденции и различия в их производительности.
Успешная реализация требует решения сложной задачи генерации целевого кода, оптимизированного для конкретных архитектур.
CompilerEval: Строгий Анализ Возможностей LLM
Для систематической оценки возможностей больших языковых моделей (LLM) в генерации ассемблерного кода разработана платформа CompilerEval, использующая специализированный набор данных CompilerEval Dataset. В рамках исследования была проведена оценка коэффициента успешной компиляции (Compilation Success Rate) для LLM, включая GPT-4o, Gemini-2.0, Claude-3.5 и Llama-3, на различных аппаратных архитектурах. Результаты демонстрируют зависимость эффективности от архитектуры и используемой модели.
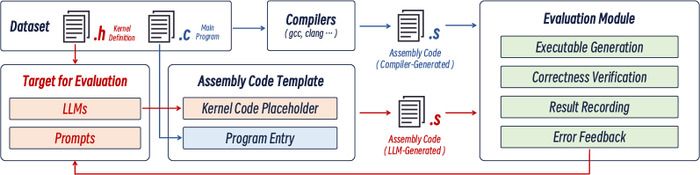
Представленная структура CompilerEval обеспечивает комплексную платформу для оценки и сравнения различных методов компиляции, основанных на больших языковых моделях.
Применение методов оптимизации запросов (Prompt Engineering) позволило улучшить показатели успешной компиляции. Так, для Claude-3.5-Sonnet наблюдалось увеличение на 7,5%, для GPT-4o с применением Chain-of-Thought – на 5%, а масштабирование Llama с Llama-70B до Llama-405B дало прирост в 1,55%.
Кроссплатформенность и Перспективы Будущего
Оценка продемонстрировала потенциал LLM для генерации кода для различных архитектур (x86, ARM, RISC-V), обеспечивая кроссплатформенную совместимость и автоматизацию разработки. Генерируемый код показал более высокие показатели корректности для ARM и RISC-V по сравнению с x86, что может быть связано с более стандартизированной природой этих архитектур.
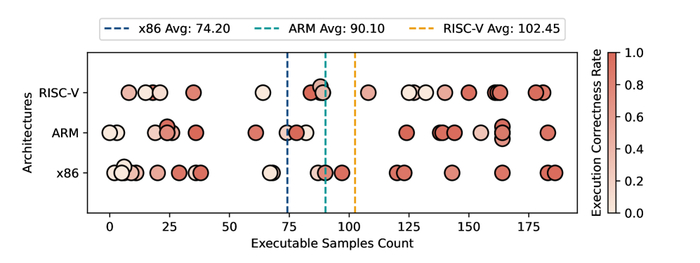
Оценка производительности Claude-3.5-Sonnet при генерации кросс-платформенного ассемблерного кода демонстрирует его возможности в данной области.
Дальнейшие исследования могут быть сосредоточены на оптимизации LLM и масштабировании для обработки сложных кодовых баз. Комбинация AI-управляемой компиляции с традиционными методами обещает будущее оптимизированной разработки. Каждая строка кода, созданная машиной, – это попытка расшифровать правила, лежащие в основе цифрового мира.
Исследование демонстрирует, что большие языковые модели могут выступать в роли компиляторов, генерируя ассемблерный код непосредственно из высокоуровневых инструкций. Однако, успешность компиляции остаётся переменной величиной, требующей дальнейшей оптимизации и проработки. Это напоминает о высказывании Грейс Хоппер: “Лучший способ предсказать будущее — это создать его.”. В контексте LaaC Framework и необходимости повышения точности и эффективности компиляции, данная фраза подчеркивает активную роль исследователей в формировании будущего компиляционных технологий. Вместо пассивного ожидания прогресса, необходимо создавать инструменты и методы, способные преодолеть текущие ограничения и обеспечить надежную кросс-платформенную поддержку.
Что дальше?
Представленная работа демонстрирует, что границы между языковыми моделями и компиляторами становятся всё более размытыми. Однако, воспринимать это как немедленную замену традиционным системам было бы наивно. Достигнутые результаты – скорее, намек на возможность, чем окончательное решение. Ключевым вызовом остаётся не только повышение процента успешной компиляции, но и обеспечение предсказуемости, эффективности генерируемого кода и, что немаловажно, его переносимости между различными платформами. Необходимо признать, что текущие модели, по сути, "угадывают" компиляцию, а не выполняют её на основе строгой логики.
Дальнейшие исследования должны быть направлены на разработку более надёжных методов оценки и верификации сгенерированного кода, а также на создание инструментов для "отладки" логики языковых моделей, используемых в качестве компиляторов. Интересным направлением представляется изучение возможности интеграции существующих компиляционных технологий с LLM, создавая гибридные системы, сочетающие в себе сильные стороны обоих подходов. Ведь хаос — не враг, а зеркало архитектуры, которое отражает скрытые связи.
В конечном счёте, успех этого направления зависит от способности выйти за рамки простого "перевода" кода и создать системы, способные к оптимизации и адаптации к специфическим требованиям целевой платформы. Это потребует не только улучшения алгоритмов обучения языковых моделей, но и глубокого понимания принципов работы компиляторов и архитектуры вычислительных систем.
Связаться с автором: linkedin.com/in/avetisyan