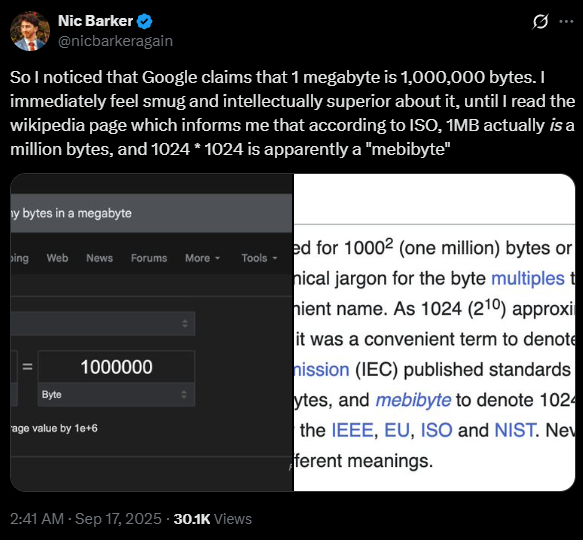
Для лиги лени: какое-то пособие для совсем отсталых
Ansible для детского сада в скольки то частях. Часть 1.Про все сразу.
Ansible для детского сада в скольки то частях. Часть 2. Костылируем жалкое подобие WSUS
Ansible для детского сада в скольки то частях. Часть 3 Безопасность
Для кого этот текст, и про что тут. Избыточно длинное введение
Ситуация «Я и Ansible» кому-то может показаться странной, кому-то обычной. Я его использую, много кто использует, и много кто использует гораздо лучше меня. И, при этом, много кто не использует, или не использует для каких-то очевидных для меня задач. Какие-то базовые вопросы ставят меня в тупик.
По абсолютно не понятным для меня причинам, Ansible, Terraform, прочие инструменты, время от времени записывают в «инструменты девопс». Это странно, потому что Ansible самый обычный инструмент, применяйте куда хотите. Хотя в русскоязычном сообществе почему то сменилась терминология, devops +-= linux system administrator, даже если у вас нет ни CI, ни CD, ни SDLC и тем более SSDLC, хотя бы на базовом уровне Microsoft SDL.
Поэтому я подумал, подумал, и решил написать одну, может две, статьи по теме, заодно в своей голове уложу какие-то вещи.
В ходе написания статьи выяснилось интересное, про Opensource в целом, как движение и .. образ мысли? Возможно, это абсолютно неправильная точка зрения, но .. GNU/Linux, точнее GNU как движение, точнее The Open Source Initiative / The Open Software Foundation, Inc. (OSF) , The Apache Software Foundation не умирают, но изменяются и трансформируются, и делают это каким-то путем.. Повелителя перемен. Ну хорошо хоть не Слаанеш, хотя местами чемпионы сразу двух.
Изначальное движение «кто-то пишет код, кто-то проверяет код» постепенно закончилось лет 10-15 назад. Критическими точками стали:
18 апреля 2016, с выходом статьи The Linux scheduler: a decade of wasted cores. Полный текст тут
9 декабря 2021, когда в Log4j выявили CVE-2021-44228. Не замеченную ни корпоративным миром, ни Apache Software Foundation с 2013 года. И это еще ничего, сейчас пошла волна вайб кодинга, там просто караул.
Причины "исхода" понятны – повсеместное внедрение тайм трекеров, систем управления, рост сложности кода, etc, не дают возможности массово заниматься «чем-то еще», и вклад в сообщество не монетизируется. Разработчики и команды забрасывают проекты, достаточно вспомнить RatticDB и Ralph, и последние движения везде.
В том числе поэтому страдает не только сам код, но и документация и сценарии к нему. Особенно статьи, написанные исключительно в стиле «как надо» и «как у меня получилось». Сценарии «как у меня не получилось и почему» оседают в глубинах форумов или (запрещенная в РФ социальная сеть) групп. Поэтому, иногда проще сделать самому «как не надо», сломать раз 10, написать «так точно не работает», и написать «как работает у меня и почему».
Мне почему-то проще так, через «сломай сам и напиши что сломал».
Важно: Вышло обновление 2.19, и вышло давно! :
Ansible Core 2.19 was officially released on July 21, 2025.
Important: The ansible-core 2.19/Ansible 12 release has made significant templating changes that might require you to update playbooks and roles. The templating changes enable reporting of numerous problematic behaviors that went undetected in previous releases, with wide-ranging positive effects on security, performance, and user experience. You should validate your content to ensure compatibility with these templating changes before upgrading to ansible-core 2.19 or Ansible 12. See the porting guide to understand where you may need to update your playbooks and roles. ROADMAP.
В чем плюс Microsoft Active Directory Domain Services (MS AD DS) ? Он просто работает. Я про это уже писал вот тут (SSSD или приключения Linux в домене Windows (MS AD)) и повторяться не нужно. И он документирован сотнями примеров и миллионами пользователей.
В чем минусы Ansible? Точнее, в чем минусы, если его не настраивать.
Первый минус.
Можно сказать, что очевидный минус в том, что это не pull система.
Хотя в документации и есть раздел Ansible-Pull, цитата:
You can invert the Ansible architecture so that nodes check in to a central location instead of you pushing configuration out to them. Ansible-Pull
То есть, каждый включенный в MS AD сервер «сам» ходит за новыми настройками, и «сам» их обновляет.
Для Ansible можно при первом проходе добавить в CRON
git pull && ansible-playbook
Но это не наш метод. И все равно, нужна система типа Netbox или хотя бы php ipam или хотя бы, если вы совсем немощный, GLPI - Gestionnaire libre de parc informatique.
GLPI, как оказалось, неплохой проект. Для целей именно ИТ в серверному сегменте, и управлению конфигурациями пригоден меньше, чем Netbox, но коллеги из РФ прикручивали к GLPI костыли, и кое как это ездило. Даже какое-то русское сообщество есть. Ralph, говорят, тоже неплох. Был.
Ralph 3 - Asset Management / CMDB
Github allegro /ralph
Discontinued
"Effective January 1, 2024, all development and maintenance activities associated with the Ralph project on Allegro's GitHub will be discontinued. This means that no further updates or modifications will be applied to the codebase. However, the current version of the code available in the repository will remain the property of the community, allowing individuals to continue contributing to and developing Ralph as they deem appropriate."
As Allegro, we continue to publish Ralph's source code and will maintain its development under a "Sources only" model, without guarantees. We believe this approach will be beneficial, allowing everyone to use and build upon the software. Our current goal is to modernize the software and ensure its long-term maintainability, and we're investing into it in 2025.
However, we are not operating under a contribution-based model. While we welcome discussions, we do not guarantee responses to issues or support for pull requests. If you require commercial support, please visit http://ralph.discourse.group.
We sincerely appreciate all past contributions that have shaped Ralph into the powerful tool it is today, and encourage the community to continue using it.
README.md
IT Asset Management нужен, но это система управления, а не система настройки. Хотя, может и к ней есть какой-то готовый модуль выгрузок, или его можно написать, именно как модуль.
Вторая минус, с которым я, может быть, попробую разобраться, хотя меня до вчера она не волновала, это AAA, точнее какую учетную запись использует Ansible, и как он это делает. От рута все запускать, конечно, легко. Один рут везде, один пароль. Удобно.
Второй с половиной минус, это ограничения по исполнению для разных типов учетных записей и прочего sudoers .
Вопрос использования Ansible, скорее, относится к координации отделов. Если отдел ИТ един, и при создании очередной виртуальной машины, в облаке или на земле, VM или сервис добавляется в Ansible, или изначально VM и физика добавлены, или есть автоматическое обновление, то проблемы нет.
Но ситуация «забыли добавить» и бесконтрольных Windows машин касается. Если Windows машину в домен не добавить, то волшебным образом она там не появится, и на локальном WSUS отмечаться не будет.
Отсутствие контроля плохо что так, что эдак.
Что дает еще одно направление для инвентаризации, про которое я как-то раньше не думал, но про это напишу статью - Инвентаризация инфраструктуры и сети. Пометки для начинающих. Черновик заведен, дальше как время будет получится.
После всех тестов у меня остался:
Кое-как настроенный Ansible
Никак толком не настроенный Linux с SSSD
Git, просто Git. Причем в контейнере
Ansible AWX у меня не заработал. Не очень и хотелось. Можно было поиграть в семафор.
The last release of this repository was released on Jul 2, 2024. Releases of this project are now paused during a large scale refactoring.
Event-Driven Ansible has been a huge success, but we’ve noticed the same limitations with our existing architecture when trying to combine it with this new system. We need Jobs to be able to report their status in different ways and in different places. We need credentials and projects to be usable in a secure way by this system. Inventory management for Ansible today isn’t just about Servers or Containers, they are about Cloud and Service APIs as well as Embedded and Edge capabilities.
Upcoming Changes to the AWX Project
Судя по тестовой VM, для связки Nexus + Gitlab + Ansible – 4 Гб на одной VM не достаточно.
30% памяти забирает Java, 20% - Ruby, остальное расходится туда-сюда.
5 Гб минимум для тестов в моей конфигурации. Это не самая большая сложность, когда на нормальном ноутбуке уже 64 Гб памяти (на топовых уже по 96 Гб оперативной памяти).
Проверяем легаси конфиг Ansible
Делаем: ansible --version
Получаем:
ansible --version == ansible [core 2.18.7]; config file = /etc/ansible/ansible.cfg
Делаем: ansible-inventory --list -y
Получаем, цитата:
all:
children:
proxmox:
hosts:
192.168.1111.1111:
ansible_python_interpreter: /usr/bin/python3
servers:
hosts:
server1:
ansible_host: 192.168.1111.2222
ansible_port: 2424
ansible_python_interpreter: /usr/bin/python3
(я в курсе, что IP 192.168.1111.1111 принципиально неправильный, но мне лень как-то иначе переписывать данные реального стенда)
Посмотрим что там:
nano /srv/ansible/hosts.ini
Как оказалось, /srv/ansible/hosts.ini – это какой-то недоделанный файл из какой-то старой инструкции. Не нужен
nano /etc/ansible/hosts
Получаем тот же конфиг, что выше, но в формате конфига:
[servers]
server1 ansible_host=192.168.1111.1111
[servers:vars]
ansible_port=2424
[proxmox]
192.168.1111.2222
[all:vars]
ansible_python_interpreter=/usr/bin/python3
Не знаю, можно ли назвать это вообще конфигом, или минимальным конфигом для работ, но мне хватает. Точно так же, я не уверен, что надо записывать сервера по IP, а не по DNS имени, или не как-то иначе. Точнее, уверен что лучше по имени, но можно и так.
2424 – это у меня SSH переставлен, в /etc/ssh/sshd_config. Потому что на 22 порту этой VM живет gitlab в docker. Можно было наоборот.
В интернетах пишут то, что мне нравится, то есть: используйте FQDN. цитата:
I tend to disregard the commonly accepted best practice of using short names for hosts, and use FQDNs instead. In my opinion, it has many advantages.
It makes it impossible for host names and group names to collide.
Creating an additional variable to carry the host's expected FQDN becomes unnecessary.
It is immediately obvious which (actual) host caused some failure.
Ansible naming conventions
Что имеем перед началом движения:
не обновленный Ansible с простейшей конфигурацией.
Еще раз напоминаю, что в 2.19 (у меня ansible [core 2.18.7] поведение поменялось.
Обновиться в лабе просто так можно, но нельзя, через:
pip install --upgrade ansible-core
Можно выстрелить себе в ногу, потому что:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
ansible 11.8.0 requires ansible-core~=2.18.7, but you have ansible-core 2.19.2 which is incompatible.
Successfully installed ansible-core-2.19.2
Придется обновлять целиком:
python3 -m pip install --upgrade --user ansible
Found existing installation: ansible 11.8.0 ; Successfully installed ansible-12.0.0
Такое, конечно, только в лабе и можно делать, без бекапа, без плана отката, вообще без ничего.
Переходим к фактам, просто потому что они мне были нужны
Самая простая команда для сбора фактов -
ansible all -m setup
Читается просто.
Ansible – понятно.
All – группа по умолчанию
Дальше интересно, потому что «-m» описан в Ansible ad hoc commands, как
$ ansible [pattern] -m [module] -a "[module options]"
Там же описана параллельное исполнение команд, цитата:
By default, Ansible uses only five simultaneous processes. If you have more hosts than the value set for the fork count, it can increase the time it takes for Ansible to communicate with the hosts. To reboot the [atlanta] servers with 10 parallel forks
Кто подскажет, почему я тупой, и нашел перечень в выводе man ansible
и не нашел какой-то подробной статьи в интернетах?
-m == module; в том числе -m ansible.builtin.setup , что равно -m setup
-a == command
-u username == user
--ask-become-pass ; -K; --ask-pass – запрос пароля;
--check == Running playbooks in check mode
-i; --inventory == файл с перечнем хостов
-e; ‐‐extra-vars
-l; ‐‐limit
man ansible
usage: ansible [-h] [--version] [-v] [-b] [--become-method BECOME_METHOD] [--become-user BECOME_USER] [-K | --become-password-file BECOME_PASSWORD_FILE]
[-i INVENTORY] [--list-hosts] [-l SUBSET] [--flush-cache] [-P POLL_INTERVAL] [-B SECONDS] [-o] [-t TREE] [--private-key PRIVATE_KEY_FILE]
[-u REMOTE_USER] [-c CONNECTION] [-T TIMEOUT] [--ssh-common-args SSH_COMMON_ARGS] [--sftp-extra-args SFTP_EXTRA_ARGS]
[--scp-extra-args SCP_EXTRA_ARGS] [--ssh-extra-args SSH_EXTRA_ARGS] [-k | --connection-password-file CONNECTION_PASSWORD_FILE] [-C] [-D]
[-e EXTRA_VARS] [--vault-id VAULT_IDS] [-J | --vault-password-file VAULT_PASSWORD_FILES] [-f FORKS] [-M MODULE_PATH]
[--playbook-dir BASEDIR] [--task-timeout TASK_TIMEOUT] [-a MODULE_ARGS] [-m MODULE_NAME]
Проблема такого опроса лишь в том, что это состояние «на сейчас, для всех». Поэтому, если у вас удаленный сервер выключен, или не настроен, или что-то еще, то вы получите, цитата
server1 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh
И еще, для моего сценария «ничего не настроено», нужно делать не
ansible all -m setup
а
ansible all -m setup --ask-pass
Или индивидуально для группы серверов:
ansible proxmox -m setup --ask-pass
не говоря про остальное написанное в прошлых текстах:
ansible proxmox -m command -a "uptime" --ask-pass
ansible proxmox -m command -a "pveversion" --ask-pass
ansible proxmox -m command -a "echo ' Hello World '" --ask-pass
И тогда, в ответ на
ansible all -m setup --ask-pass
вы получите не только
(IP) | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
Но и огромную xml выгрузку по массе параметров.
Дальше нужно переходить к использованию фильтров
вместо ansible all -m setup --ask-pass
запросить ansible all -m setup -a "filter=ansible_cmdline" --ask-pass
и, кроме использования фильтров, переходить на использование групп, где proxmox – это группа, описанная в /etc/ansible/hosts, и строка будет выглядеть как:
ansible proxmox -m setup --ask-pass -a "filter=ansible_cmdline" --ask-pass
Или придется вспоминать базовейший баш, и выгрузить все полученное в файл,
ansible proxmox -m setup --ask-pass > ansible_out_01.txt
Внутри выгруженного файла посмотреть список того, что можно получать в фильтрах, например:
ansible_all_ipv4_addresses
ansible_default_ipv4
ansible_uptime_seconds
ansible_kernel
И получать именно их:
ansible proxmox -m setup -a "filter=ansible_uptime_seconds" --ask-pass
С выводом:
"ansible_facts": {
"ansible_uptime_seconds": 3416
Переходим к первому плейбуку
nano /home/user/uptime_report.yml
Плейбук целиком утащен из интернета или даже написан AI: цитата:
---
- name: Get and display system uptimes
hosts: all
gather_facts: true # Ensure facts are gathered to get ansible_uptime_seconds
tasks:
- name: Display uptime for each host
ansible.builtin.debug:
msg:
Hostname: {{ inventory_hostname }}
Uptime: {{ (ansible_uptime_seconds / 86400) | int }} days,
{{ ((ansible_uptime_seconds % 86400) / 3600) | int }} hours,
{{ (((ansible_uptime_seconds % 86400) % 3600) / 60) | int }} minutes,
{{ (((ansible_uptime_seconds % 86400) % 3600) % 60) | int }} seconds
when: ansible_uptime_seconds is defined
Выполним что получилось. Без всякой фильтрации хостов и без ничего.
ansible-playbook uptime_report.yml --ask-pass --user root
Получим 1 [ERROR]: Task failed: Failed to connect to the host via ssh:, и получим 1 ОК.
Ansible playbook для первой группы хостов
На следующем этапе первым делом надо разобраться вот с чем.
Команда:
ansible-playbook -i /path/to/your/hosts_file.ini your_playbook.yml
позволяет работать со списком хостов и групп хостов в hosts_file.ini
по умолчанию это /etc/ansible/hosts
Очень хочется сделать по образцу:
Вместо: ansible proxmox -m setup -a "filter=ansible_uptime_seconds" --ask-pass
сделать:
ansible-playbook proxmox uptime_report.yml --ask-pass --user root
man ansible-playbook
NAME
ansible-playbook - Runs Ansible playbooks, executing the defined tasks on the targeted hosts.
SYNOPSIS
usage: ansible-playbook [-h] [--version] [-v] [--private-key PRIVATE_KEY_FILE]
[-u REMOTE_USER] [-c CONNECTION] [-T TIMEOUT] [--ssh-common-args SSH_COMMON_ARGS] [--sftp-extra-args SFTP_EXTRA_ARGS] [--scp-extra-args
SCP_EXTRA_ARGS] [--ssh-extra-args SSH_EXTRA_ARGS] [-k | --connection-password-file CONNECTION_PASSWORD_FILE] [--force-handlers]
[--flush-cache] [-b] [--become-method BECOME_METHOD] [--become-user BECOME_USER] [-K | --become-password-file BECOME_PASSWORD_FILE] [-t TAGS] [--skip-tags SKIP_TAGS] [-C] [-D] [-i INVENTORY] [--list-hosts] [-l SUBSET] [-e EXTRA_VARS] [--vault-id VAULT_IDS] [--ask-vault-pass‐
word | --vault-password-file VAULT_PASSWORD_FILES] [-f FORKS] [-M MODULE_PATH] [--syntax-check] [--list-tasks] [--list-tags] [--step]
[--start-at-task START_AT_TASK] playbook [playbook ...]
Значит, что остаётся делать?
Остается читать: Ioannis Moustakis Ansible Inventory (есть русский перевод от slurm: Изучаем Ansible Inventory: основы и примеры использования)
Делаем: ansible-playbook uptime_report.yml --ask-pass --user root --inventory proxmox
И ничего подобного, ТАК НЕ РАБОТАЕТ
казалось бы, очевидный лично для меня вариант, когда команда исполняется для какой-то выборки из группы хостов в файле «по умолчанию».
Ничего подобного. Будьте добры делать, как положено:
ansible-playbook uptime_report.yml --ask-pass --user root --inventory /etc/ansible/hosts --limit “proxmox”
То есть, конечно, можно и покороче:
ansible-playbook uptime_report.yml --ask-pass --user root --limit “proxmox”
но через limit, если вы хотите «чтобы бралось по умолчанию, но не все».
Лично мне вот это было совершенно не очевидным моментом, что это делается именно так.
Проблема роста – когда ты имеешь развитую инфраструктуру, где все это давно используется, и закопано в наслоениях легаси, можно сделать по образцу и, скорее всего, будет работать. Когда ты пытаешься разобраться, как и почему сделано вот так, это уже совсем другое.
Ну да ладно.
Скопирую конфиг себе и буду пробовать
cp /etc/ansible/hosts /home/user/1st_hosts.ini
Удалю лишнее, оставлю только
[proxmox]
192.168.1111.2222
[all:vars]
ansible_python_interpreter=/usr/bin/python3
И сделаю
ansible-playbook uptime_report.yml --ask-pass --user root --inventory /home/user/1st_hosts.ini
И все отлично, и все работает.
Система как система, ничем не хуже другой. Первый час сложно, ничего не понятно. Потом попроще.
Ioannis Moustakis Ansible Inventory (есть русский перевод от slurm: Изучаем Ansible Inventory: основы и примеры использования)
@editors, мне бы теги Ansible и CMDB, пожалуйста! Не работает их добавление у меня, ничего не могу с этим сделать!