
Зеленоглазая

Показать полностью
1

Обложка для клипа за 1000р
Идеи не падают с неба - они складываются из того, что нас окружает. Кто работал на фрилансе или шабашил наверняка сталкивался с проблемами продать подороже (купить подешевле).
На своём канале я реализую свои идеи. Порой хочется создать что-то новое. Так что в какой-то момент пазл сложился: я собрал в один трек свой опыт общения с «клиентскими хотелками», их требования, и привычку выражать мысли в рифме - получился черновой набросок песни:
Результат на YouTube: https://youtu.be/gyK0EooEaFM?si=NLBhB3hWrA-G1462
Результат в TG: https://t.me/photoudzen/1949
Под него сложилась картинка клипа. ChatGPT помог обработать текст под рэп. Начались 15 раундов шлифовки: подгонял ритм, искал точнее рифмы, ужимал длинные формулировки, менял порядок строк, пока куплеты и припев не «сели» в бит без спотыкания.
Перед генерацией вокала и аранжировки открыл документацию Riffusion (режим Compose) - чтобы правильно разметить текст на секции (Intro / Verse / Pre-Chorus / Chorus / Bridge / Outro), задать тон, и не бороться с инструментом вслепую. Принцип простой и вечный: не игнорируйте документацию - инструкции экономят часы проб и ошибок и дают предсказуемый результат.
Скриншот AI Riffusion
9 неудачных музыкальных версий привели в итоге к попаданию в цель. Окончательный итог правил в Audition (небольшой EQ, де-эссер, лёгкая динамика. После хирургии трек стал чище и музыкальнее.
Скриншот окна программы Audition
Плей - диван - закрытые глаза. Я слушал готовый трек и ловил картинку, которая всплывает первой: фактуры, ритм монтажа, гэги. Этот «слуховой сториборд» зафиксировал тезисно, а уже потом перешёл к гриду референсов и генерации.
В ComfyUI написал промты, с помощью Checkpoint Flux Dev Krea сгенерировал изображения сцен. Из удачных кадров собрал «палитру мира» клипа.
ComfyUI с Checkpoint Flux Dev Krea
Veo 3 (платный аккаунт). Часть сцен я подавал чисто текстом (без картинок) - и это иногда давало результат лучше: особенно там, где важен темп движения и «киношные» клише.

Veo 3 - этапы генерации
Для сборки я выбрал CapCut (desktop) - без сложной покраски и тяжелых FX он работает быстрее. Разложил таймлайн: базовые нарезки, темповые резы под бас/снейр, текстовые плашки, пару простых переходов. Важнее было ритм и читабельность шуток, а не фейрверки визуальных трюков.
CapCut (desktop) - сборка клипа
На просмотре не всегда внешность главного героя совпадала. Уравнять образы помог Viso Master. Почему не DeepFaceLab? Качество у DFL выше, но требовало бы ~6 часов тренировки модели - а я ставил скорость/качество 50/50. С Viso Master получил достойный баланс.
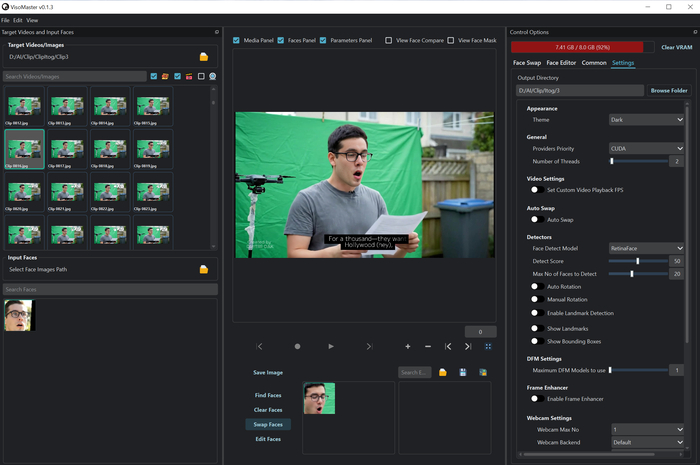
Viso Master - замена лица
Реальность вмешалась: не везде детектило лицо, плюс на 8 ГБ VRAM тяжело тянуть улучшайзеры - ноут грелся, софт падал. Решение: разбил ролик 2:07 на 3836 кадров, прогнал кадрово нужные фрагменты через Viso Master и собрал обратно:
Разбитие на кадры - бесплатная Jpg Converter (узко заточенная, но делает своё дело легко).
Сборка назад — через Blender 3D (как видеоредактор он удобен для таких задач и даёт контроль по частоте кадров/кодекам).
После финальной склейки вернулся к смыслу. В After Effects замазал (масками) сообщения на телефоне в начале клипа - перевёл с английского на русский, добавил слегка агрессивное движение текста, чтобы подчеркнуть «снисходительность» заказчика. Пара трекингов и реплики «жалят» ровно как в треке:
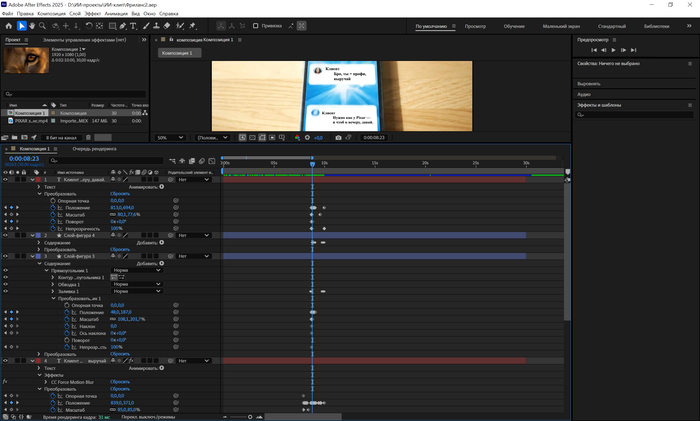
After Effects - замена сообщений в телефоне
Финальный прогон через Topaz Video AI: апскейл до 4K, умеренное повышение деталей на средних планах, аккуратное подавление шума на «тёмных» кадрах. Важно не пережать — язык пародии не любит стеклянные лица.
Для кликабельности сделал две обложки - горизонтальную (16:9) и вертикальную (9:16). Генеративный черновик собрал в ChatGPT, затем довёл композицию и типографику в Photoshop: крупный заголовок, контрастные силуэты, ясный фокус на «болезни фриланса». Тот же сет использовал для превью в Shorts/Reels.

Photoshop - создание обложки
Спасибо за внимание! Посмотрев клип, я думаю он вызвал у вас улыбку😊
Если интересны такие темы как AI, 2D или 3D графика - можете заходить на мой YouTube и TG.
Здравствуйте, дорогие Пикабушники и Пикабушницы!
Темой "пятничного моё" будет вышеупомянутая AI генерация. И генерировать будем в ComfyUI.

ComfyUI — это современный и модульный графический интерфейс для работы с нейросетями Stable Diffusion, разработанный для максимально простого и гибкого взаимодействия с моделью. Это своего рода узловой интерфейс (node-based GUI), в котором пользователи могут визуально создавать сложные операции по обработке изображений или их генерации с помощью нейронных сетей.
Узловой подход (Node-based UI): Пользователи работают с блоками (или узлами), которые представляют различные функции. Эти узлы можно соединять между собой, создавая сложные графы для обработки изображений. Узлы могут включать:
Настройку параметров генерации.
Применение различных фильтров и эффектов.
Указание моделей и разверток.
Такой подход намного удобнее классических интерфейсов, где приходится вручную прописывать параметры в строках команд.
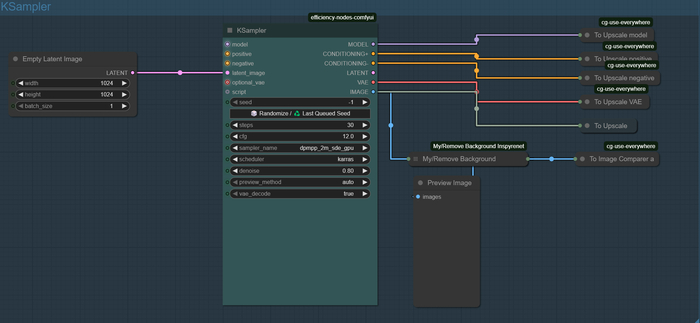
Ноды, мои ноды
2. Поддержка Stable Diffusion: ComfyUI разработан специально для взаимодействия с моделями Stable Diffusion, включая генерацию изображений, модификацию и эксплуатацию возможностей обработки.
3. Гибкость и кастомизация: Система создана для опытных пользователей, но в то же время позволяет комфортно новичкам собирать нужный процесс благодаря визуальным элементам. Имеется возможность добавлять свои собственные узлы или использовать сторонние расширения.
4. Интерактивная визуализация: Вы напрямую видите, как данные передаются между узлами и какие изменения на выходе дают те или иные параметры. Это полезно для дебага и улучшения понимания работы с моделью.
5. Поддержка сложных сценариев работы: В ComfyUI можно совмещать множество операций генерации и обработки в рамках одной цепочки:
Инпут (текстовый запрос, изображение).
Работа с различными моделями.
Добавление эффектов (например, инверсии, upscale или фильтрации).
Вывод готового изображения.
6. Интеграции с популярными библиотеками: ComfyUI поддерживает интеграцию с различными моделями и компонентами, используемыми средствами генерации изображений. Она часто обновляется, поддерживая последние версии архива моделей Stable Diffusion.
А пример создания персонажа под ключ в моем новом видео:
А потом приглашаю в комментарии - задавайте вопросы по видео и просто по юнити!
Приятного просмотра!
А есть у кого воркфлоу для удаления одежды? Есть типа куча воркфлоу и пони для создания обнаженки, а для раздевания за 2 дня поиска не нашел никаких результатов.
Не мог обойти стороной творение с таким-то котофеем на приложенной к нему картинке.

Обложка альбома Hircine 2023 Luna & Light
Hircine 2023 Luna & The Light. Второй альбом канадского синт-проекта.
Очень приятная тёплая работа, местами, правда, меланхоличная и даже депрессивная, но в целом очень мягкая, добрая и атмосферная. По духу альбом близок к комфи, но по звучанию не такой топорный, а более объёмный и разнообразный, так как жанровая составляющая варьируется от лесного эмбиента и данджен синта до нью эйджа и неофолка.
Автор (мне почему-то кажется, что за названием Hircine стоит какая-то дама) альбома рекомендует при прослушивании поглаживать своего кошича и вообще уделить побольше внимания четверногому другу. Кстати, часть денег, собранных с покупки цифрового релиза, идёт на помощь местной некоммерческой организации Regina Cat Rescue, занимающейся спасением брошеных домашних животных.
Душевной вам котоламповости!
А послушать можно здесь: https://vk.com/music?z=audio_playlist-40559075_84994072&...
Для домашнего использования написал ноду Image Fit Calculator для калькуляции параметров resize & padding.
Среди модулей Comfy UI чего только нет, но вот нормальной ноды с нужной арифметикой не нашел, сделал свой. Делал умышленно только арифметику, которая применяется на вход других модулей, таким образом получилось и просто и гибко.
Боль, которую я хотел полечить - при использовании референсной картинки, например, для Depth ее пропорции криво ложатся в пропорции рабочего latent и получается ерунда. Можно сделать простой padding, есть ноды, но он тогда дает дурацкие колоны и полы из-за сплошных заливок. А значит padding нужно делать с дешевым outpainting, тогда края размываются чепухой и все выходит красиво, но нужно корректно выставить размеры и положение референса, желательно не парясь о пропорциях картинки и холста.
Вот как-то так выглядит демо (для наглядности делал минимальный набор):

На странице проекта в описании так же есть анимация, возможно так будет понятнее.
Устанавливать можно через менеджер, ну или через url или клоном проекта руками.
Делюсь, мало ли кому нужно.
PS. схему с дешевым outpainting выложу отдельно позднее.
🎦 СМОТРЕТЬ НА YOUTUBE
🎦 СМОТРЕТЬ НА RUTUBE
💥 Flux Upscaler "DRAGON SCALE" - это плиточный upscale на пользовательских узлах имитирующих ControlNet Tile для Flux.
💥 Очень интересное решение позволяющие заменить controlnet tile на современных моделях. Разбиение на плитки позволяет экономить VRAM и описание каждой плитки по отдельности позволяет повысить точность upscale.
✅ Upscaler очень гибкий и имеет много регулировок, позволяющий получить высокое качество на flux upscale.
📝 МЕНЮ
00:00 - Обзор Flux Upscaler - Flux Dragon Scale
02:00 - Установка comfyui
02:37 - Установка моделей и схемы Flux Dragon Scale
05:21 - Схема comfyui - flux dragon scale
15:46 - Загрузка моделей Florence
В этом видео вы познакомитесь с stable diffusion 3.5, sd3.5 Large, sd3.5 Large Turbo.
Схема comfyui для stable diffusion 3.5 с поддержкой LLM моделей gemini и miaoshouai для анализа изображений.
Модели sd 3.5 fp16, fp8, gguf. Модели gguf позволяют снизить потребление vram до 11 Gb, что позволит запустить sd3.5 на rtx 3060. Вы узнаете как установить и настроить comfyui.
МЕНЮ
05:57 - Установка comfyui
10:41 - Настройка схемы stable diffusion 3.5
11:58 - Разбор схемы sd3.5
16:07 - llm miaoshouai
18:40 - LLM gemini
23:14 - Примеры генераций sd 35
👁Смотреть на YouTube (https://youtu.be/FP5gPgLuZu8?si=f7hhN_8ls_IP1PUB)
👁Смотреть на Rutube (https://rutube.ru/video/2a7d5ac07e7d9f9435ebe2a977c6c3fb/)




