Здравствуй, уважаемый читатель! Спасибо, что заходишь ко мне на канал и изучаешь SQL со мной!
Недавно нашёл в интернете достаточно простую задачу с собеседования по SQL, в которой нужно было составить запрос к таблицам. Ссылку на источник размещу ниже. В своём Телеграм канале, где мы решаем разные задачи с собеседований и разбираем практические ситуации, я предложил всем поучаствовать в её решении. Надеюсь, тебе будет тоже интересно попробовать её решить. Ниже описание задачи.
В базе данных есть таблица анализов Analysis, имеющая следующие столбцы: an_id — ID анализа; an_name — название анализа; an_price — цена анализа; an_group — группа анализов. Есть, также, таблица заказов Orders: ord_id — ID заказа; ord_datetime — дата и время заказа; ord_an — ID анализа. Необходимо вывести название и цену для всех анализов, которые продавались 5 февраля 2020 и всю следующую неделю.
Тут сделай паузу и попробуй сначала сам решить задачу.
Итак, надеюсь, ты делал паузу и составил SQL-запрос. Далее будем решать вместе.
Напомню, что нужно было вывести список анализов и их цену, которые продавались 05.02.2022 и всю следующую неделю.
Первым решением напрашивается соединение таблицы анализов и таблицы продаж с применением условия на период. Кстати, именно это и указано в качестве ответа на задачу.
На самом деле, из-за того, что один анализ за выбираемый интервал времени мог быть продан сколько угодно раз (один и тот же анализ мог быть продан хоть тысячу раз и больше) заместо соединения таблицы анализов с таблицей заказов, я бы предложил использование EXISTS:
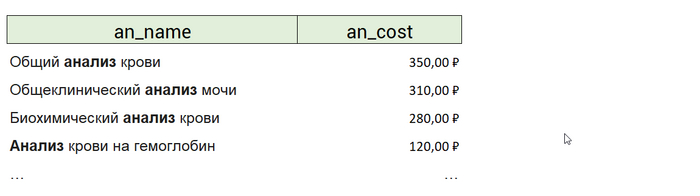
select a.an_name, a.an_cost from analysis a where exists (select 1 from orders where ord_an = a.an_id and ord_datetime between to_date('05.02.2022', 'dd.mm.yyyy') and to_date('05.02.2022', 'dd.mm.yyyy') + 7)
Благодаря тому, что мы не джоинили анализы с их заказами, в результирующей таблице анализы не замножатся по количеству присоединившихся к ним заказов. То есть в результате мы получим:
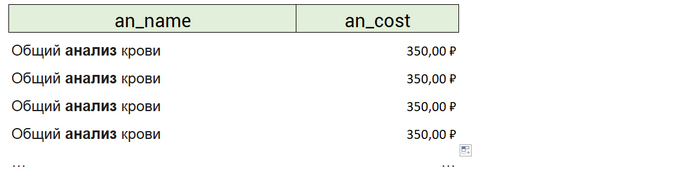
В примере, что я нашёл в интернете (ссылка ниже), помимо названий анализов и их стоимостей, выведен ещё и столбец с датами заказов. По условиям задачи вывод этого столбца не запрашивался. Не требовался вывод никакой информации о заказах/продажах. Поэтому и надобности в соединении я не усмотрел. Наоборот, это и потенциально замножит вывод анализов, которые покупали в запрашиваемый период, и прибавит лишнюю работу СУБД.
Поддержи статью лайком или подпиской!
Ещё больше интересных практических задач по SQL и задач с собеседований в нашем Телеграмм-канале и в интернете :)