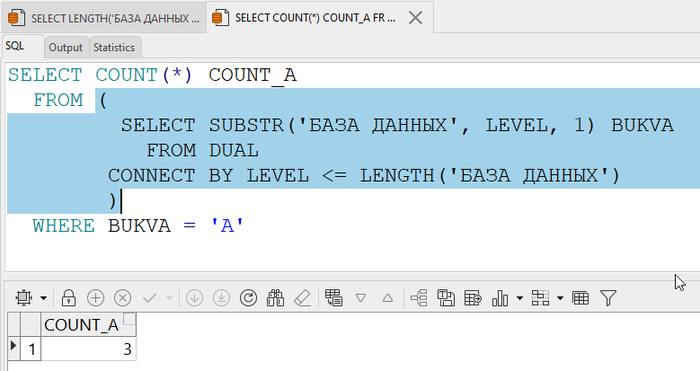
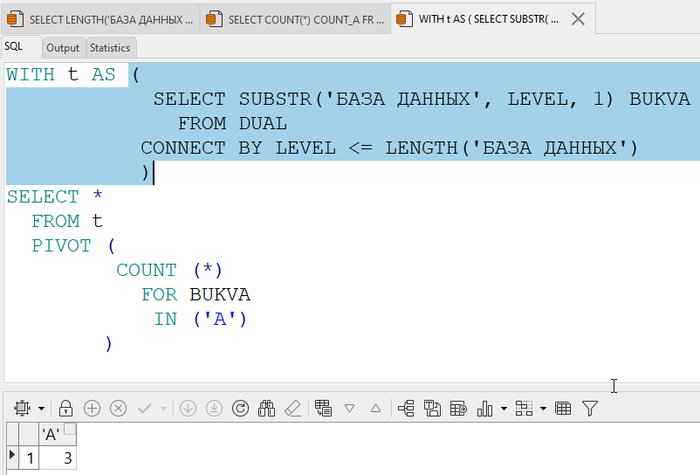
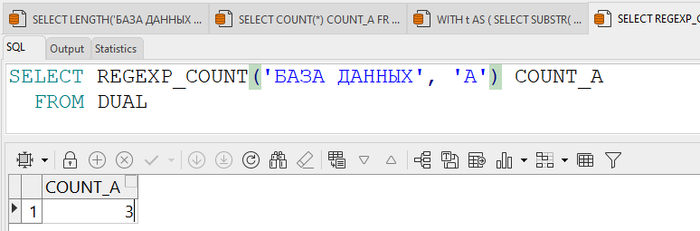
Когда мы видим AVG, кажется, всё просто:
Возьми все значения и найди среднее арифметическое.
Но на практике AVG часто ведёт себя не так, как ты ожидаешь — и это причина десятков аналитических факапов в отчётах.
А пока подписывайся на мой каналНа связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
AVG() - агрегатная функция. Она считает среднее значение по всем строкам, которые попали в выборку после фильтрации WHERE
SELECT AVG(column_name)
FROM table_name
WHERE condition;
| id | salary |
| -- | ------ |
| 1 | 1000 |
| 2 | 2000 |
| 3 | NULL |
| 4 | 3000 |
SELECT AVG(salary) FROM employees;
❗ Почему не (1000 + 2000 + 0 + 3000) / 4 = 1500?
Потому что AVG игнорирует NULL.
Он считает (1000 + 2000 + 3000) / 3.
Если тебе нужно учесть “отсутствие зарплаты” как ноль —
надо явно это сказать базе:
SELECT AVG(COALESCE(salary, 0)) FROM employees;
Где используется AVG
AVG() — базовый инструмент в аналитике:
📈 средний чек (AVG(order_amount))
💰 средняя зарплата по отделу
🕒 среднее время выполнения заказа
⭐ средний рейтинг продукта
Но это только верхушка айсберга.
Ниже — интересные кейсы, где AVG используется неочевидно, но мощно 👇
Обычный AVG считает всё одинаково,
но в реальном мире “вес” данных может быть разный.
Пример — средняя оценка курса:
| user_id | rating | reviews |
| ------- | ------ | ------- |
| 1 | 5 | 1 |
| 2 | 4 | 20 |
Если ты просто возьмёшь AVG(rating) → 4.5
Но по факту второй пользователь оставил 20 отзывов, его мнение должно весить больше:
SELECT SUM(rating * reviews) / SUM(reviews) AS weighted_avg
FROM ratings;
Вот это уже взвешенное среднее, и результат будет ближе к 4.
AVG не коммутативен в агрегациях
| group | value |
| ----- | ----- |
| A | 10 |
| A | 20 |
| B | 100 |
| B | 100 |
| B | 100 |
SELECT AVG(avg_val) FROM (
SELECT group, AVG(value) AS avg_val
FROM t GROUP BY group
) s;
Результат будет → 57.5
А реальное среднее по всей таблице = 86.
Почему?
Потому что при втором AVG каждая группа имеет одинаковый “вес”,
а не количество строк. Это типичный аналитический капкан.
AVG в окнах (window functions)
AVG() можно использовать по “скользящему окну”, чтобы считать динамику:
SELECT
date,
AVG(price) OVER (ORDER BY date ROWS 6 PRECEDING) AS moving_avg_7d
FROM stock_prices;
👉 Это 7-дневное скользящее среднее — классика анализа временных рядов, трейдинга и предсказания трендов.
Среднее как критерий “нормальности”
В аналитике AVG часто используют вместе со STDDEV:
STDDEV (Standard Deviation) — стандартное отклонение (среднеквадратичное отклонение). Это статистическая мера разброса данных относительно их среднего значения в определённом периоде.
SELECT *
FROM purchases
WHERE amount > AVG(amount) + 3 * STDDEV(amount);
Так находят аномально большие значения — подозрительные платежи, мошеннические операции и т.д.
AVG по датам — это тоже работает
Мало кто знает, что AVG() можно применять даже к датам:
SELECT AVG(order_date)::date FROM orders;
PostgreSQL переведёт даты во внутренние числа и вычислит “среднюю дату” —
по сути, середину временного диапазона.
Это удобно, если хочешь понять, когда чаще всего происходили события.
AVG и производительность
AVG() всегда вычисляется через SUM и COUNT,
поэтому если ты делаешь:
SELECT COUNT(*), SUM(amount), AVG(amount)
— оптимизатор посчитает всё за один проход по данным.
Но если AVG в отдельном запросе — будет второй проход.
Мелочь, а при миллионах строк чувствуется.
Мой канал На связи: SQL ждет тебя, если ты тоже хочешь познакомиться с базовым языком для аналитики данных.
Подписывайся!