
Закреплено

Искусственный интеллект
5 063 поста
•
11 479 подписчиков
0 просмотренных постов скрыто


Qwen выпустили новую «думающую» модель QwQ-32B
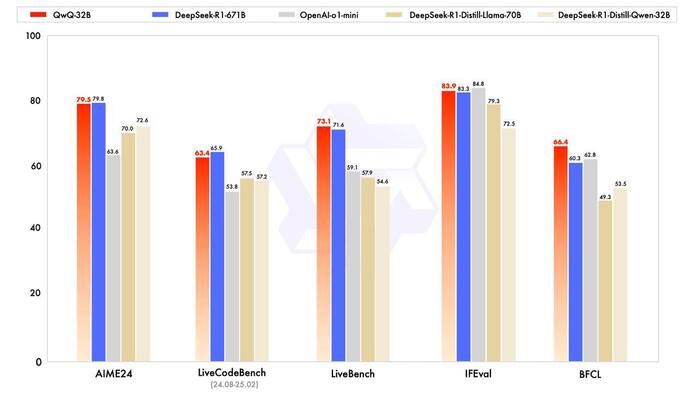
Qwen выпустили новую «думающую» модель QwQ-32B, которая обходит топовые нейросети в некоторых бенчмарках. И она абсолютно бесплатная.
Модель пишет код за несколько секунд, решает сложнейшие задачи по математике и понимает огромный контекст в 131 тыс. токенов — этого хватит, чтобы загрузить в бота целую диссертацию и задавать по ней вопросы.
Тестируем в чат-боте Qwen. Надо выбрать QwQ-32B-Preview в списке моделей.
Показать полностью

ИИ
Вот смотрю на рекламу защиты от мошенников и жду, когда мой Тинькофф начнёт блокировать звонки Сбера с формулировкой "осторожно, возможно вам звонят мошенники".

Озвучка диалогов с помощью нейросети FishSpeech

Озвучка диалогов из текста может сильно упростить и ускорить работу во многих ситуациях: подкасты, аудиокниги, обучающие материалы, рекламные ролики, создание игр, reels и даже фильмов.
Часто записать аудио крайне трудно: нет доступа к микрофону, шумная обстановка или ограниченные временные рамки. Или просто лень.
Поэтому сегодня на обзоре нейросеть Fishspeech, которая реалистично озвучит текст, сохраняя интонации и эмоциональную окраску. Так ещё можно добавлять свои голоса или использовать уже готовые 50+ голосов от сообщества Нейро-Софт. Вообще сказка! Давайте к обзору.
❯ Основные особенности FishSpeech🐠
Fish Speech Dialogue — современный инструмент для озвучивания диалогов и реплик с использованием разнообразных голосов.
Благодаря портативной версии не нужна установка базового Fish Speech MOD, а функциональность доступна «из коробки»:
Поддержка до 10 говорящих. Идеально для одиночных реплик и сложных диалогов.
Автоматическое распределение голосов. Экономит время, подбирая подходящие голоса для каждого персонажа.
Библиотека из 50+ голосов от сообщества. От Жириновского до Яндекс Алисы.
Форматирование диалогов. Автоматическое оформление в формате «Говорящий: текст».
Различные форматы сохранения. Поддерживаются WAV, MP3 и FLAC.
Мультиязычный интерфейс. Доступны русский и английский.
Автообновления и интеграция с GitHub.
❯ Обзор интерфейса
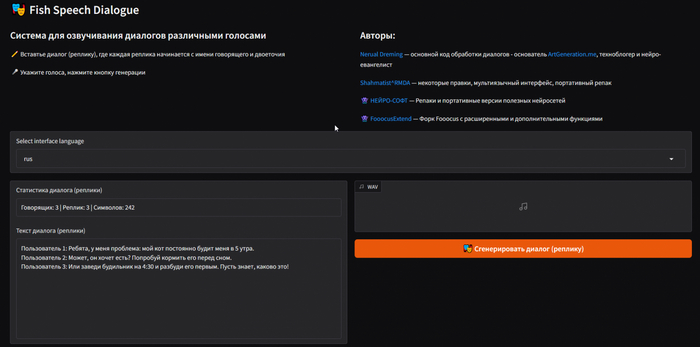
Интерфейс FishSpeech Dialogue
Нас встречает такой интерфейс. В самой верхней строке можно выбрать язык интерфейса, изначально будет английский.
Левое окно «Статистика диалога» — основное рабочее поле. В верхней части окна отображается количество говорящих, число реплик и общее количество символов. Нижняя часть содержит текст диалога.
Диалоги необходимо оформлять так: каждая реплика должна начинаться с имени говорящего и двоеточия. Пример видно на скриншоте выше.
В правой части интерфейса находится блок с итоговым результатом и кнопка «Сгенерировать диалог».
Плавно спускаемся ниже.
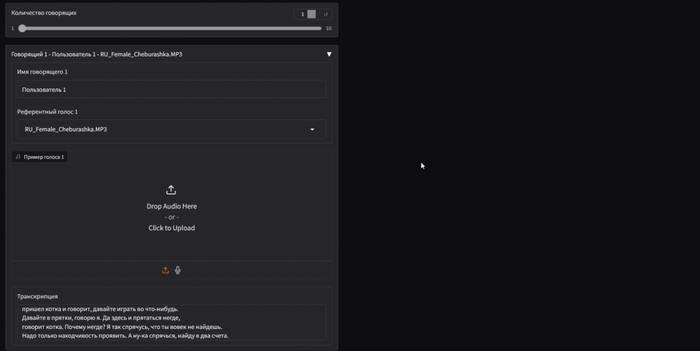
Количество говорящих — это автоматический параметр, который определяется системой в зависимости от структуры диалога.
Для каждого говорящего доступна отдельная панель настроек. Здесь можно:
Указать имя говорящего, которое должно совпадать с именем в тексте диалога.
Выбрать референсный голос из доступных вариантов.
Загрузить собственную аудиодорожку и использовать голос из неё. Также необходимо подписать транскрипцию. В этом случае нейросеть будет использовать загруженный голос для генерации диалога. Транскрипцию пишем сплошным текстом.
Последняя функция очень полезна. Когда ваш профессиональный диктор заболел, можно чуть схитрить и продолжить процесс записи и озвучки :D
В самом низу находятся расширенные настройки:
Честно, расширенные параметры я не щупал, меня интересовал лишь принцип работы и результаты. Но я попросил ассистента Perplexity пояснить, что это, кому интересно, вот выжимка:
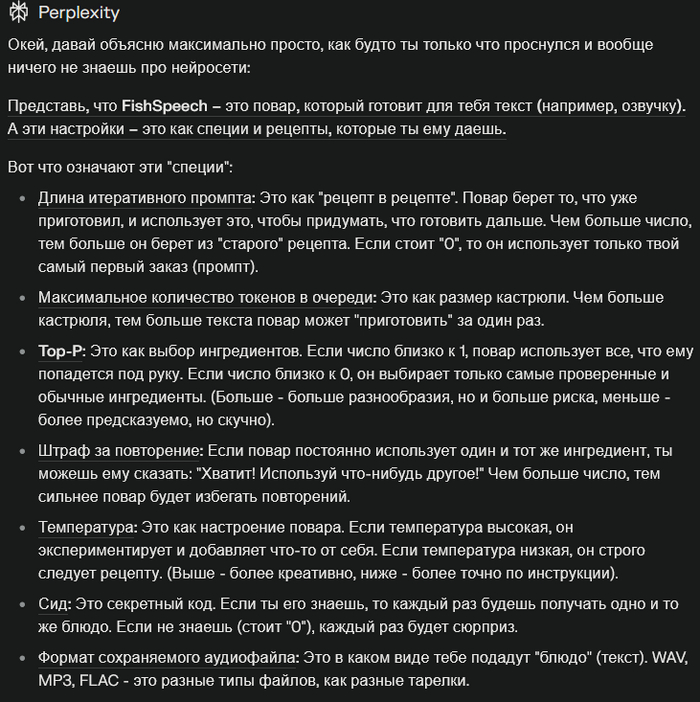
В общем, всё до безумия просто. Пишем или генерируем диалог, выбираем голоса и получаем озвучку. Давайте посмотрим на неё в деле.
❯ Примеры и возможности
Начнём с простого — рассуждения Винни-Пуха.
Давайте усложним и представим миниатюру: бытовой диалог Джонни Сильверхенда и Яндекс Алисы.
Сгенерируем диалог с тремя участниками - Шерлок Холмс, Сергей Дружко и Кот Матроскин. Такого вы ещё не слышали.
Далее я решил попробовать сгенерировать что-нибудь на английском с голосом Матроскина. И вышло очень даже неплохо и похоже.
Дмитрий Нагиев и Чебурашка:
Ну и напоследок я попросил свою знакомую записать пару голосовых для теста. Дальше скачал их в формате .ogg, конвертировал в .mp3 и загрузил в нейросеть. Для транскрипции я использую крутую нейронку Whisper, скачать её можно на GitHub. Там всё интуитивно понятно, думаю, разберётесь. Вот что получилось.
Ещё пара примеров:
Как итог, FishSpeech — удобный инструмент, который помогает озвучивать тексты даже в ситуациях, когда запись голоса невозможна. Простота и гибкость делают его отличным решением для создания игр, подкастов, аудиокниг и других проектов, где важна качественная озвучка.
Скачать портативную версию FishSpeech с установкой в один клик для самых ленивых вы можете тут.

Подписывайтесь на 👾Нейро-Софт, канал с портативными версиями ваших любимых нейросетей!
Показать полностью
6
8
Сколько часов то?
Спросил у пары нейронок: сколько часов в месяц работает работник, если он работает 5 дней в неделю по 8 часов, но каждые 4 дня работает 24 часа. Ни одна не угадала с ответом, даже после уточнений :( Не умеют/знают про выходные дни и что нельзя в один день работать больше 24 часов?
ИИ-ассистент для веб-навигации
WebRover — ваш автономный ИИ-ассистент для веб-навигации и работе в браузере!
Мощный AI-агент, созданный для выполнения пользовательских запросов через взаимодействие с веб-элементами. Использует современные языковые модели и инструменты автоматизации для эффективной навигации по интернету, сбора информации и предоставления структурированных ответов.
Показать полностью

Суть Алисы как ИИ
- Алиса, какой сегодня день?
- Сегодня суббота, 8 марта!
- А что за день - 8 марта?
- 8 марта - праздник, Международный женский день!
- Так, стало быть, какой сегодня день?
- Сегодня суббота, 8 марта!
Не умеют они там в Яндексе (как минимум) в искусственный интеллект. Хоть и кудахтают об этом на каждом шагу.

8 марта, а ты снова даришь банальные подарки?

Твой дружелюбный сосед, @cyberslav_ru на связи!
Сейчас за 5 минут мы сделаем незабываемый подарок с помощью ИИ - бесплатно!
И этим подарком будут НЕЙРОФОТКИ, вот такие:

ПОЕХАЛИ!
Шаг 1: Откройте Heygen.com (можно без VPN).
Шаг 2: Зарегистрируйтесь.
Шаг 3: В главном меню слева выберите раздел «Avatars».
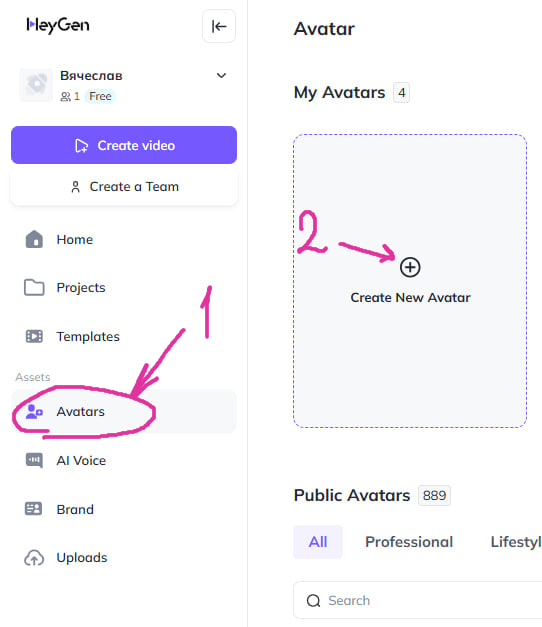
Шаг 4: Нажмите «Create New Avatar».
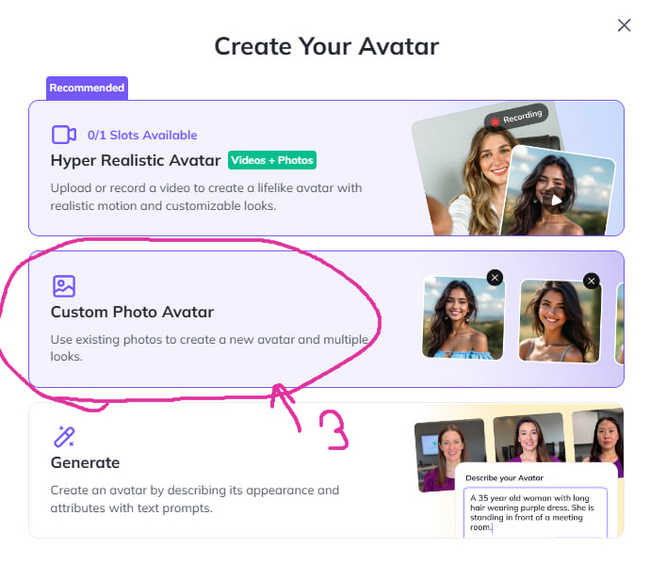
Шаг 5: Загрузите побольше фотографий с чётким очертанием лица (чем больше, тем лучше).
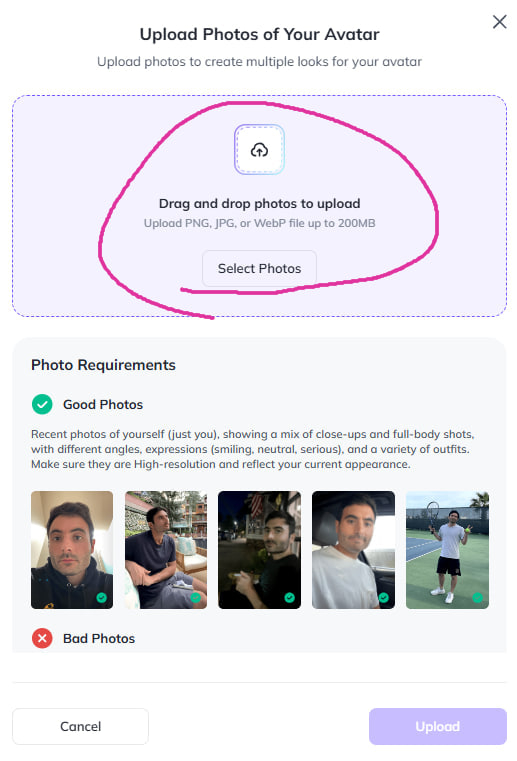
Шаг 6: Дождитесь полной загрузки серии фото.
Шаг 7: После успешной загрузки нажмите «TRAIN MODEL» для обучения аватара.
Шаг 8: В разделе «Generate looks» введите вашу идею на английском (например: «Девушка в красном платье лежит в куче ярких красивых цветов»). "A girl in a red dress lies in a pile of bright and beautiful flowers"
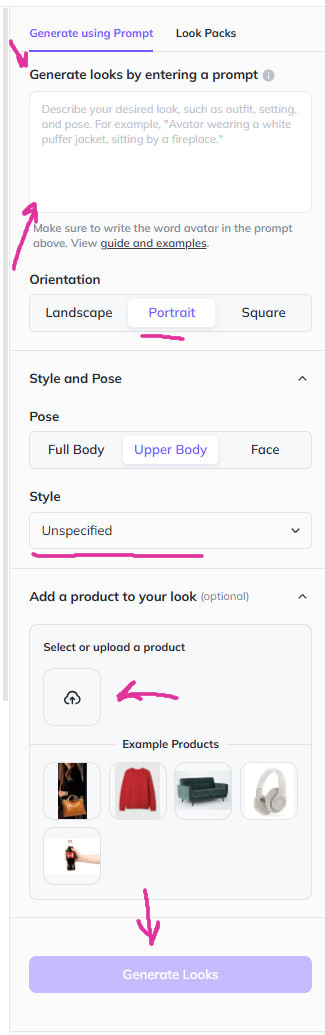
Шаг 9: В поле «Orientation» выберите нужный формат.
Шаг 10: В разделе «Style and pose» задайте положение кадра и стиль рисунка.
Шаг 11: В разделе «add a product» при необходимости добавьте объекты (например, любимую игрушку вашей женщины).
Шаг 12: Нажмите «Generate Looks» и дождитесь результата.
🔥 БОЛЬШЕ ГОДНЫХ ИНСТРУКЦИЙ НА ИИ В МОЕМ ТЕЛЕГРАМ КАНАЛЕ
ГОТОВО!

Показать полностью
7

Кошмар для бигтеха: как обучить большую ИИ-модель всем миром
Путь к победе в современной гонке за ИИ заключается в поиске новых эффективных архитектур, методов обучения, качественных данных (включая синтетические) и вычислительных ресурсов.
Когда мы слышим про «обучение больших ИИ-моделей» обычно представляем громадный кластер из видеокарт, который стоит миллиарды долларов и по карману лишь топовым корпорациям. Более того, такой подход опасен утечкой данных и усиливает «концентрацию власти», ведь широкая общественность не участвует в подготовке данных для обучения.
На этом фоне появляется децентрализованное обучение: вместо одного суперкластера ресурсы и данные распределяются по множеству независимых узлов. Каждый узел хранит свои данные, обучает локальную версию модели и периодически синхронизируется с другими. Новые узлы могут подключаться «на лету», что обеспечивает гибкое масштабирование и независимость от единого дата-центра.
Университеты, стартапы и энтузиасты со всего мира способны собрать модель, сопоставимую по качеству с решениями крупных компаний. Кажется, привычная монополия бигтеха на гигантские вычислительные мощности может разрушиться.
Наиболее известный метод децентрализованного обучения — федеративное обучение, которое Google впервые применил для персонализированных моделей на смартфонах для предиктивного ввода с клавиатуры. Сервер рассылает начальную модель на устройства, где она обучается на локальных данных, а назад отправляются только изменения весов. Сервер усредняет полученные обновления и формирует «глобальную модель». Приватность при этом сохраняется, поскольку исходные данные никуда не передаются.
Но есть и более «экзотические» варианты: полная децентрализация без единого сервера (узлы синхронизируются по схеме peer-to-peer) или блокчейн-решения со «смарт-контрактами», которые регистрируют вклад каждого участника и гарантируют распределение вознаграждений.
Недавно группа энтузиастов представила INTELLECT-1 — децентрализованно обученную языковую модель на 10 млрд параметров. Она показала результаты, сопоставимые с решениями аналогичного размера, обученными классическим путем. Хотя проект пока пилотный, он подтверждает практичность и экономическую эффективность децентрализованного подхода.
Почему INTELLECT-1 интересен?
1. Участникам не нужно тратить миллионы долларов на единую инфраструктуру.
2. Проект ориентирован на открытое сообщество и ценит коллективную ответственность при решении этических вопросов. Такая модель может стать основой для будущего AGI.
3. Каждый получает вознаграждение пропорционально предоставленным вычислительным мощностям.
Prime Intellect обучили INTELLECT-1 на 14 узлах, распределенных по трем континентам, с участием 30 независимых членов сообщества, предоставляющих вычислительные ресурсы.
Код обучения использует фреймворк Prime, масштабируемую распределенную систему для отказоустойчивого и высокопроизводительного обучения на ненадежных, глобально распределенных рабочих узлах.
Модель была обучена с использованием метода DiLoCo (Distributed Low-Communication Training). Судя по бенчмаркам, она оказалась в среднем примерно на уровне Llama 2 7B, но есть модели получше (Llama 3.1, Qwen 2.5), поэтому вряд ли кто-то будет ее использовать. Но все же для первого децентрализованного обучения такого масштаба результаты отличные.
В будущем Prime Intellect планируют расширить масштабы обучения, оптимизировать стек и добавить финансовую мотивацию для сообщества
Блокчейн добавляет новый уровень. Теоретически можно создать гигантскую сеть в форме ДАО (децентрализованной автономной организации), объединяющую GPU-фермы в единый «убер-кластер» без головной компании-владельца.
Так появилась AIArena — децентрализованная блокчейн-платформа для обучения ИИ. За семь месяцев она привлекла 603 узла, которые создали 18 656 моделей для 16 задач. Эти модели оказались эффективнее базовых, а механизм консенсуса в блокчейне обеспечил справедливое вознаграждение каждому участнику исходя из его вклада.
Разумеется, в децентрализованном обучении остаются нерешенные вопросы: например, как корректно синхронизировать множество узлов или что делать с «мусорными» данными отдельных участников. Однако эти проблемы в целом решаемы.
Объединив тысячи научных лабораторий, владельцев GPU-ферм и даже геймеров можно обучить большую модель без контроля корпораций. Снижая зависимость от дорогих дата-центров, ИИ-технологии становятся более доступными. И хотя децентрализованный ИИ еще не доминирует, он уже становится реальной альтернативой.
Возможно, через несколько лет громоздкие GPU-кластеры в одном здании будут казаться архаизмом. Но кто станет лидером в эпоху децентрализованных суперкомпьютеров? Думаю появятся новые децентрализованные проекты, которые станут серьезным вызовом для текущих бизнес-моделей крупных технологических компаний.
Не пора ли нам объединиться и покончить с монополией бигтеха?
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Показать полностью
1
1