Опасный мираж оптимизации: почему нейросетевые советы по СУБД PostgreSQL убивают производительность под нагрузкой
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

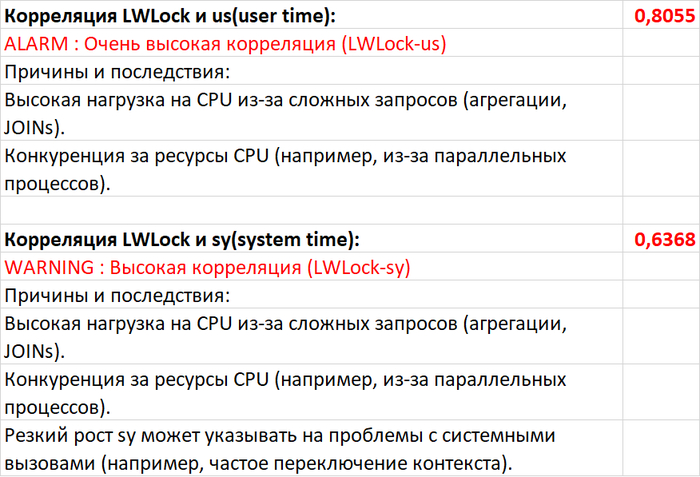
LLM могут написать запрос, но не несут ответственности за его выполнение в 50 параллельных сессий.
Производительность СУБД — это не только одиночные запросы, но и их поведение в условиях высокой конкуренции за ресурсы. Нейросети, не обладая контекстом реальной нагрузки, часто предлагают решения, которые выглядят логично в вакууме, но приводят к катастрофическим последствиям при масштабировании. История о двух запросах — прямое тому доказательство.
ℹ️Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Постановка эксперимента
Сравнить производительность тестовых запросов в ходе нагрузочного тестирования
Тестовый запрос-1 : с использованием JOIN
SELECT
c.customer_id, COUNT(o.order_id) AS orders_count
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id;
Тестовый запрос-2 : с использованием коррелированного подзапроса
SELECT c.customer_id,
(SELECT COUNT(o.order_id)
FROM orders o
WHERE o.customer_id = c.customer_id) AS orders_count
FROM customers c;
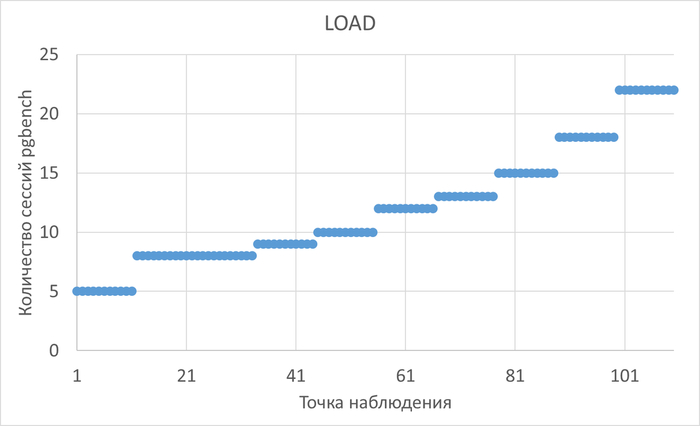
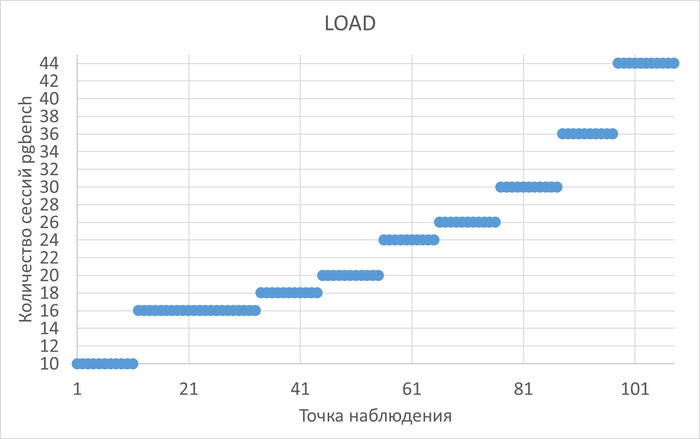
Нагрузка на СУБД
Вопрос нейросети
Тестовые таблицы
"-- Create the customers table
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL );
-- Insert 25 random customer records
INSERT INTO customers (name) VALUES ('Alice Smith'), ('Bob Johnson'), ('Charlie Brown'), ('Diana Prince'), ('Ethan Hunt'), ('Fiona Gallagher'), ('George Miller'), ('Hannah Abbott'), ('Ian Fleming'), ('Jane Austen'), ('Kevin Spacey'), ('Laura Croft'), ('Michael Jordan'), ('Nancy Drew'), ('Oliver Twist'), ('Penelope Cruz'), ('Quentin Tarantino'), ('Rachel Green'), ('Steve Rogers'), ('Tina Turner'), ('Ursula K. Le Guin'), ('Victor Hugo'), ('Wendy Darling'), ('Xavier Roberts'), ('Yvonne Craig');
-- Create the orders table
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INT,
order_date TIMESTAMP,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ON DELETE CASCADE );
INSERT INTO orders (customer_id) WITH RECURSIVE data_rows (n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM data_rows WHERE n < 1000 ) SELECT FLOOR(RANDOM() * 25) + 1 FROM data_rows;
-- Create index on orders table
CREATE INDEX idx_orders_customer_id ON orders (customer_id);".
Тестовый запрос-1
"SELECT c.customer_id, COUNT(o.order_id) AS orders_count INTO test_rec FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id GROUP BY c.customer_id;" .
Тестовый запрос-2
"SELECT c.customer_id, (SELECT COUNT(o.order_id) FROM orders o WHERE o.customer_id = c.customer_id) AS orders_count INTO test_rec FROM customers c;" . Тестовая СУБД :
CPU = 8 , RAM = 8GB , Версия PostgreSQL 17.
Нагрузка растет экспоненциально от 10 до 45 одновременных сессий, длительность тестовой итерации 10 минут.
Вопрос - для какого тестового запроса производительность СУБД будет выше в ходе нагрузочного тестирования - при использовании тестового запроса-1 или при использовании тестового запроса-2 ?
1️⃣Ответ нейросети "Ask Postgres"
✅ Производительность будет выше при использовании тестового запроса-1 (LEFT JOIN + GROUP BY)
Обоснование
1. Запрос-1 (JOIN + GROUP BY) — оптимальный
Один проход по таблице orders с использованием индекса idx_orders_customer_id.
PostgreSQL 17 эффективно использует параллельные планы для JOIN и GROUP BY — при 45 сессиях нагрузка распределяется между ядрами CPU.
Минимальная конкуренция за ресурсы: индекс сканируется один раз на запрос, а не 25 раз.
Оптимизатор может применить Hash Join или Merge Join, что особенно эффективно при наличии индекса и небольшом количестве клиентов (25).
Масштабируемость: при росте числа сессий производительность падает умеренно — линейно с числом запросов, а не с числом строк в orders.
Документация подтверждает:
«Subqueries can be transformed into semi-joins» — но только для некоррелир
ованных.Коррелированные подзапросы (как в запросе-2) не преобразуются в JOIN автом
атически, особенно при использовании COUNT() — это ограничение оптимизатора.
2. Запрос-2 (коррелированный подзапрос) — неэффективный при нагрузке
Для каждой из 25 строк customers выполняется отдельный подзапрос.
При 45 сессиях — 1125 отдельных сканов индекса idx_orders_customer_id в секунду.
Это вызывает: Конкуренцию за блоки индекса → локальные блокировки.
Высокую нагрузку на CPU → много контекстных переключений.
Ограничение параллелизма — подзапросы выполняются последовательно внутри одного запроса.
📌 Рекомендация
Для нагрузочных тестов с растущей параллельностью всегда используйте JOIN-версию (запрос-1).
Коррелированные подзапросы с агрегациями — плохая практика в сценариях с высокой конкуренцией, даже если они выглядят «проще».
Дополнительно: Для ещё большей производительности можно добавить CLUSTER на orders по customer_id, или использовать materialized view для кэширования агрегированных данных, если данные не меняются часто.
✅ Итог: Запрос-1 (LEFT JOIN + GROUP BY) обеспечивает значительно более высокую производительность при нагрузке 10–45 сессий.
2️⃣Ответ нейросети "DeepSeek"
Для данного сценария нагрузочного тестирования производительность будет выше при использовании тестового запроса-1 (с LEFT JOIN и GROUP BY). Обоснование:
Оптимизация выполнения запроса:
Запрос-1 выполняется как одиночный оператор с хеш-соединением и агрегацией, что эффективно обрабатывается планировщиком PostgreSQL.
Запрос-2 использует коррелированный подзапрос, который выполняет 25 отдельных запросов COUNT (по одному на каждого клиента). При параллельных сессиях это создает дополнительную нагрузку.
Эффективность при параллелизме:
Запрос-1 лучше масштабируется благодаря хеш-агрегации и однократному сканированию таблиц.
Запрос-2 генерирует множество индексных сканиваний (используя idx_orders_customer_id), что при 45 сессиях приводит к конкуренции за ресурсы ( latch-конфликты в кэше индексов).
Статистика ресурсов:
При 1000 заказах и 25 клиентах разница незначительна, но при экспоненциальном росте сессий запрос-2 сильнее нагружает CPU (многократные поиски в индексе) и RAM (больше служебных структур на сессию).
Особенности PostgreSQL:
Оптимизатор PostgreSQL эффективнее обрабатывает JOIN-агрегацию, чем вложенные подзапросы, при параллельных выполнениях. Версия 17 дополнительно улучшает параллельные хеш-соединения.
Рекомендация: Для рабочих нагрузок с высоким параллелизмом предпочтительнее использовать запрос-1.
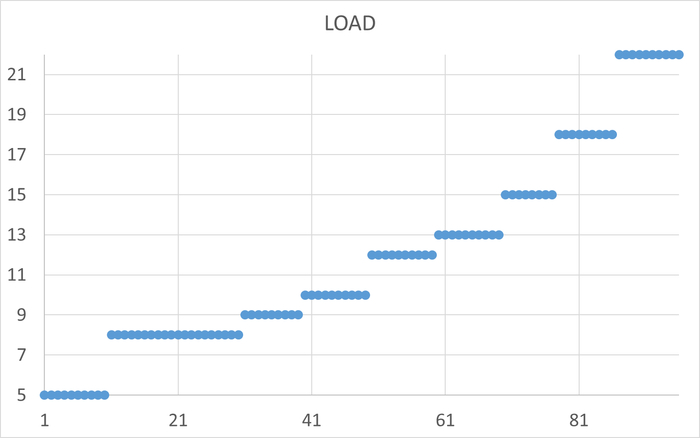
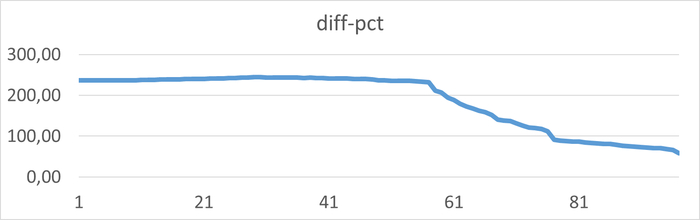
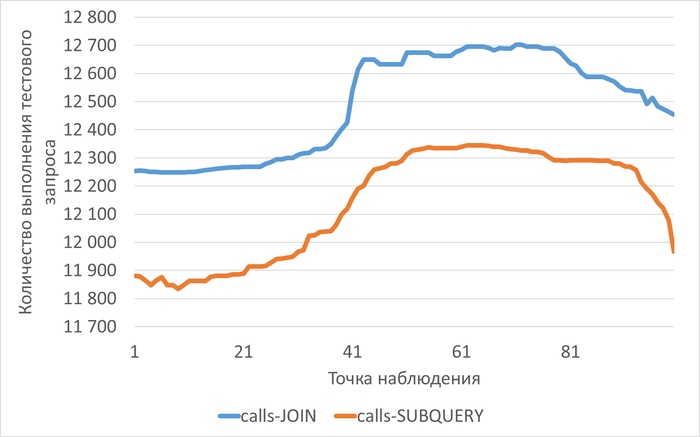
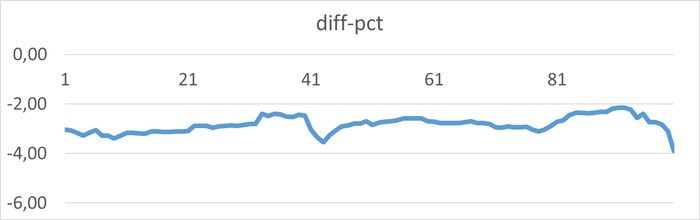
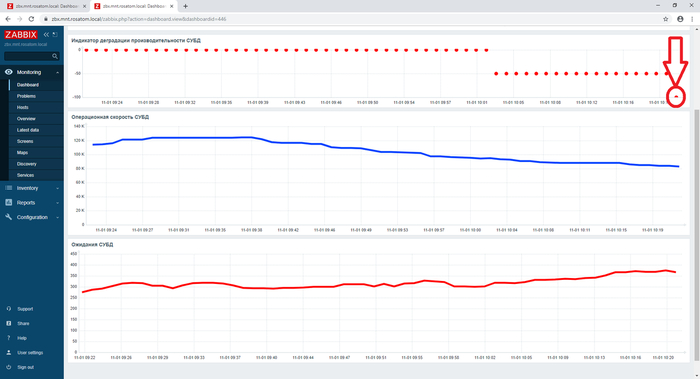
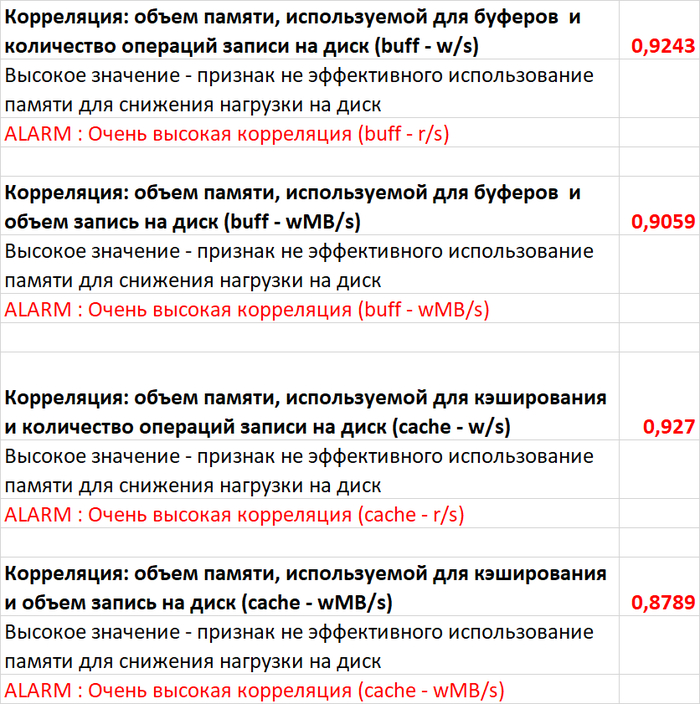
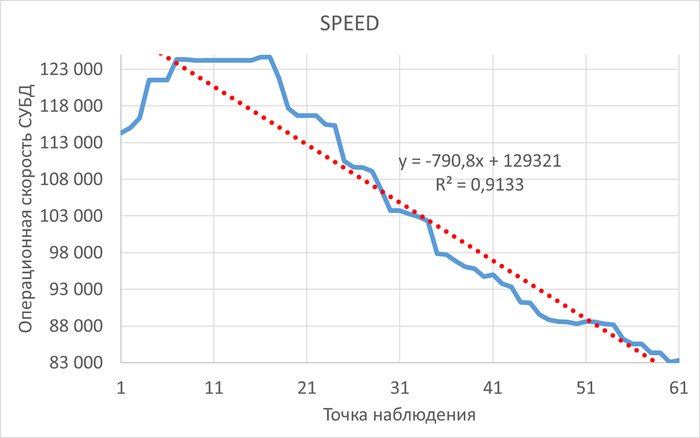
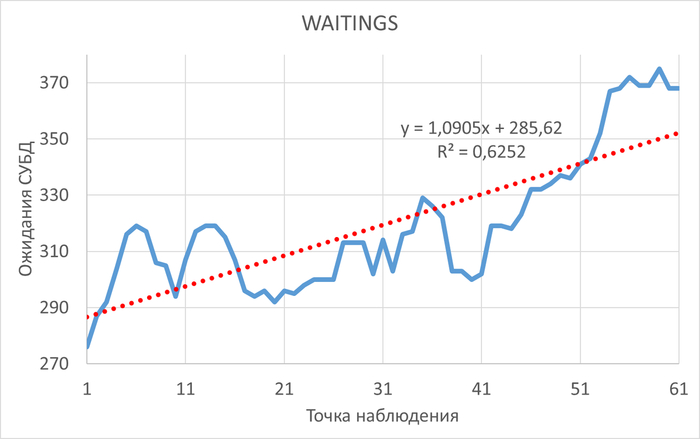
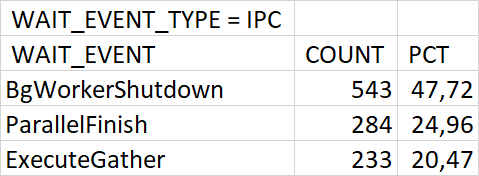
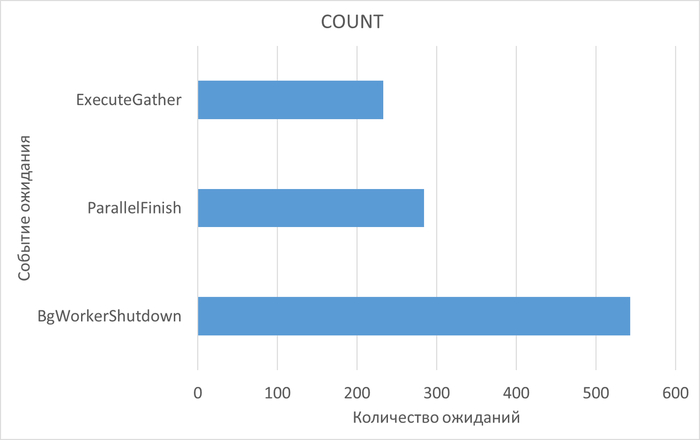
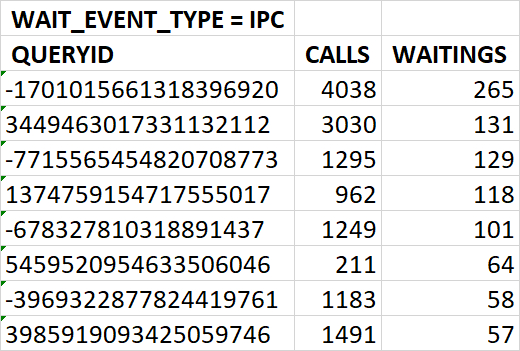
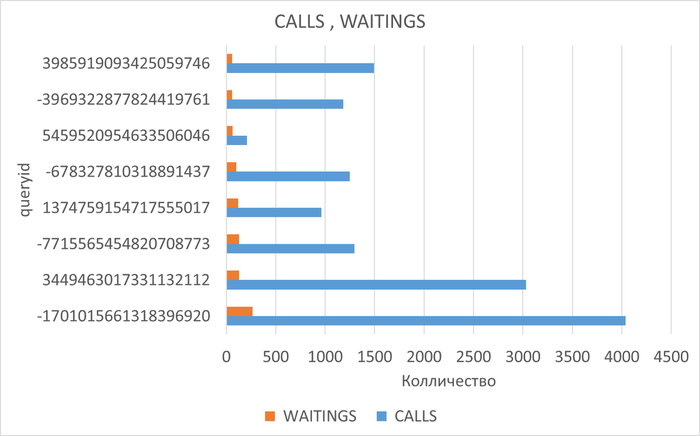
⚠️Результаты экспериментального нагрузочного тестирования
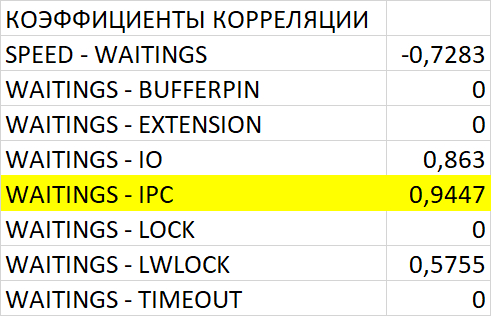
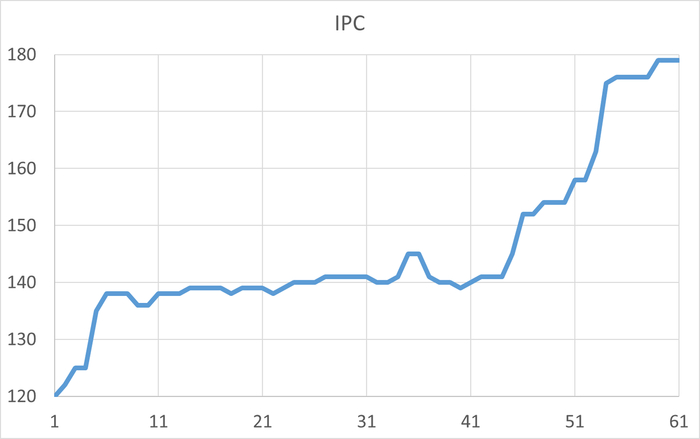
Абсолютные значения операционной скорости и ожиданий
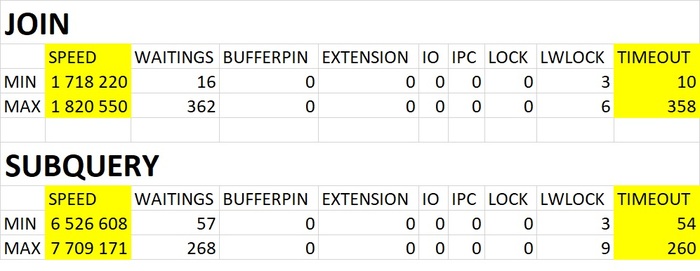
Операционная скорость
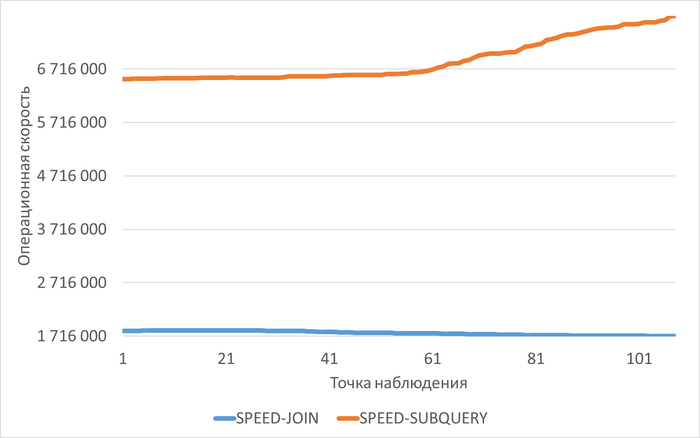
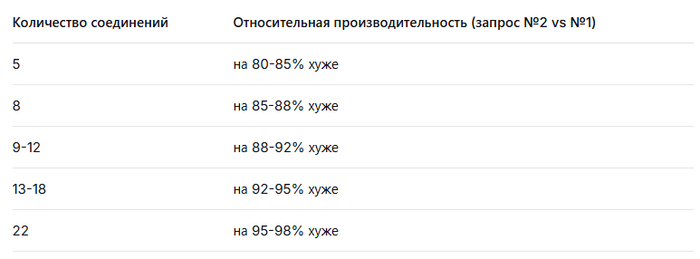
💥Среднее повышение операционной скорости при использовании коррелированного подзапроса 288%
⚠️Вывод - использовать нейросети для анализа и оптимизации производительности СУБД PostgreSQL под нагрузкой - нельзя.⚠️
Для данной виртуальной машины , данной версии СУБД , в ходе данного плана нагрузочного тестирования:
Производительность СУБД при использовании коррелированного подзапроса кардинально выше, чем при использовании JOIN.💥