PG_HAZEL : Использование корреляционного анализа ожиданий СУБД и метрик ОС для определения причин деградации производительности СУБД
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Правильно настроенный агрегат - быстрее.
Задача
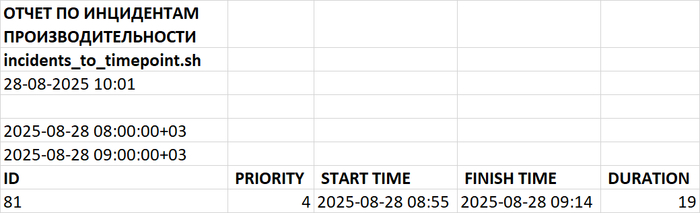
Провести корреляционный анализ ожиданий СУБД PostgreSQL и метрик Операционной системы для определения корневой причины деградации производительности СУБД.
Используемая методика корреляционного анализа
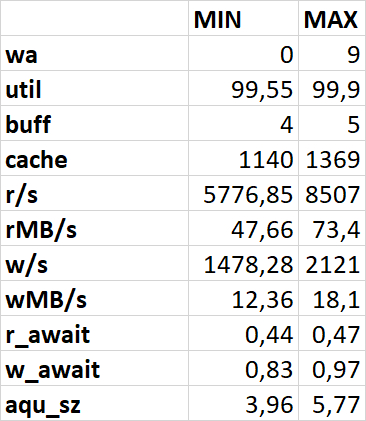
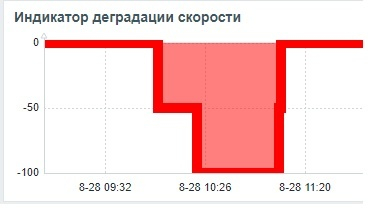
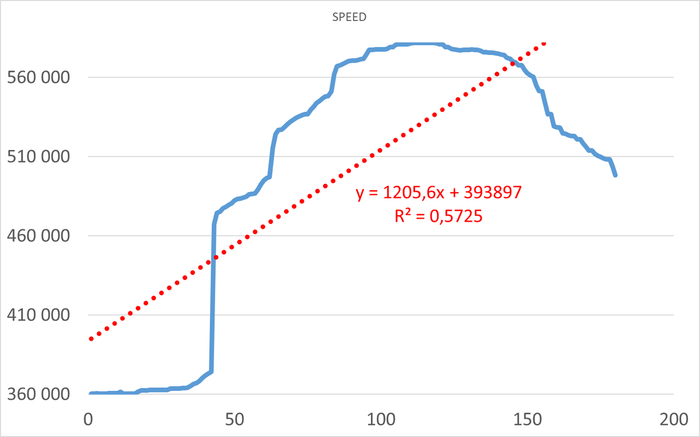
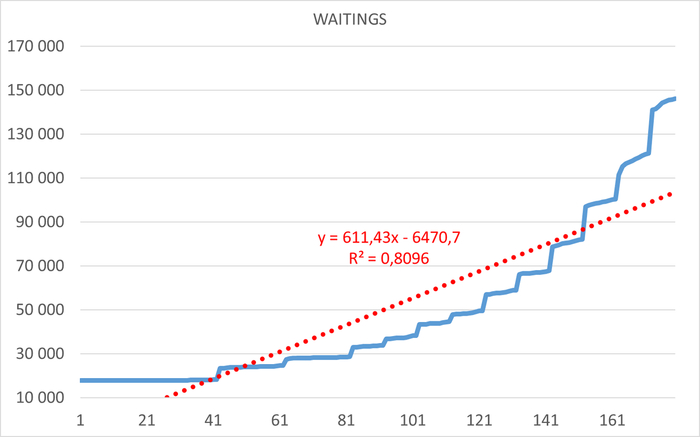
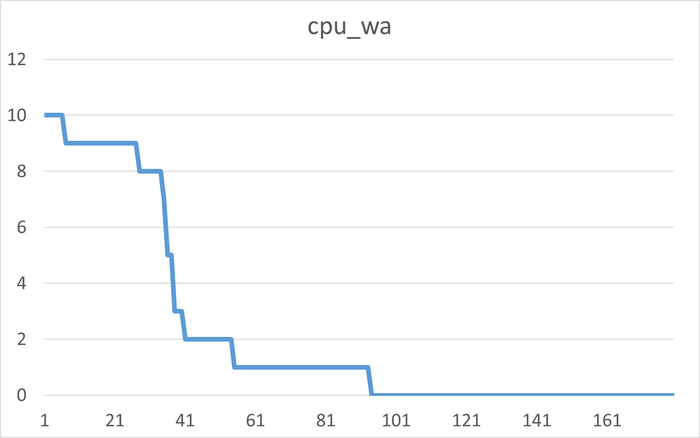
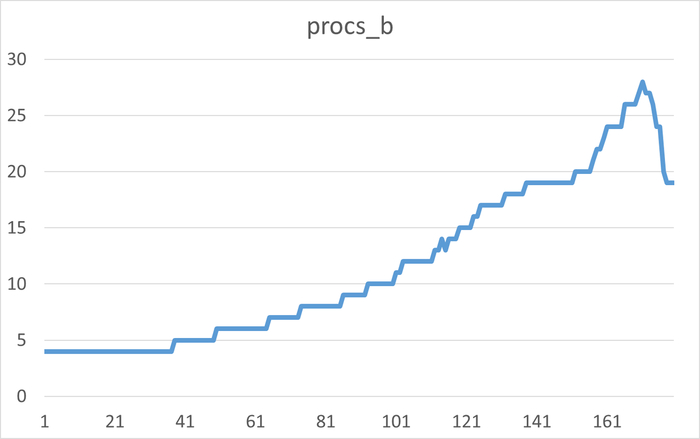
Результаты нагрузочного тестирования виртуальной машины-06
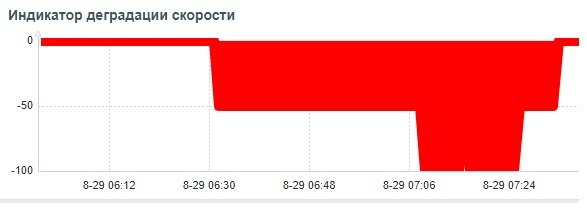
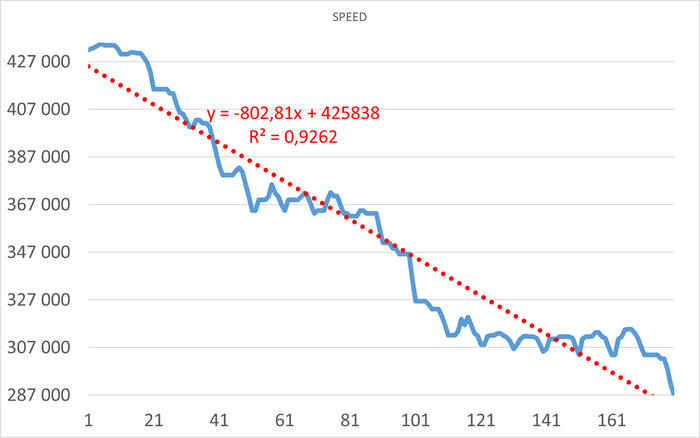
Операционная скорость
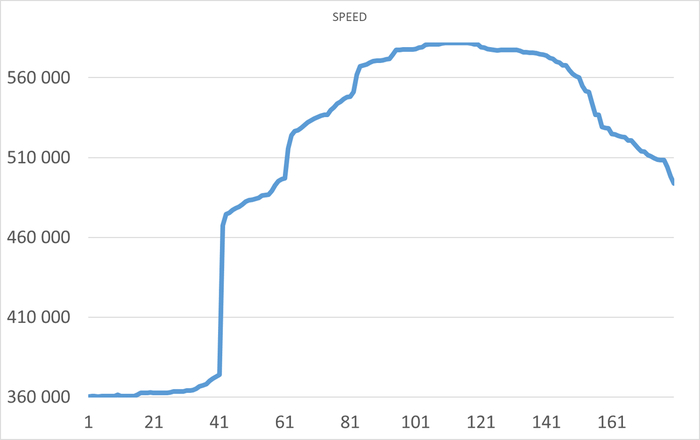
Ось X - точка наблюдения . Ось Y - операционная скорость
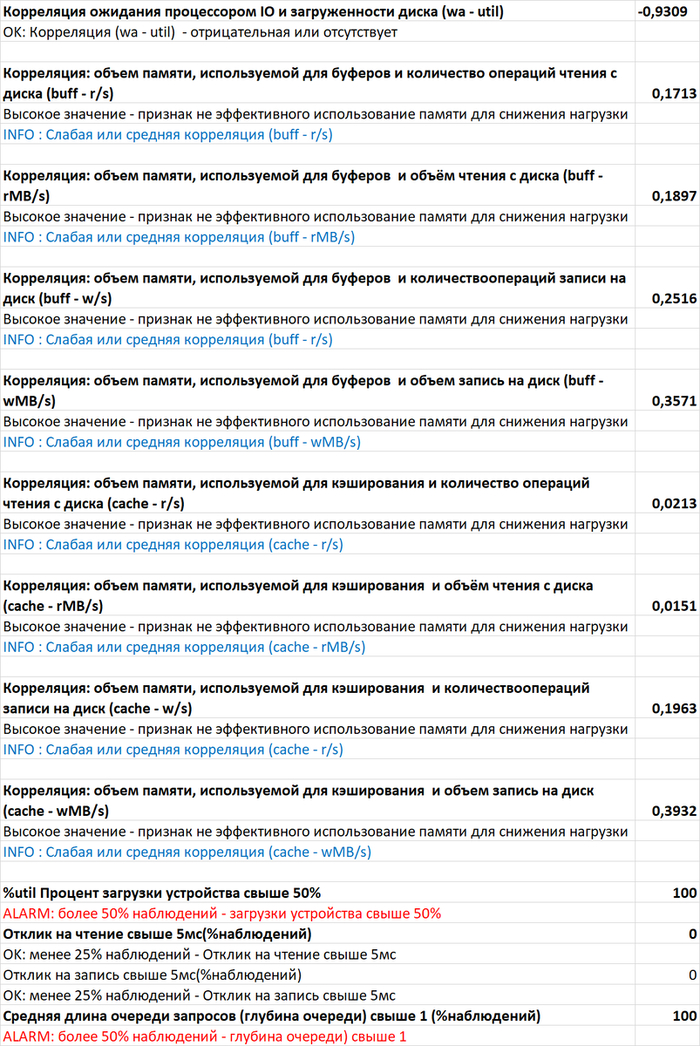
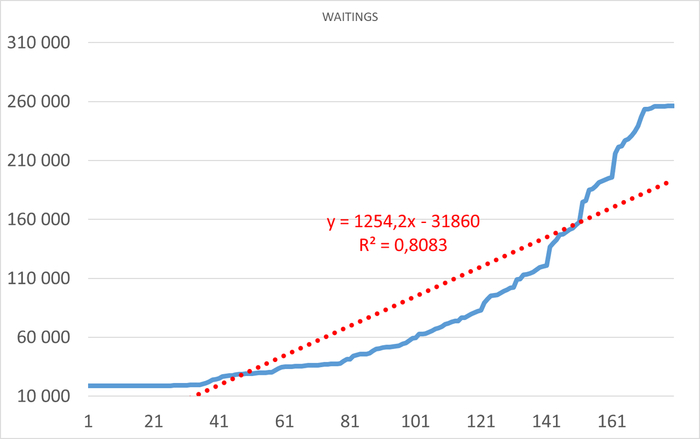
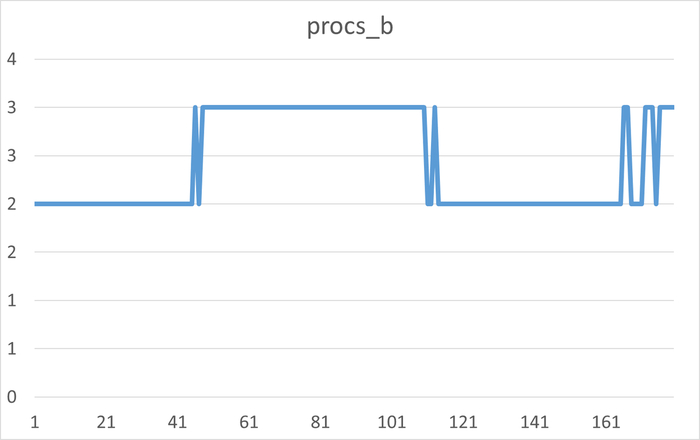
Корреляционный анализ ожиданий СУБД и метрик ОС

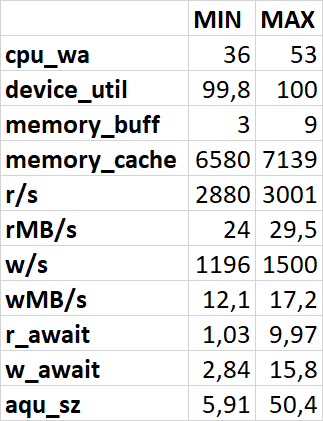
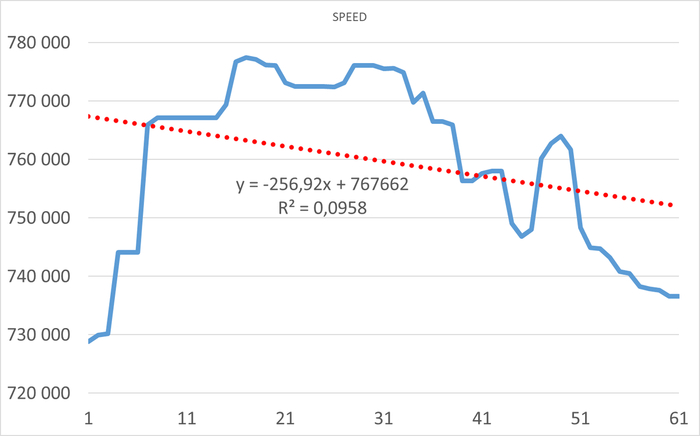
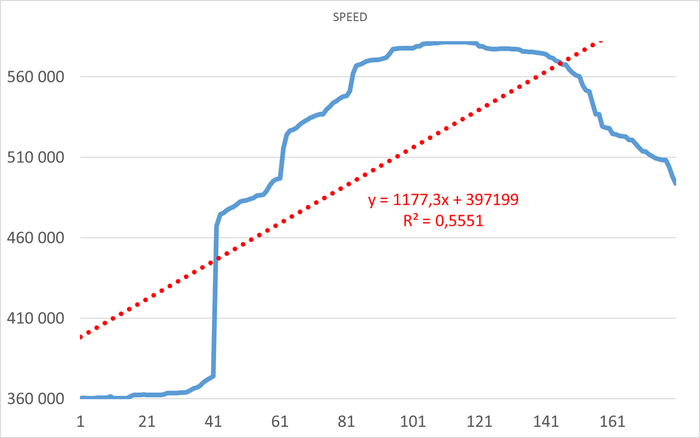
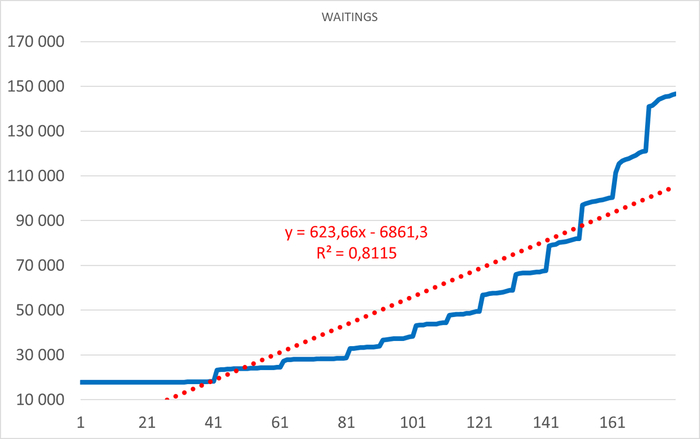
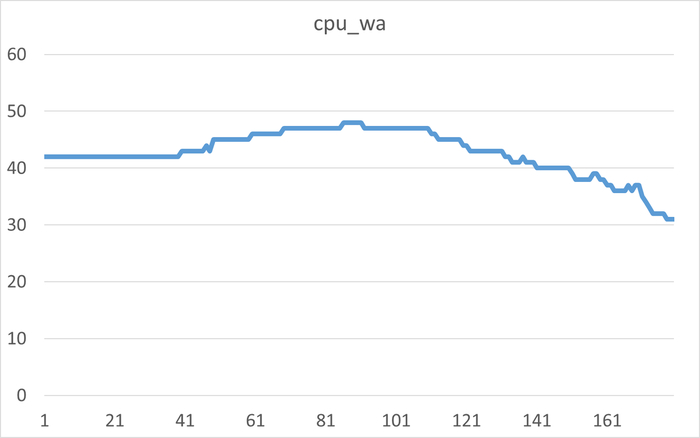
Результаты нагрузочного тестирования виртуальной машины-12
Операционная скорость
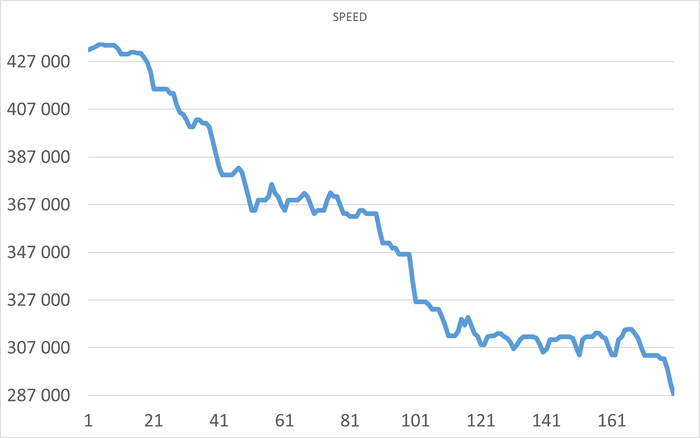
Ось X - точка наблюдения . Ось Y - операционная скорость
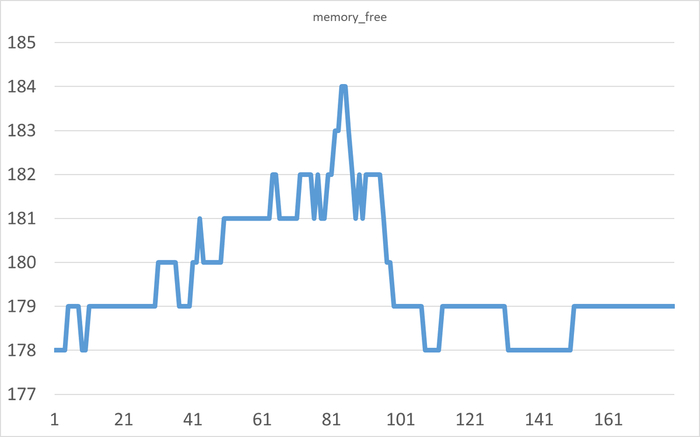
Корреляционный анализ ожиданий СУБД и метрик ОС

Показать полностью
4