PG_EXPECTO: Прицельный залп по проблемам производительности PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Определи цель, заряди параметры, устрани проблему
Предисловие:
Когда производительность СУБД падает под нагрузкой, важно не стрелять наугад. Методика PG_EXPECTO предлагает сначала выявить ключевые цели — проблемные запросы и типы ожиданий — и только затем наносить точный удар, используя «большие пушки» оптимизации.
1. Анализ ожиданий СУБД на основании данных о диаграмме Парето

Проанализируй данные по типам ожидания в ходе инцидента производительности СУБД PostgreSQL
1. Анализ ожиданий типа IPC (Inter-Process Communication)
BgWorkerShutdown (40,62%) — наиболее проблемное событие:
Указывает на ожидание завершения фоновых процессов
Возможные причины:
Медленное завершение параллельных worker-процессов
Проблемы с освобождением ресурсов
Возможные deadlock-ситуации при завершении
ParallelFinish (25,4%) и ExecuteGather (21,14%):
Связаны с параллельным выполнением запросов
Высокие значения могут указывать на:
Слишком агрессивные настройки параллелизма
Конкуренцию за ресурсы между параллельными worker-ами
Неоптимальные планы выполнения параллельных запросов
2. Анализ ожиданий типа LWLock (Lightweight Locks)
BufferMapping (49,46%) — основная проблема в блокировках:
Указывает на конкуренцию за доступ к буферному кешу
Возможные причины:
Недостаточный размер shared_buffers
Высокая конкурентная нагрузка на горячие данные
Отсутствие или неэффективность индексов
SerializableXactHash (31,72%):
Связано с транзакциями уровня изоляции SERIALIZABLE
Может указывать на:
Высокую конкуренцию за структуры данных serializable транзакций
Необходимость оптимизации транзакций
Рекомендации по устранению проблем:
Для IPC-ожиданий:
1.Проверить настройки параллелизма:
max_parallel_workers_per_gather
max_parallel_workers
max_worker_processes
2.Анализировать логи на предмет ошибок воркеров
3.Рассмотреть уменьшение параллелизма для сложных запросов
Для LWLock-ожиданий:
Оптимизировать работу с буферным кешем:
Увеличить shared_buffers (если позволяет RAM)
Проверить эффективность индексов
Рассмотреть использование pg_prewarm для критичных данных
Для Serializable транзакций:
Проверить необходимость использования SERIALIZABLE изоляции
Оптимизировать длительность транзакций
Рассмотреть альтернативные уровни изоляции
Общие рекомендации:
Сбор дополнительной информации:
Получить полный список ожиданий за период инцидента
Проверить мониторинг нагрузки на CPU, IO, память
Возможные immediate-действия:
Перераспределить нагрузку по времени
Временно снизить параллелизм
Добавить индексы на часто используемые поля в условиях WHERE/JOIN
Вывод:
Основные проблемы связаны с параллельным выполнением запросов и конкуренцией за буферный кеш. Рекомендуется поэтапная оптимизация настроек параллелизма и работы с памятью.
2. Анализ событий ожиданий по отдельным SQL-запросам на основании данных о диаграмме Парето
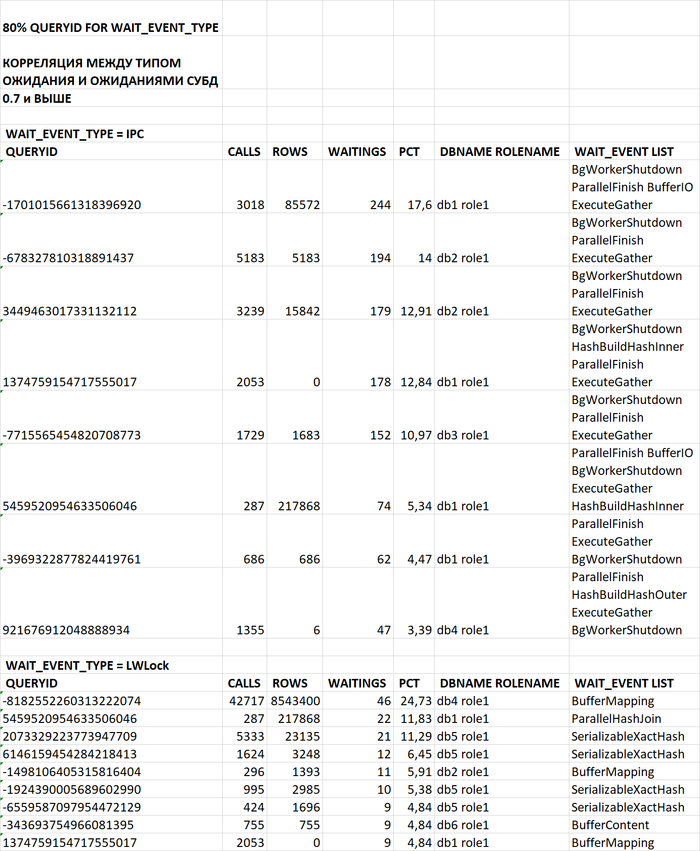
Проанализируй данные по событиям ожидания для SQL запросов по queryid в ходе инцидента производительности СУБД PostgreSQL
Ключевые выводы по корреляции типов ожиданий и запросов
1. Запросы с наибольшим влиянием на IPC-ожидания:
Топ-1 проблемный запрос (17,6% IPC ожиданий):
queryid: -1701015661318396920 3018 вызовов, 85k строк
Ожидания: BgWorkerShutdown, ParallelFinish, BufferIO, ExecuteGather
Анализ: Часто выполняемый параллельный запрос с проблемами завершения воркеров
Топ-2 (14% IPC ожиданий):
queryid: -678327810318891437 5183 вызовов, 5183 строк
Особенность: Каждый вызов возвращает ровно 1 строку
Высокая частота выполнения усиливает проблемы параллелизма
2. Запросы с наибольшим влиянием на LWLock-ожидания:
Топ-1 проблемный запрос (24,73% LWLock ожиданий):
queryid: -8182552260313222074 42,7k вызовов, 8,5M строк
Ожидания: BufferMapping
Анализ: Крайне часто выполняемый запрос с высокой конкуренцией за буферный кеш
Критический запрос, присутствующий в обеих категориях:
queryid: 5459520954633506046:
IPC: 5,34% (параллельное выполнение)
LWLock: 11,83% (ParallelHashJoin)
Особенность: 287 вызовов, но 217k строк на вызов (~759 строк/вызов)
Вероятно: Сложный аналитический запрос с хеш-соединениями
Детальный анализ проблемных паттернов:
A. Проблемы параллельного выполнения:
Запросы с ParallelFinish и ExecuteGather:
Все топ-8 IPC запросов имеют эти ожидания
Рекомендация: Уменьшить max_parallel_workers_per_gather для этих queryid
Конкретные кандидаты на оптимизацию:
queryid: 1374759154717555017 2053 вызова, 0 строк
Возможно, DML-операция с неправильным планом
Имеет HashBuildHashInner - проблема с хеш-таблицами
B. Проблемы с блокировками буферов:
Высокочастотные запросы:
queryid: -8182552260313222074 42k вызовов
Решение: Кэширование на уровне приложения, batch-обработка
Serializable транзакции в db5:
4 из топ-8 LWLock запросов используют SerializableXactHash
Все из базы db5
Рекомендация: Пересмотреть уровень изоляции
Приоритетные действия:
1. Немедленные меры:
Для queryid: -8182552260313222074 (42k вызовов):
-- Добавить индексы на используемые предикаты
-- Внедрить кэширование на 5-10 минут
Для queryid: -1701015661318396920 (частый параллельный запрос):
-- Принудительно отключить параллельное выполнение
SET max_parallel_workers_per_gather = 0;
2. Среднесрочная оптимизация:
Группа 1: Частые параллельные запросы
queryid: -678327810318891437 (5k вызовов)
queryid: 3449463017331132112 (3k вызовов)
Действие: Оптимизация планов, уменьшение частоты выполнения
Группа 2: Запросы с хеш-соединениями
queryid: 5459520954633506046
queryid: 1374759154717555017
Действие: Увеличить work_mem, добавить индексы для соединений
3. Долгосрочные изменения:
Для базы db5 (Serializable транзакции):
Аудит необходимости SERIALIZABLE изоляции
Возможный переход на REPEATABLE READ
Настройка PostgreSQL:
# Увеличить для уменьшения BufferMapping
shared_buffers
# Оптимизация параллельных запросов
max_parallel_workers_per_gather = 2 (вместо 4-8)
parallel_setup_cost = 1000
parallel_tuple_cost = 0.1
# Увеличение для хеш-соединений
work_mem = 32MB (или больше)
Рекомендуемый план действий:
Неделя 1: Оптимизация двух самых проблемных запросов
queryid: -8182552260313222074 (кэширование)
queryid: -1701015661318396920 (отключение параллелизма)
Неделя 2: Анализ и оптимизация запросов с хеш-соединениями
Добавление индексов
Пересмотр логики запросов
Неделя 3: Работа с часто выполняемыми запросами
Батчинг
Оптимизация бизнес-логики
Неделя 4: Пересмотр уровня изоляции в db5
Тестирование производительности при READ COMMITTED/REPEATABLE READ
Важно:
Все изменения должны тестироваться на staging-окружении с нагрузочным тестированием.
3.Сводный отчет по ожиданиям и проблемным SQL запросам
Сформируй сводный отчет по типам ожиданий и событиям ожиданий для проблемных SQL запросов в ходе инцидента производительности СУБД PostgreSQL
Контекст
В ходе инцидента производительности СУБД PostgreSQL выявлены проблемные SQL-запросы с высокой корреляцией (≥0.7) между типом ожидания и нагрузкой на СУБД. Отчет сформирован на основе анализа событий ожиданий и соответствующих запросов.
Ключевые наблюдения
Наиболее частые события ожидания:
IPC: BgWorkerShutdown (40,62%)
LWLock: BufferMapping (49,46%)
Наиболее проблемные запросы:
IPC: -1701015661318396920 (17,6% ожиданий)
LWLock: -8182552260313222074 (24,73% ожиданий)
Распределение по БД:
db1 и db5 имеют наибольшее количество проблемных запросов
role1 является общей ролью для всех проблемных запросов
Паттерны ожиданий:
Запросы с высоким числом CALLS часто имеют ожидания типа LWLock
Запросы с большим количеством возвращаемых ROWS склонны к ожиданиям IPC
Рекомендации для дальнейшего анализа
Сфокусироваться на оптимизации запросов с наибольшим процентом ожиданий
Исследовать причины частых событий BgWorkerShutdown и BufferMapping
Проанализировать работу параллельных операций (ParallelFinish, ExecuteGather)
Проверить настройки, связанные с управлением блокировками и параллельным выполнением