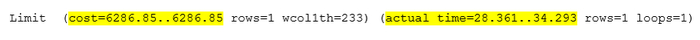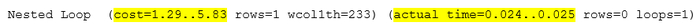PG_HAZEL : Оптимизация SQL-запросов как результат анализа инцидентов производительности СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

The owls are not what they seem.
Задача
Подготовка общей методологии по выявлению проблемных SQL-запросов влияющих на производительности СУБД и имеющих перспективы для оптимизации.
Формирование набора рекомендаций по оптимизации типовых SQL-запросов.
1. Выявление SQL-запросов для оптимизации
Детали и подробности: PG_HAZEL : Анализ инцидента производительности СУБД PostgreSQL , поиск и оптимизация проблемных SQL-запросов.
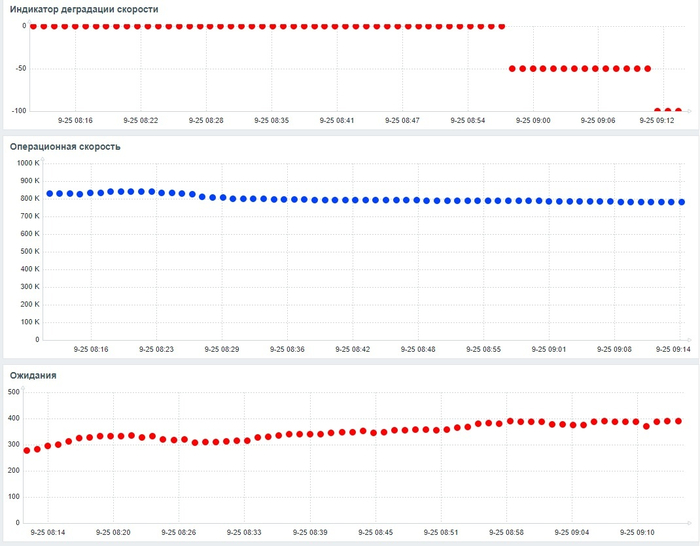
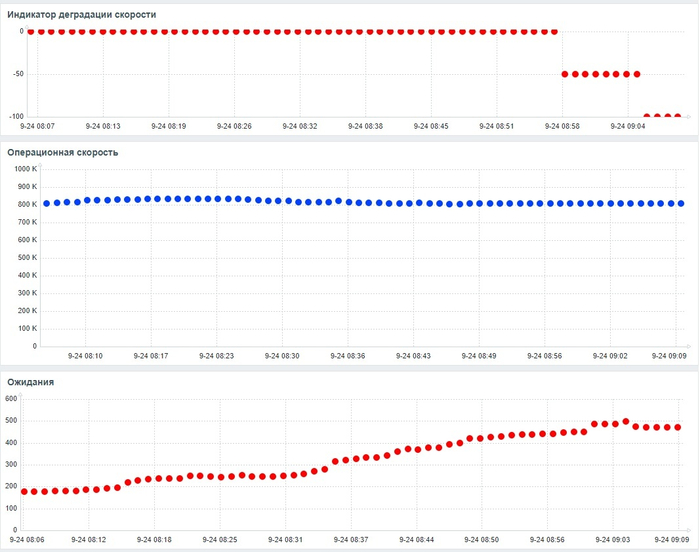
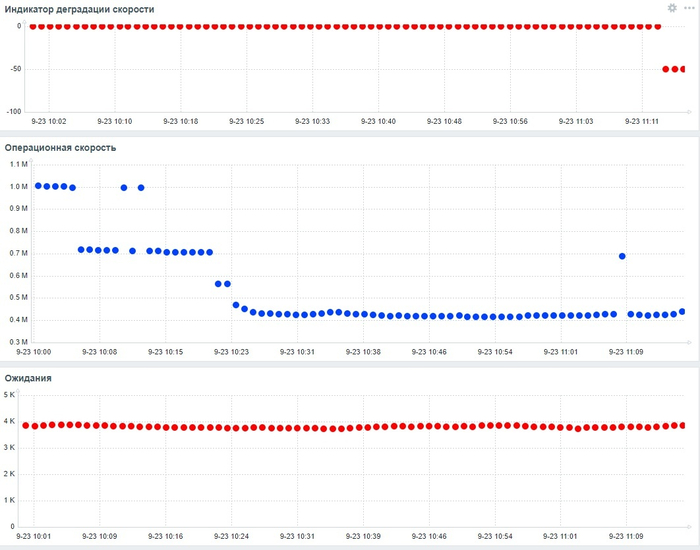
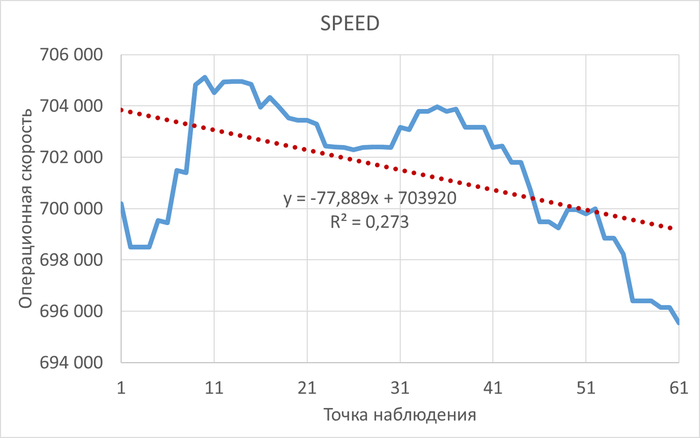
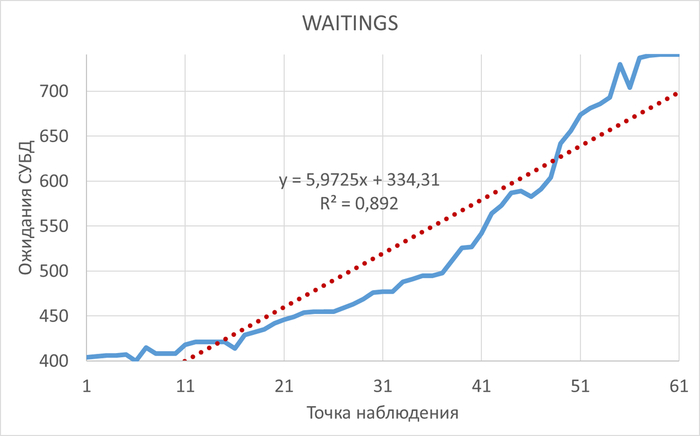
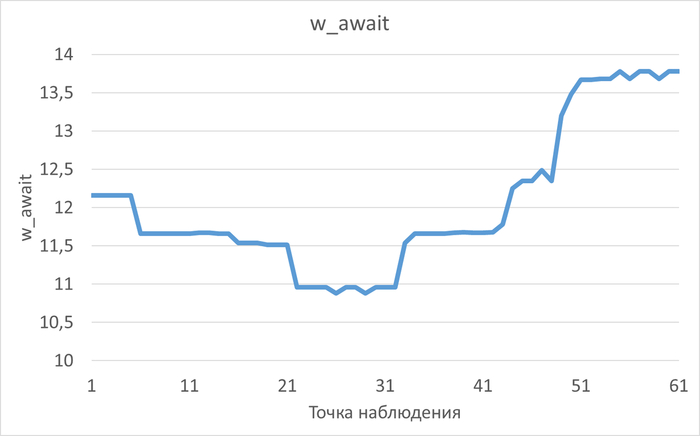
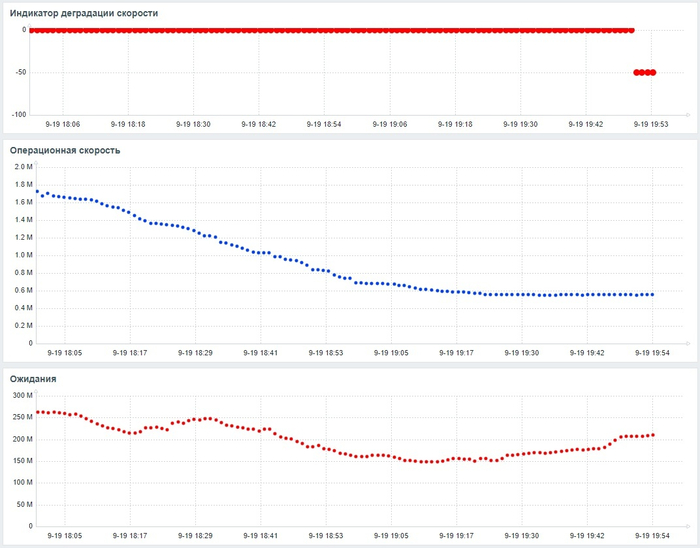
Операционная скорость и ожидания СУБД
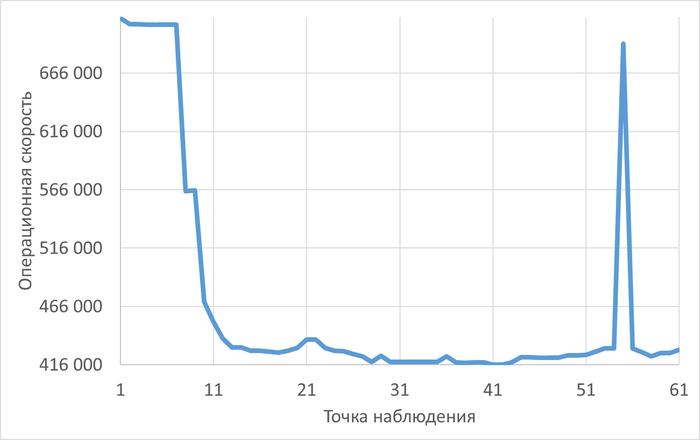
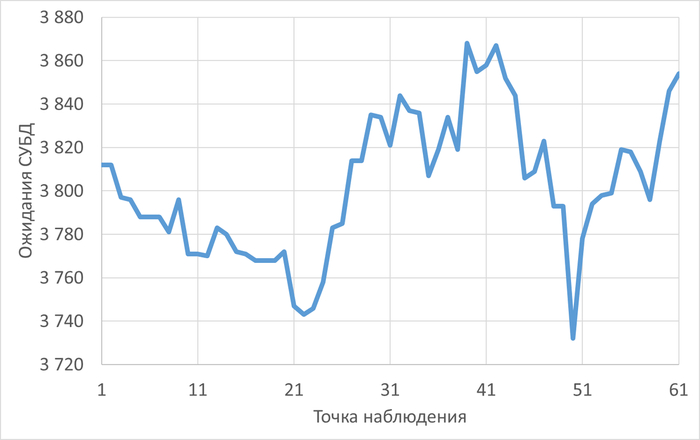
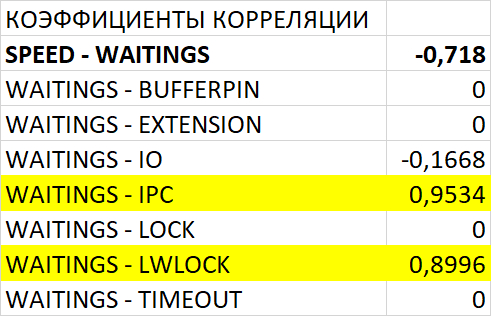
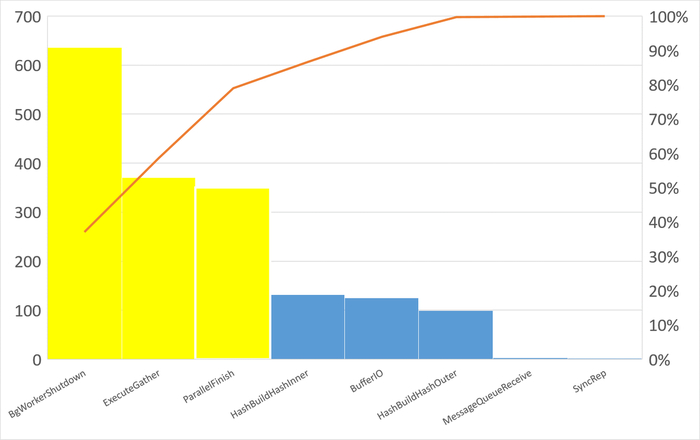
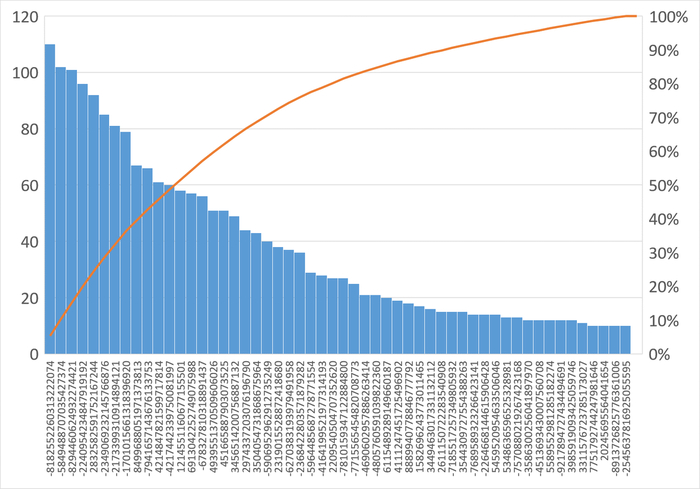
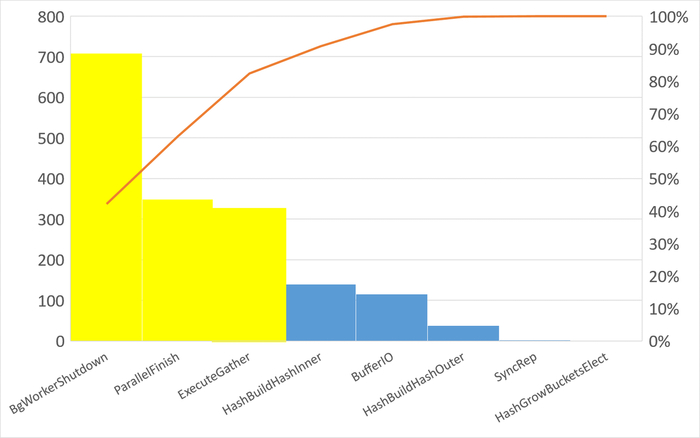
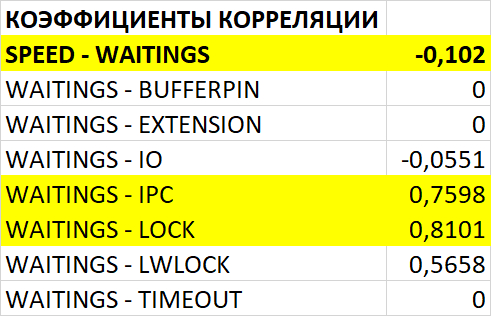
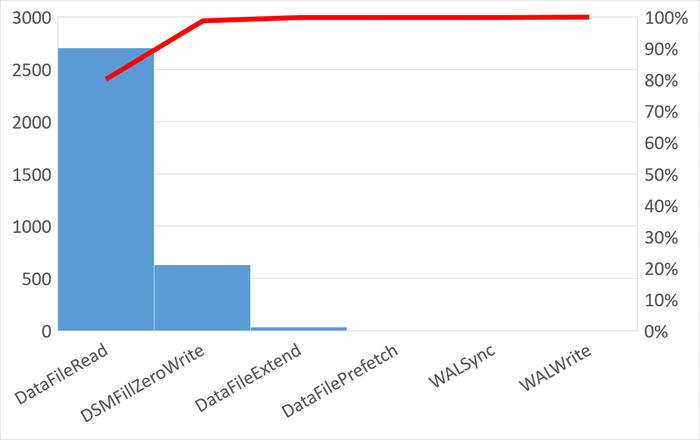
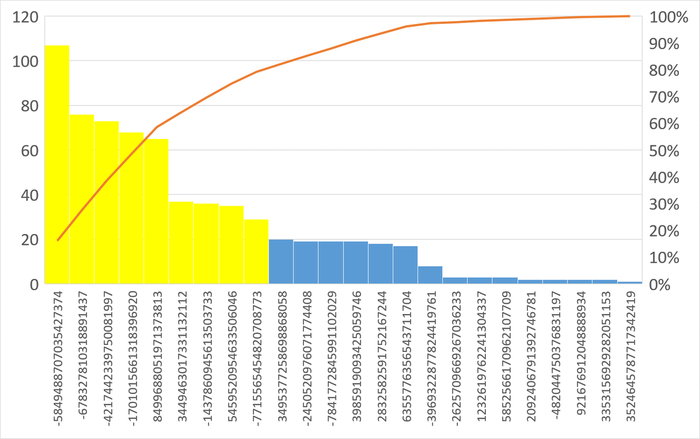
Диаграмма Парето по типу ожидания IPC
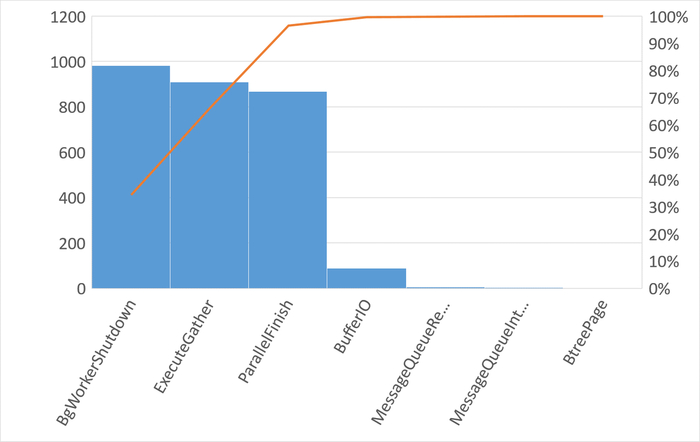
80% событий ожиданий :
BgWorkerShutdown: Ожидание завершения фонового рабочего процесса.
ExecuteGather: Ожидание активности дочернего процесса при выполнении узла плана Gather.
ParallelFinish: Ожидание завершения вычислений параллельными рабочими процессами.
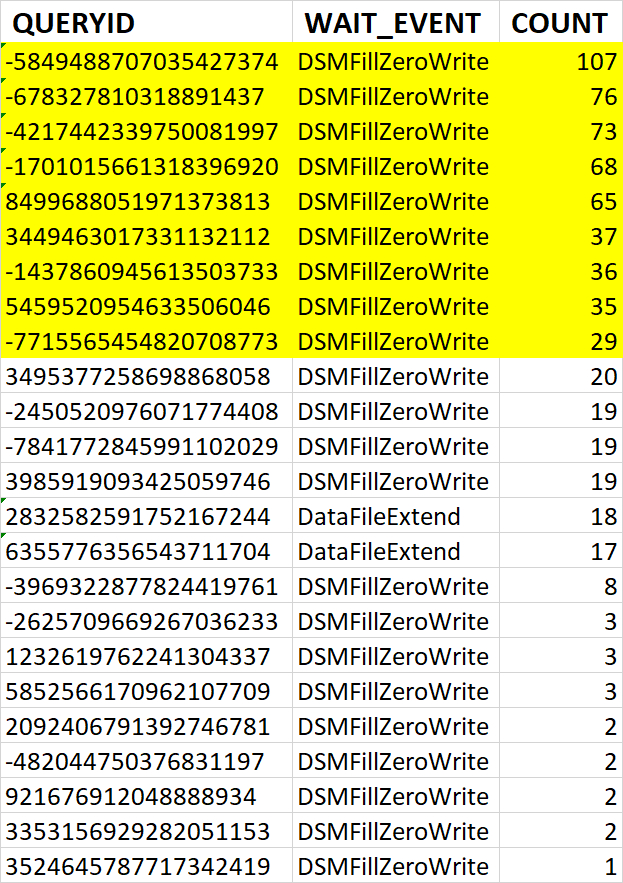
Результат анализа ожиданий на уровне SQL-запросов:
Наибольшее количество ожиданий IPC по запросу 6863414396188999698
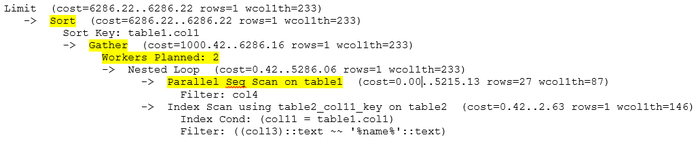
Оптимизация SQL-запроса
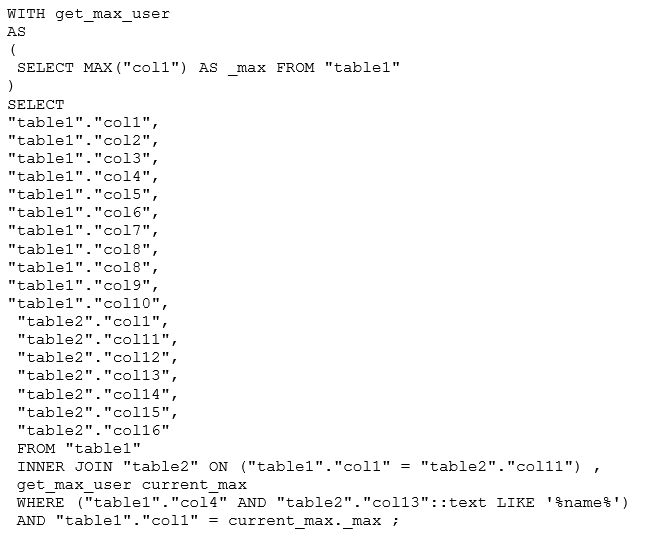
Измененный текст запроса
Детали и подробности: PG_HAZEL : Анализ инцидента производительности СУБД PostgreSQL , поиск и оптимизация проблемных SQL-запросов.
Операционная скорость и ожидания СУБД
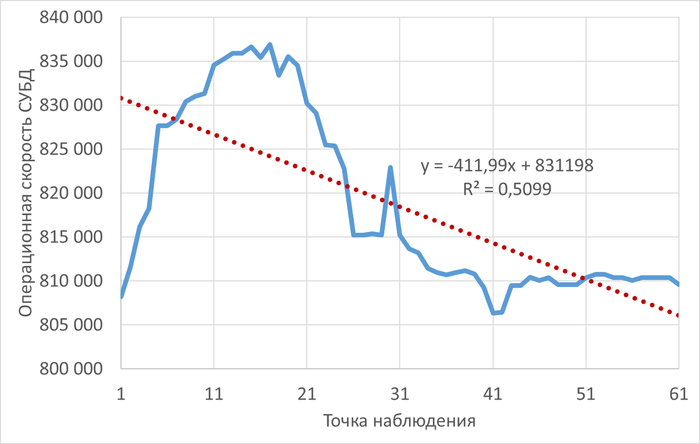
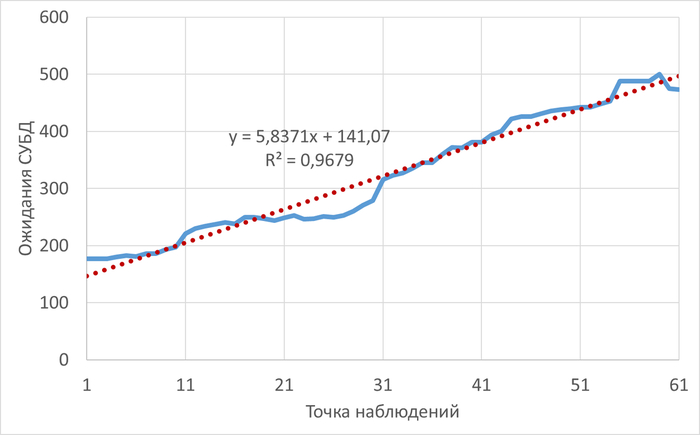
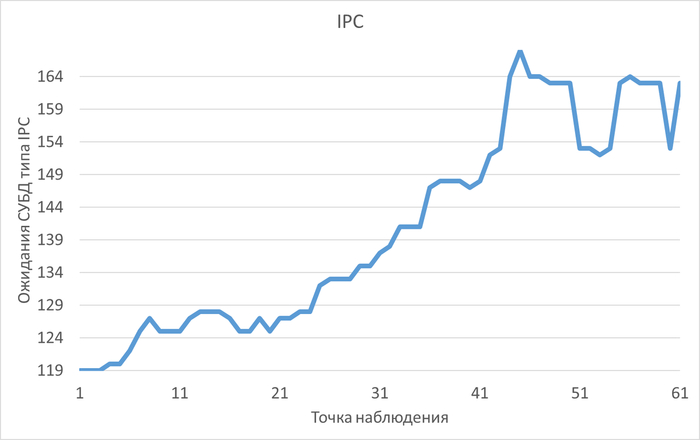
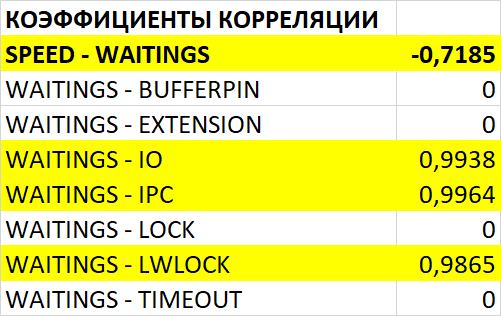
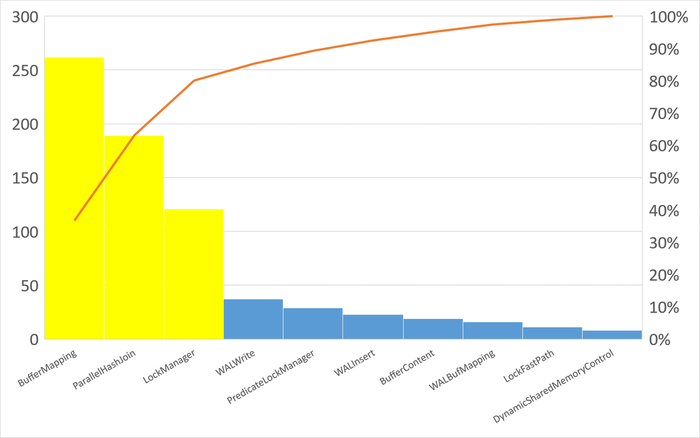
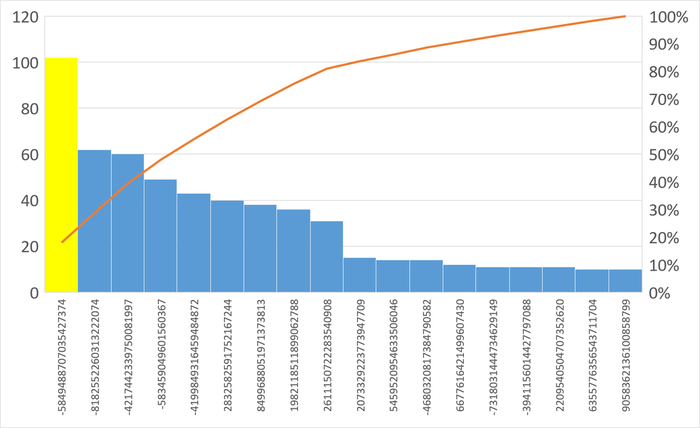
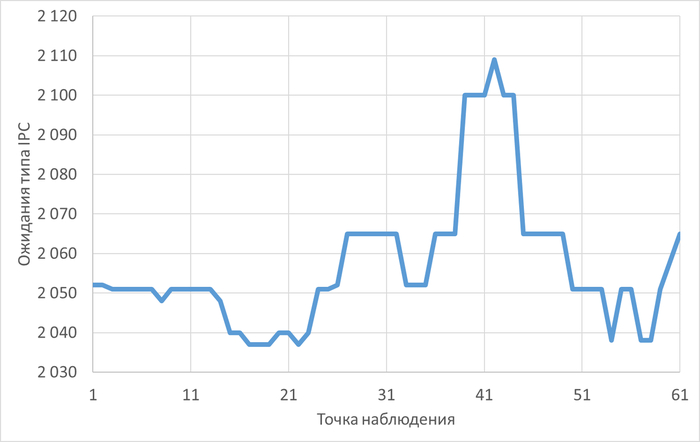
Ожидания типа IPC по SQL-запросам
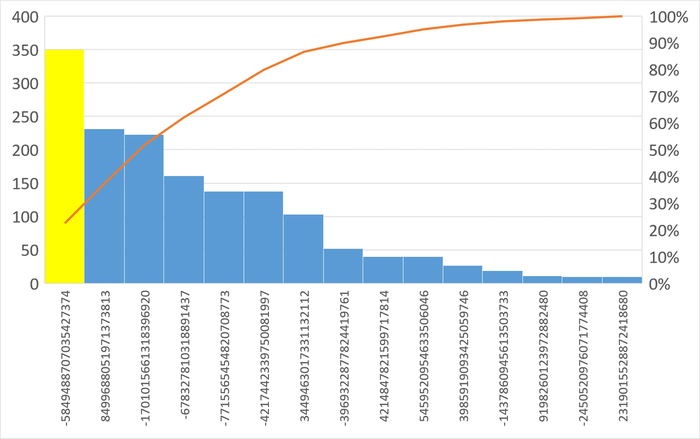
Наибольшее количество ожиданий типа IPC по SQL c queryid = -5849488707035427374
Переписать запрос с использованием CTE
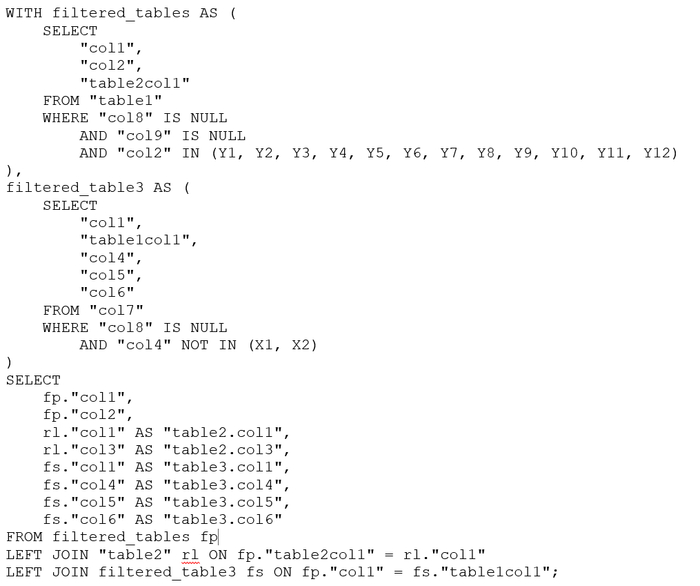
Детали и подробности: PG_HAZEL : Анализ инцидента производительности СУБД PostgreSQL , поиск и оптимизация проблемных SQL-запросов.
Операционная скорость и ожидания СУБД
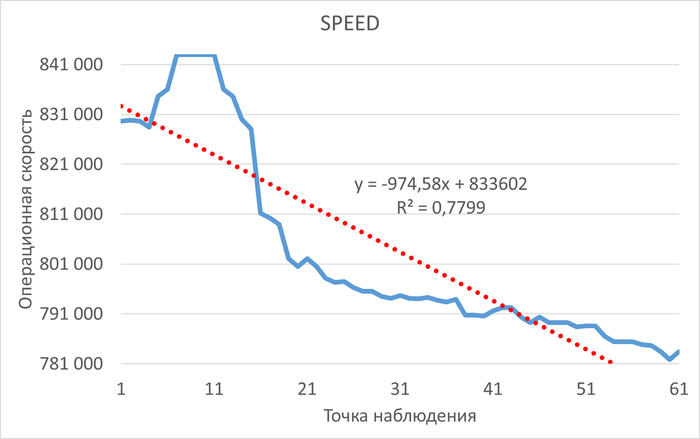
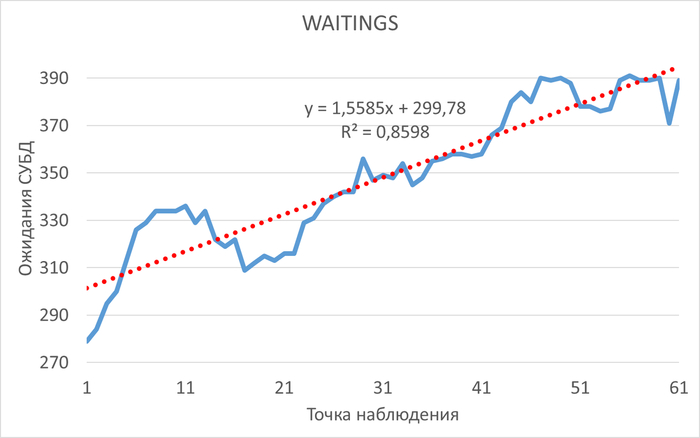
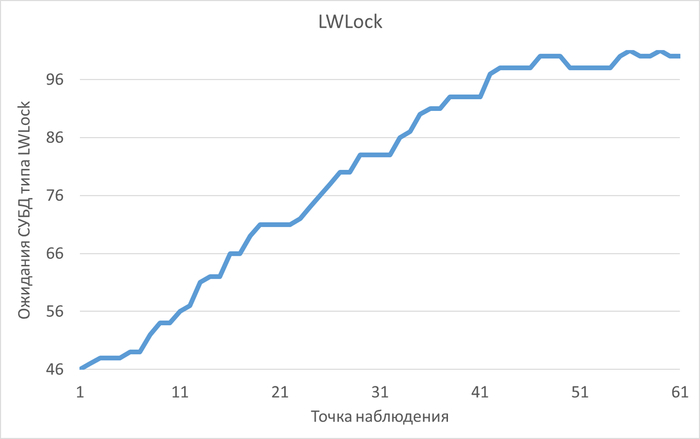
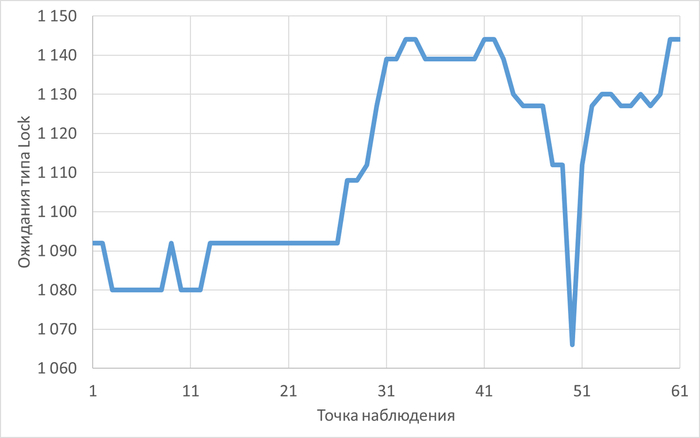
Ожидания типа IPC по SQL-запросам
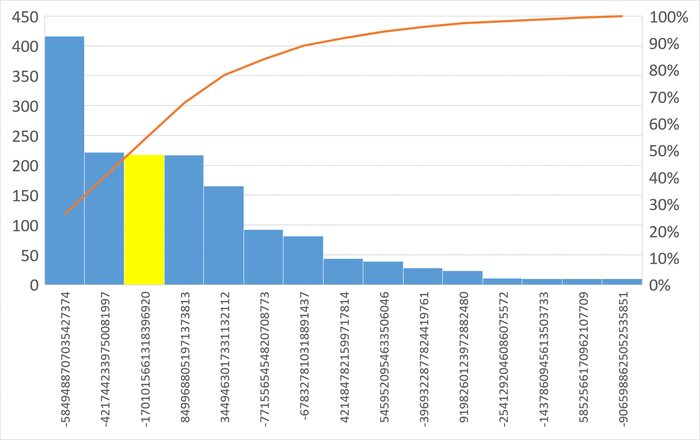
Следующий SQL-запрос для оптимизации : -1701015661318396920

Оптимизация структуры запроса
Основная проблема - "декартово произведение" из-за нескольких LEFT JOIN.
2.Формирование набора рекомендаций по оптимизации
Детали и подробности: Оптимизация SQL-запросов PostgreSQL : LIMIT 1
Создание подходящих индексов
Создать индекс по колонкам из WHERE и ORDER BY. Позволяет найти строку за несколько шагов.
Эффект
Кардинальное ускорение (в тысячи раз), устранение полного сканирования таблицы.
Анализ плана выполнения
Использовать EXPLAIN (ANALYZE, BUFFERS) для просмотра плана запроса. Показывает, используется ли индекс.
Эффект
Точно определяет "узкое место" в запросе, позволяет оценить стоимость операций.
Использование ORDER BY с индексом
Всегда использовать ORDER BY с LIMIT для предсказуемого результата. Упорядочивание должно совпадать с индексом.
Эффект
Гарантирует корректность результата и позволяет использовать индекс для сортировки.
Устранение лишних операций
Убрать ненужные DISTINCT, сложные вычисления в WHERE, избыточные JOIN. Снижает объем работы до применения LIMIT.
Эффект
Сокращает общее время выполнения, особенно если лишняя операция требовала сортировки.
Увеличение work_mem
Увеличить параметр work_mem, если в плане есть Sort с дисковыми операциями (Disk: writes temp).
Эффект
Ускоряет операции сортировки и хеширования, выполняемые в памяти.
Детали и подробности: Оптимизация SQL-запросов PostgreSQL : IN с большим количеством значений
Наиболее эффективные подходы заключаются в замене IN на более оптимальные конструкции и использовании специальных техник работы с данными.
ANY(ARRAY[]) вместо IN
Замена IN (...) на = ANY(ARRAY[...]).
Оператор ANY может остановить проверку при первом совпадении.
Когда метод эффективен
Когда список значений очень большой.
JOIN с виртуальной таблицей
Преобразование списка значений в виртуальную таблицу с помощью VALUES и соединение с основной таблицей.
Когда метод эффективен
Когда список значений можно представить как набор строк.
EXISTS вместо IN для подзапросов
Проверка существования записи с помощью EXISTS.
Запрос прекращает работу, как только найдет первое совпадение.
Когда метод эффективен
Особенно эффективен для коррелированных подзапросов и сценариев с NOT IN (лучше использовать NOT EXISTS)
Материализованные представления
Предварительный расчет и сохранение результатов "тяжелого" запроса, например, с DISTINCT.
Когда метод эффективен
Когда данные изменяются редко, а актуальность в реальном времени не критична.
Нормализация схемы данных
Вынесение часто запрашиваемых полей (например, make, vehicle_year) в отдельные справочные таблицы.
Когда метод эффективен
Когда одни и те же значения (DISTINCT ...) выбираются из таблицы миллионы раз .