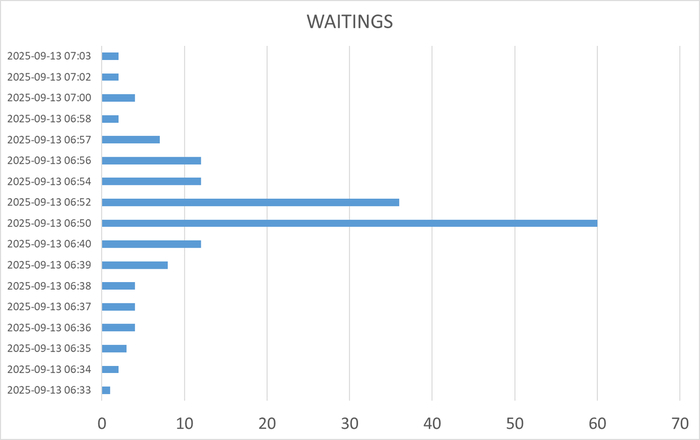
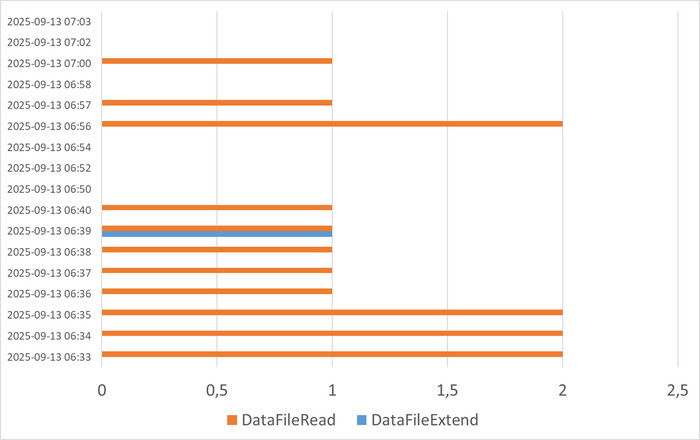
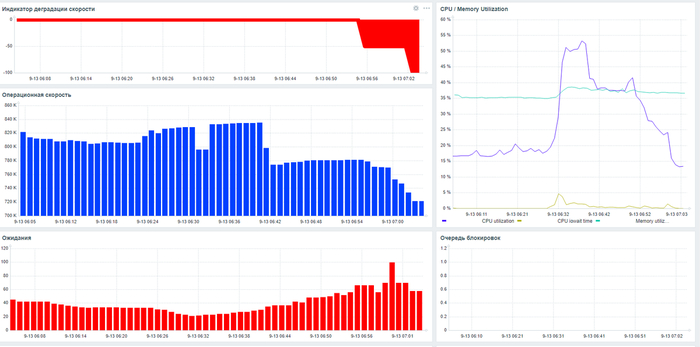
Экспериментально подтвердить корреляцию и причинно-следственную связь снижения производительности СУБД PostgreSQL и рост количества переключений контекста ОС (показатель cs метрики vmstat).
Рост cs/vmstat сильно коррелирует с ожиданиями блокировок (LWLock и heavyweight locks) в PostgreSQL. Эта корреляция не просто совпадение, а прямое указание на то, что снижение производительности вызвано конкуренцией за ресурсы и высокими накладными расходами ОС на переключение между задачами, которые не могут продвинуться из-за этой конкуренции.
В 99% случаев проблем с PostgreSQL первичны именно ожидания внутри СУБД (Locks, I/O). Резкий рост cs в vmstat — это важнейший сигнал и индикатор этих ожиданий на уровне операционной системы, который говорит о том, что процессы не работают, а ждут, и ОС тратит силы на переключения между ними. Поэтому при росте cs нужно сразу смотреть вглубь — на анализ wait events .
...
Вывод
Гипотеза о причинно-следственной связи ожиданий СУБД и количестве переключений контекста ОС - подтверждается экспериментально:
Первопричина (в СУБД) -> Ожидание (wait event) -> Реакция ОС -> Рост cs
Процесс инициирует ожидание: Сеанс PostgreSQL в процессе выполнения запроса достигает точки, где он не может продолжить работу без какого-то ресурса. Пример 1: Ему нужна страница данных с диска. Он инициирует операцию I/O и добровольно переходит в состояние сна (sleep), ожидая её завершения. Это регистрируется как wait event DataFileRead. Пример 2: Он пытается изменить строку, но другая транзакция удерживает на ней блокировку. Сеанс вынужденно переходит в состояние сна, ожидая освобождения блокировки. Это регистрируется как wait event lock.
Реакция планировщика задач ОС: Когда процесс PostgreSQL переходит в состояние сна (добровольно или вынужденно), он отдает свой квант времени процессора. Планировщик задач ОС фиксирует это и производит переключение контекста (cs), чтобы отдать освободившееся процессорное время другому готовому к выполнению процессу (например, другому сеансу БД или процессу самой ОС).
Результат: Таким образом, каждое ожидание внутри PostgreSQL (кроме ожидания CPU) приводит к тому, что процесс будет "усыплен", и ОС будет вынуждена выполнить переключение контекста, чтобы не простаивать. Чем больше сеансов одновременно находятся в состоянии ожидания, тем чаще ОС приходится переключаться между ними и другими процессами — рост cs.
📅 Дата публикации: 15 сентября 2025 года 📍 Место: Россия
Новая веха в мониторинге и диагностике производительности PostgreSQL
Комплекс PG_HAZEL представляет собой инновационное решение для глубокого анализа производительности СУБД PostgreSQL. Этот инструмент сочетает в себе методы статистического анализа, мониторинга в реальном времени и причинно-следственного моделирования, что позволяет точно определять корневые причины инцидентов производительности и прогнозировать потенциальные сбои.
PG_HAZEL использует методы корреляционного анализа для установления взаимосвязей между:
Метриками ОС (iostat, vmstat, использование CPU, памяти, дискового I/O).
Ожиданиями СУБД PostgreSQL (типы ожиданий IO, IPC, LWLock, и др.).
Тактический и оперативный анализ PG_HAZEL работает на тактическом уровне, анализируя влияние отдельных SQL-запросов на производительность СУБД. Он идентифицирует запросы, которые оказывают наибольшее негативное воздействие, и связывает их с конкретными типами ожиданий (IO, IPC, LWLOCK).
Многомерный анализ производительности PG_HAZEL интегрирует данные из различных источников, включая метрики ОС (iostat, vmstat), события ожидания PostgreSQL и статистику выполнения SQL-запросов. Это позволяет построить единую модель производительности и количественно оценить вклад каждого фактора в общую производительность СУБД.
Планируемое направление развития : причинно-следственный анализ и прогнозное моделирование, визуализация и интерактивные дашборды Используя методы причинности по Грэнджеру и байесовские сети, комплекс поможет выявляет не просто корреляции, а реальные причинно-следственные связи между метриками. Например, он может определить, что рост времени отклика диска (await) вызывает увеличение времени ожидания ввода-вывода в PostgreSQL, что приводит к деградации производительности. Используя методы ARIMA и машинного обучения возможно будет прогнозировать инциденты производительности СУБД PostgreSQL , таких как исчерпание дискового пространства или достижение критической нагрузки на CPU. Это позволит администраторам СУБД заранее принимать превентивные меры. Тепловые карты(heatmaps) корреляций и дашборды, позволят быстро выявлять аномалии и анализировать их в контексте всех метрик.
🚀 Практическое применение
PG_HAZEL уже успешно применяется для анализа инцидентов производительности в реальных условиях.
Кроме того, комплекс используется для нагрузочного тестирования, помогая определить предельные значения нагрузки, которые СУБД может выдержать без деградации производительности. 📈 Преимущества подхода
Раннее обнаружение проблем
Анализ метрик ОС позволяет выявлять потенциальные проблемы до их воздействия на производительность СУБД:
Точное определение корневой причины инцидентов значительно сокращает время восстановления:
Четкое разграничение проблем ОС и проблем СУБД
Возможность фокусирования на реальной причине, а не симптомах
📊 Примеры использования:
1.Рост ожиданий типа IO в PostgreSQL:
В ходе анализа инцидента производительности PG_HAZEL выявил, что наибольшая корреляция наблюдается между ожиданиями типа IPC и снижением операционной скорости СУБД. Это указало на проблему взаимодействия между процессами, что позволило администраторам быстро устранить причину.
2.Рост времени отклика дисков в iostat:
Начало инцидента: Рост утилизации CPU и значений iowait в метриках ОС
Корреляционный анализ: Выявление высокой корреляции между: - Ростом времени ожидания записи для устройств хранения (/data и /wal) - Снижением производительности СУБД - Ростом ожиданий типа IO в PostgreSQL
Заключение: Первичной причиной являлись проблемы на уровне дисковых подсистем
💬 Цитата разработчика
«PG_HAZEL — это не просто инструмент мониторинга, а экспертная система, которая превращает разрозненные метрики в понятные и осуществимые предложения. Наша цель — сделать диагностику производительности PostgreSQL максимально автоматизированной и точной».
🔮 Планы развития
В ближайших планах развития PG_HAZEL — разработка и внедрение методов причинно-следственного анализа и прогнозного моделирования.
📌 О компании
Разработчик PG_HAZEL специализируется на создании решений для мониторинга и анализа производительности СУБД PostgreSQL.
Наша миссия — помогать компаниям поддерживать высокую производительность и надежность их баз данных.
📞 Контакты для СМИ
Для получения дополнительной информации обращайтесь: Имя: Сунгатуллин Ринат Раисович Телефон: +7 927 245 80 49 Email: kznalp@yandex.ru Веб-сайт:https://dzen.ru/kznalp
💎 Заключение
PG_HAZEL устанавливает новый стандарт в мониторинге и диагностике производительности PostgreSQL. Его способность объединять данные из различных источников, выявлять корневые причины проблем и прогнозировать инциденты делает его незаменимым инструментом для администраторов баз данных и IT-специалистов.
Наибольшая корреляция между ожиданиями СУБД и типом ожиданий IO.
ALARM: более 50% наблюдений - Отклик на запись свыше 5мс
Вопрос
Какое событие является первичным - рост ожиданий чтения/записи в метрике iostat(проблемы устройства) или рост ожиданий типа IO в СУБД PostgreSQL ?
Ответ
Отличный и очень правильный вопрос, который затрагивает самую суть диагностики проблем с производительностью в связке СУБД-жесткий диск.
Короткий ответ: Первичным почти всегда является рост ожиданий чтения/записи в iostat (проблемы на уровне устройства). Рост ожиданий ввода-вывода (I/O wait) в PostgreSQL — это уже следствие этой проблемы.
В 1974 году инженеры IBM Дональд Чэмберлин и Рэймонд Бойс разработали первый прототип такого языка. Они назвали его SEQUEL (Structured English Query Language) — "структурированный английский язык запросов". Главная идея заключалась в том, чтобы сделать язык максимально похожим на обычный английский, чтобы даже люди без глубоких знаний программирования могли легко формулировать запросы к базе данных.
Пользователи PostgreSQL и Postgres Pro теперь могут сэкономить время при работе с базами данных. Разработчики из команды Postgres Professional создали ChatPPG — первый ИИ-бот для PostgreSQL. Он решает две ключевые задачи:
Быстрый поиск информации. Чат-бот анализирует вопросы пользователей и за секунды находит ответы в технической документации PostgreSQL (более 2800 страниц), Postgres Pro Enterprise, Postgres Pro Shardman и других продуктах компании. Это избавляет от долгого ручного поиска.
Генерация SQL-запросов. Достаточно описать задачу на русском или английском языке, и ChatPPG сформирует SQL-запрос. Это упрощает работу даже для тех, кто плохо знает синтаксис SQL.
Зри в корень ! Наука - поможет. Если есть инструмент.
Задача
Определить причины снижения производительности СУБД
Инцидент производительности СУБД
Дашборд мониторинга Zabbix
Начало инцидента 07:05.
Характерные признаки в ходе инцидента - рост утилизации CPU и значений cpu iowait.
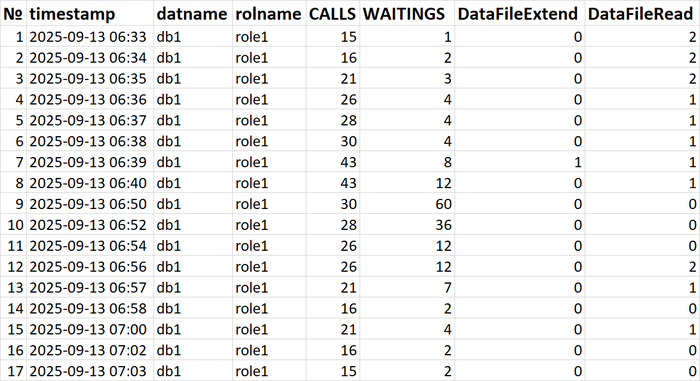
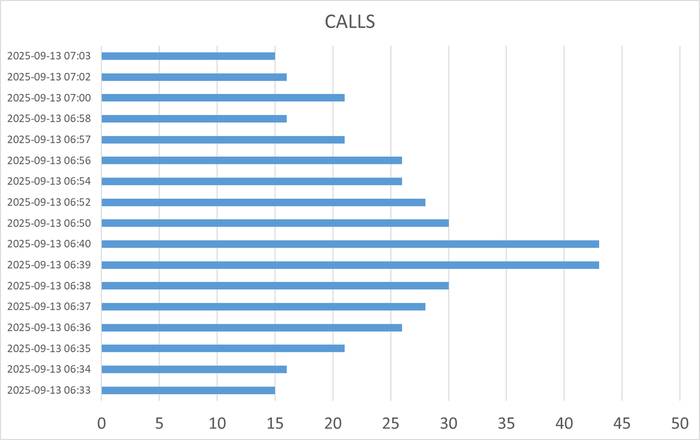
Результат статистического анализа производительности , ожиданий СУБД и метрик vmstat+iostat
Снижение производительности и рост ожиданий типа IO сопровождается ростом времени ожидания записи для устройств, используемых для файловых систем /data и /wal .
Cписок наиболее интересных и перспективных тем, логично вытекающих из уже проделанной работы.
1. Многомерный анализ и построение единой модели производительности (Unified Performance Model)
Суть: Объединить все имеющиеся источники данных (wait events PostgreSQL, метрики запросов, iostat, vmstat) в единую многомерную модель.
Цель — не просто найти корреляции, а количественно оценить вклад каждого фактора в общую производительность (например, во время отклика транзакции).
Методы:
Множественная регрессия: Моделирование времени отклика базы данных как функции от десятков метрик: cpu_util, await, pg_wait_events_1, ..., pg_wait_events_N.
Методы снижения размерности:PCA (Principal Component Analysis) для выявления латентных (скрытых) факторов, которые на самом деле управляют производительностью. Например, можно обнаружить, что 90% всех колебаний производительности объясняются всего 2-3 скрытыми факторами (условно, "Фактор дисковой подсистемы", "Фактор конкурентного доступа").
Ценность:
Понимание того, какая подсистема (СУБД, диск, CPU, память) является узким местом (bottleneck) в конкретный момент времени и насколько сильно она его ограничивает.
2. Причинно-следственный анализ и обнаружение корневой причины (Causal Inference & Root Cause Analysis - RCA)
Суть: Сделать следующий шаг после корреляции.
Корреляция говорит "эти два события происходят одновременно", а причинность — "одно событие вызывает другое". Это ключ к настоящей автоматизированной диагностике.
Методы:
Причинность по Грэнджеру (Granger Causality) для временных рядов: Позволяет с определенной долей уверенности утверждать, что изменение метрики A (например, await из iostat) предшествует и предсказывает изменение метрики B (например, DataFileRead wait event в PostgreSQL).
Байесовские вероятностные сети (Bayesian Networks): Более мощный метод для построения графа причинно-следственных связей между всеми метриками. Покажет, что высокий %iowait в vmstat влечет за собой рост ожиданий ввода-вывода в СУБД, что приводит к росту времени выполнения запросов.
Ценность:
Автоматическое ответ на вопрос "что стало первоначальной причиной проблемы?" при деградации производительности. Например, система могла бы выдавать alert: "Обнаружена проблема. Корневая причина: перегрузка дискового массива (метрика: await > 50ms), что привело к росту событий ожидания I/O в СУБД на 300%".
3. Прогнозное моделирование и предсказание сбоев (Predictive Analytics)
Суть: Использовать исторические данные, чтобы предсказать будущее.
Методы:
Прогнозирование временных рядов: ARIMA, Exponential Smoothing (ETS) или ML-модели (например, Prophet) для предсказания:
Времени исчерпания ресурсов: Когда закончится место на диске? Когда оперативная память будет полностью использована?
Наступления пороговых значений: Когда нагрузка на диск достигнет критического уровня, при котором время отклика СУБД превысит допустимый порог?
Классификация и прогноз инцидентов: На размеченных исторических данных (когда были сбои) можно обучить модель классификации (например, Random Forest или Gradient Boosting), которая по текущим метрикам будет предсказывать вероятность наступления инцидента в ближайшие N минут.
Ценность:
Превентивное реагирование. Возможность устранить проблему до того, как она окажет impact на пользователей.
4. Проактивное тестирование и анализ устойчивости (Chaos Engineering & Resilience Analysis)
Суть: Ваша система сбора метрик — идеальный инструмент для оценки того, как СУБД и вся система в целом ведет себя под нагрузкой и при сбоях.
Методы:
Планирование экспериментов (Design of Experiments - DoE): Целенаправленно создавать нагрузку (например, с помощью pgbench) и вносить возмущения (например, искусственно создавать I/O latency с помощью tc (traffic control) или нагружать CPU).
Анализ отклика системы: Смотреть, как ваши метрики (vmstat, iostat, wait events) реагируют на эти воздействия. Строить модели "нагрузка-отклик".
Ценность:
Понимание пределов устойчивости вашей системы. Ответ на вопросы: "Как поведет себя СУБД, если диски начнут отвечать в 10 раз медленнее?", "Какую пиковую нагрузку выдержит конфигурация до того как oom_killer убьет Postgres?".
5. Персонализированные рекомендации по настройке (Prescriptive Analytics)
Суть: Это вершина аналитики — не только диагностировать и предсказывать, но и рекомендовать конкретные действия.
Методы:
Системы рекомендаций: На накопленных данных можно обучить модель, которая будет предлагать изменить тот или иной параметр PostgreSQL (shared_buffers, work_mem, maintenance_work_mem) или ядра ОС (например, параметры виртуальной памяти) на основе выявленных паттернов.
A/B тестирование рекомендаций: Ваша же платформа может использоваться для проверки эффективности этих рекомендаций путем сравнения метрик "до" и "после".
Ценность:
Автоматизация рутинной работы по тонкой настройке (database tuning).
6. Продвинутая визуализация и интерактивный анализ
Суть: Предоставить инструмент для человеческого понимания всей этой сложной многомерной данных.
Методы:
Heatmaps корреляций и причинностей: Визуализация матрицы корреляций и графа причинно-следственных связей.
Cohort Analysis: Группировка инцидентов по типам (I/O bound, CPU bound, Lock contention) и анализ их частоты и тяжести во времени.
Интерактивные дашборды: Где можно кликнуть на пик на графике времени отклика и мгновенно увидеть, какие именно метрики на уровне ОС и СУБД вели себя аномально в этот момент.
Итог и рекомендация по приоритету:
Учитывая прогресс в работах, наиболее логичной и потенциально прорывной темой выглядит №2 — Причинно-следственный анализ.
Построена корреляция, теперь пришло время ответить на вопрос "почему?". Это именно тот рубеж, который отделяет просто мониторинг от экспертной системы диагностики. Реализация даже простых методов (как Грэнджера) на столь богатом наборе данных даст огромную практическую ценность.
Далее, естественным образом, можно перейти к прогнозной аналитике (№3), используя выявленные причинно-следственные связи для более точных предсказаний.