Прочитал тут забавную статью на хабре, как чипсы со вкусом кокоса защищают серверную инфраструктуру на Тайване.
Немедленно вспомнился Нильс Бор со своей ставшей уже бессмертной классикой – объяснением, почему он, Нобелевский лауреат, прибил подкову над дверью своего дома:
разумеется, я не верю, что подкова приносит удачу. Но я слышал, что она помогает независимо от того, верят в неё или нет.
За время своего нахождения в корпоративном ИТ я страдал от:
нарушения регламентов при замене оборудования администраторами, что мне пытались выдать за отказ системы кондиционирования.
Каждый раз было либо больно, либо очень больно. Наверняка были и ещё какие-то аварии, которые я не запомнил – у меня на месте запоминалки всё отгорело и осыпалось, и теперь там просто дзен-мозоль: пережили то, переживём и это.
Но вопрос введения в ИТ-культуру какого-то отечественного продукта в качестве талисмана, гарантирующего увеличение уровня доступности серверной инфраструктуры, давно назрел и перезрел. Надеюсь, в Минцифры осознают проблему и предложат централизованное, импортозамещённое решение.
Давайте попробуем предложить свои варианты? Условий, на мой взгляд, несколько:
зелёное;
запечатанное;
с чёткой датой окончания срока годности, чтобы его можно было менять, как сертификаты;
отвратительное на вкус, чтобы его с гарантией никто из админов не потребил.
С учётом всех ограничений на ум приходит лишь огуречный лосьон. Что думаете, товарищи админы?
Вот и я спрошу, а должен ли человек (системный администратор) следить за логами?
То есть, насколько будет эффективно, когда это делает именно человек? Даже мотивированный, добросовестный... Ну что, вот прям сидит такой и смотрит портянки логов, со всех сервисов, по утрам? Да ладно))
Не должны ли за логами этими следить роботы, ПО какое-то? И что человеку собственно делать, обнаружив что-то не то... "НЕ то" - бывает совершенно разное, нарушения, поломки, подозрительное поведение и прочее.
Да конечно есть какие-то протоколы, планы действий, (и то большой вопрос, есть ли у многих),...
В общем, сейчас пишу систему (один, помочь некому); и что с этим делать, ума не приложу, как всё автоматизировать, ну хотя бы нарушения, подозрительное поведение, (попытки взлома), отказ системы?
Хотя сам настраивал (fail2ban), на другом проекте, в принципе работает, в телегу инциденты о попытках взлома приходят. Но это капля в море, далеко не всё. Народ поднакидайте, мыслей, может системы какие есть? Может есть книга/видео-курс или ресурс где этому обучиться можно? Простите за ,может, сумбурность изложения.
Взлом МТС облака с простоем и потерей данных. Признание взлома? Нет. Публичный отчет? Нет. Рекомендации от МТС, регуляторов, консультантов по безопасности ? Нет. Взлом СДЭК. Смотри выше. Взлом Аэрофлота. Смотри выше. Взлом ПЭК.
и при этом, месяц назад на РБК вышло интервью с рассказом: не доверяйте подрядчикам, атака через цепь поставок – реальность,
Вы нашли в итоге уязвимость? Как они получили доступ?
Да, нашли. У нас был подрядчик, который работал с ВМС. У него был открыт порт, пароли слабые или вообще отсутствовали. Через этот порт они и вошли. Самое интересное — что они «копались» в нашей базе почти год до атаки. Нужно ли платить выкуп хакерам: личный опыт бизнесмена
Особенно смешно, что параллельно с взломом шли оптовые продажи страха, то есть SOC FORUM - Российская неделя кибербезопасности. С рекламой мероприятия через сайт Минсвязи, как же без этого.
Заключение
Имитация безопасности стоит в два раза дороже реальной безопасности. Потому что сначала вы платите за продукт имитационный, идентичный натуральному, а затем разгребаете последствия.
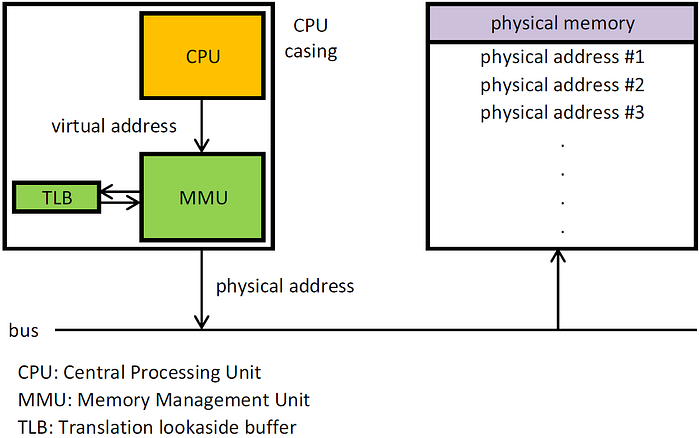
Linux использует подсистему виртуальной памяти как логический слой между запросами приложений на память и физической памятью (RAM). Такая абстракция позволяет скрыть от приложения всю возню с тем, как именно устроена физическая память на конкретной платформе.
Когда приложение лезет по виртуальному адресу, который ему «выставила» подсистема виртуальной памяти Linux, аппаратный MMU поднимает событие — мол, тут попытались обратиться к области, за которой сейчас не закреплена никакая физическая память. Это приводит к исключению, которое называется «ошибка страницы» (Page Fault). Ядро Linux обрабатывает её, сопоставляя нужный виртуальный адрес с физической страницей памяти.
Виртуальные адреса незаметно для приложения сопоставляются с физической памятью за счёт совместной работы железа (MMU, Memory Management Unit) и софта (таблицы страниц, Page Tables). Информация об этих сопоставлениях ещё и кэшируется в самом железе — в TLB (Translation Lookaside Buffer), чтобы дальше быстро находить нужные физические адреса.
Страница — это просто группа подряд идущих линейных адресов в физической памяти. На x86 размер страницы — 4 КБ.
Абстракция виртуальной памяти даёт несколько плюсов:
Программисту не нужно понимать архитектуру физической памяти на платформе. VM скрывает детали и позволяет писать код, не завязываясь на конкретное железо.
Процесс всегда видит линейный непрерывный диапазон байт в своём адресном пространстве — даже если физическая память под ним фрагментирована.
Например: когда приложение просит 10 МБ памяти, ядро Linux просто резервирует 10 МБ непрерывного виртуального адресного диапазона. А вот физические страницы, куда этот диапазон будет отображён, могут лежать где угодно. Единственное, что гарантированно идёт подряд в физической памяти — это размер одной страницы (4 КБ).
Быстрый старт из-за частичной загрузки. Demand paging подгружает инструкции только в момент, когда они реально понадобились.
Общий доступ к памяти. Одна копия библиотеки или программы в физической памяти может быть отображена сразу в несколько процессов. Это экономит физическую память.
Команда pmap -X <pid> помогает посмотреть, какие области памяти процесса общие с другими, а какие — приватные.
Несколько программ, потребляющих в сумме больше физической памяти, могут спокойно работать одновременно. Ядро втихаря выталкивает давно неиспользуемые страницы на диск (swap).
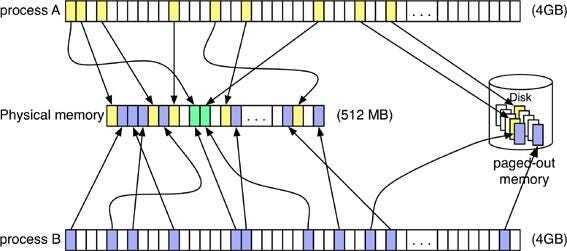
Каждый процесс живёт в своём отдельном виртуальном адресном пространстве и не может вмешиваться в память других процессов.
Два процесса могут использовать одинаковые виртуальные адреса, но эти адреса будут отображены в разные места физической памяти. А вот процессы, которые подключаются к одному сегменту общей памяти (SHM), получат виртуальные адреса, указывающие на одни и те же физические страницы.
Виртуальное адресное пространство процесса состоит из сегментов разных типов: Text, Data, Heap, Stack, сегменты общей памяти (SHM) и области, созданные через mmap. Адресное пространство процесса — это диапазон виртуальных адресов, который ядро «выдаёт» процессу как его среду исполнения.
Каждый сегмент — это линейный диапазон виртуальных адресов с началом и концом, за которым стоит какой-то источник данных (backing store): файловая система или swap.
Ошибка страницы обрабатывается так: ядро поднимает физическую страницу, заполняя её данными из backing store. Когда памяти начинает не хватать, данные из физических страниц, используемых как кеш, сбрасываются обратно в свой backing store. Сегмент Text у процесса опирается на исполняемый файл в файловой системе. А вот стек, куча, страницы COW (Copy-on-Write) и shared memory — это анонимные (Anon) страницы, их хранилище — swap (дисковый раздел или файл).
Если swap не сконфигурирован, анонимные страницы невозможно выгрузить — им просто некуда уходить. В итоге они оказываются «прибиты» к физической памяти, потому что перенести данные с этих страниц во время нехватки памяти некуда.
Когда процесс вызывает malloc() или sbrk(), ядро создаёт новый сегмент кучи в адресном пространстве процесса и резервирует диапазон виртуальных адресов, по которому он теперь может легально ходить. Любое обращение к адресу за пределами этих границ приведёт к segmentation fault — и процесс отправится в небытие. Выделение физической памяти при этом отложено: она будет выделена только когда процесс реально обратится к этим виртуальным адресам.
Пример: приложение сделает malloc() на 50 ГБ, но реально коснётся (то есть вызовет page fault) только 10 МБ. Тогда физической памяти уйдёт всего 10 МБ.
Посмотреть виртуальное/физическое потребление памяти можно через “ps”, “pidstat” или “top”. Столбец SIZE показывает размер виртуального сегмента, а RSS — объём выделенной физической памяти.
Физические страницы, которые используются для сегмента Text или для файлового кеша (page cache), можно освобождать быстро — данные всегда можно снова получить из backing store (файловой системы). А вот для освобождения анонимных страниц сначала нужно записать их содержимое в swap, и только потом страница может быть освобождена.
Политика выделения памяти в Linux
Выделение памяти процессам регулируется политикой распределения памяти в Linux. В системе есть три режима, и выбираются они с помощью настройки vm.overcommit_memory.
Это режим по умолчанию. Ядро позволяет процессам «переборщить» с запросами памяти в разумных пределах — как решат внутренние эвристики. Они учитывают свободную память, свободный swap, а также память, которую можно быстро освободить, ужав файловый кеш или slab-кеши ядра.
Плюсы: учёт довольно мягкий; полезно для программ, которые обычно запрашивают больше памяти, чем реально используют. Пока хватает свободной памяти или swap, процесс продолжает работать.
Минусы: ядро не резервирует за процессом физическую память заранее. Пока процесс не потрогает (не обратится к) каждую страницу, никакой гарантии выделения нет.
(знаю, что нынче сравнения в формате плюсы/минусы в статье приравниваются к генерации нейросети, но пока это всё еще лучший вариант описания, так что...)
2.Всегда overcommit (vm.overcommit_memory=1)
С этим режимом процесс может запросить сколько угодно памяти, и запрос всегда будет успешным.
Плюсы: никаких ограничений — можно делать огромные выделения, даже если физической памяти и swap мало.
Минусы: те же, что и в эвристическом режиме. Приложение может сделать malloc() на терабайты при наличии нескольких гигабайт RAM. Пока оно не тронет все страницы, проблем нет — но как только тронет, может включиться OOM Killer.
3.Строгий overcommit (vm.overcommit_memory=2)
В этом режиме ядро запрещает overcommit и резервирует не только виртуальный диапазон, но и физическую память. Нет overcommit — нет и OOM Killer.
При Strict Overcommit ядро отслеживает, сколько физической памяти уже зарезервировано или закоммичено.
Поскольку Strict Overcommit не учитывает свободную память или swap, ориентироваться на free или vmstat бессмысленно. Чтобы понять, сколько памяти можно ещё выделить, смотрят в /proc/meminfo на поля CommitLimit и Committed_AS.
Текущую границу выделения считают так: CommitLimit − Committed_AS.
Настройка vm.overcommit_ratio задаёт предел overcommit’а для этого режима. Предел считается так: PhysicalMemory × overcommit_ratio + swap.
Значение можно поднять, увеличив vm.overcommit_ratio (по умолчанию — 50% от RAM).
Плюсы: OOM Killer не сработает. Лучше, чтобы приложение упало сразу при старте, чем посреди боевой нагрузки от OOM Killer. Solaris работает только так. Strict overcommit не использует free memory/swap для расчёта лимита.
Минусы: overcommit отсутствует полностью. Зарезервированная, но не используемая память простаивает — другие приложения её потрогать не могут. Новый процесс может не получить память, даже если система показывает много свободной RAM — потому что она уже «обещана» другим процессам.
Мониторинг свободной памяти становится хитрее. Многие приложения под Linux не умеют корректно обрабатывать ошибки выделения памяти — это может привести к повреждению данных и странным, трудно отлавливаемым сбоям.
Примечание: и в эвристическом, и в строгом режиме ядро резервирует часть памяти для root. В эвристике — 1/32 от свободной RAM. В строгом — 1/32 от процента реальной памяти, который вы задали. Это зашито в ядро и не настраивается. Например, на системе с 64 ГБ будет зарезервировано 2 ГБ для root.
OOM Killer
Когда система упирается в жёсткую нехватку памяти — файловый кеш уже ужат до минимума, все возможные страницы возвращены — но спрос на память не падает, рано или поздно заканчивается всё, что можно выделить. Чтобы не оставить систему полностью без возможности работать, ядро начинает выбирать процессы, которые можно убить, чтобы освободить память. Этот крайний шаг и называется OOM Killer.
Критерии выбора «жертвы» иногда приводят к тому, что убивается самый важный процесс. Есть несколько способов снизить риски:
Выключить OOM Killer, переключив систему на строгий overcommit:
Исключить критический процесс из рассмотрения OOM Killer. Но даже это иногда не спасает: ядру всё равно нужно кого-то убить, чтобы освободить память. В некоторых ситуациях остаётся только автоматическая перезагрузка, чтобы восстановить работу системы.
Linux использует свободную память, которую сейчас не заняли приложения, для кеширования страниц и блоков файловой системы.
Память, занятую файловым кешем, Linux считает свободной — она доступна приложениям, как только им понадобится. Утилита free показывает эту память как свободную.
Наличие файлового кеша заметно ускоряет работу приложений с диском:
Чтение: когда приложение читает данные из файла, ядро делает физический IO и подтягивает блоки с диска. Прочитанные данные помещаются в файловый кеш, чтобы в следующий раз не ходить на диск. Повторное чтение того же блока — это уже логический IO (чтение из кеша), что резко снижает задержки. Кроме того, файловые системы выполняют упреждающее чтение (read-ahead): если замечают последовательный доступ, подгружают соседние блоки заранее, предполагая, что приложению они скоро понадобятся.
Запись: когда приложение пишет данные в файл, ядро кладёт их в page cache и сразу подтверждает запись (buffered write). Данные в кеше могут многократно обновляться (write cancelling), прежде чем ядро решит, что пора сбросить грязные страницы на диск.
Грязные страницы файлового кеша сбрасываются потоками flusher (раньше звали pdflush). Сброс происходит периодически, когда доля грязных буферов превышает пороговое значение — оно регулируется параметрами виртуальной памяти.
Функция HugeTLB в Linux позволяет приложениям использовать большие страницы — 2 МБ или 1 ГБ вместо стандартных 4 КБ. TLB (Translation Lookaside Buffer) — это аппаратный кеш, который хранит отображения «виртуальный → физический» адрес. Когда нужной записи там нет (TLB miss), приходится идти в таблицы страниц в памяти, а это дорогая операция.
TLB-хиты становятся всё важнее из-за растущего разрыва между скорости CPU и памяти, а также из-за увеличения объёмов памяти. Частые TLB miss могут ощутимо просадить производительность.
TLB — ограниченный ресурс на чипе, и ядро Linux старается использовать его максимально эффективно. Каждый элемент TLB может быть настроен на работу со страницами разных размеров: 4 КБ, 2 МБ или 1 ГБ.
Если те же слоты TLB использовать под страницы покрупнее, можно покрывать куда большие области физической памяти:
4 KB pages: 64×4 KB + 1024×4 KB ≈ 4 MB
2 MB pages: 32×2 MB + 1024×2 MB ≈ 2 GB
1 GB pages: 4 GB
Плюсы:
Большие страницы уменьшают количество TLB miss, потому что один TLB-слот покрывает больше адресного пространства.
Требуется меньше записей в таблицах страниц, и уровней таблиц меньше. Это сокращает задержки на обход таблиц (2 уровня вместо 4) и уменьшает память, расходуемую на сами таблицы.
Large Pages фиксируются в памяти и не участвуют в выгрузке при нехватке RAM.
Снижается частота page fault: один fault может заполнить сразу 2 МБ или 1 ГБ, а не жалкие 4 КБ. Приложение «прогревается» заметно быстрее.
Если у приложения есть локальность данных, HugeTLB даст выигрыш. Но если оно читает байт там, байт здесь, или прыгает по огромной хеш-таблице, то обычные 4 КБ-страницы могут быть выгоднее.
Улучшается работа механизма prefetch: крупные страницы устраняют необходимость перезапуска чтения на границах 4K.
Минусы:
Большие страницы требуют предварительного резервирования. Администратор должен заранее выставить количество страниц: vm.nr_hugepages=<число>
Для HugePages нужны непрерывные физические участки памяти — 2 МБ или 1 ГБ. На системе, которая работает долго, большая часть RAM может быть уже разрезана на 4К страницы, и запрос на HugePage будет просто нечем удовлетворить.
Стало интересно как можно сделать бота, которому можно указать беседу с непрочитанными сообщениями, чтобы он дал заключение по ним? Хочу избавить себя от нужны читать некоторые чаты, где можно пропустить что то важное, например чаты по дому или рабочие чаты без тематики - обычные "болталки", где помимо ерунда проскакивают важные вещи.
Кого-то насильно заставляют писать этот говно-софт, других заставляют им пользоваться. Это реально дурка какая-то.
Я добавлю в эту каплю ещё бочку: помогаю дошкольной организации, государственной, по IT, что там твориться, это тема для отдельного поста на сто500 страниц. Что я увидел сегодня, это не описать словами... Закупка новых компов, естественно, ты не можешь сам выбрать оборудование, (на самом деле можешь, за свой счёт), тэндеры-шмендеры, госзакупки... Привозят "компы" очередные(предыдущие были тоже комедийные), без слёз не взглянешь...
К монитору приколхожен компьютер и называется это безобразие "моноблок". Что бы вставить в него хвост, его нужно поставить "раком". Вишенка на торте: приколхоженный комп, подключен к монитору двумя хвостами, питания и HDMI Торчат хвосты просто из "дырки"(кабельные ввода/сальники, для приличия/безопасности -НЕ) и "суются" в гнёзда компуктера, загораживая при этом половину других гнёзд и "затрудняя" доступ к ним. Индикаторы HDD и POWER на корпусе, перепутаны местами, вайфай-модуль в "моноблок" не влез, поэтому в комплекте идёт кастрированный, Китайски, дешманский USB-свисток, можно ещё много про него чего рассказать, но уже хочется баиньки. Ежу понятно, что на рынке такое поделие просто не выживет, никто в здравом уме такое покупать не станет, зато можно "заставить" купить государственные организации, рукалицоджипег... Прошу, за ошибки сильно не пинать, чукча не писатель. "Дырка", "суются" и прочие словечки используются в описании нарочно, ибо по другому этот колхоз не описать...
UPD:
Я не ожидал такого ажиотажа, хотел просто комментарий написать, пикабу предложил пост, я и нажал ) Это мой первый пост)) Возможно минусящих было бы меньше, а может и наоборот, если бы я рассказал подробнее ситуацию, тут многое из контекста можно вырвать и перевернуть с ног на голову.
1. Я не работаю в этом саду, я приходящий друг/родственник эникейщик.(моя профессия смежная, я электромеханик АСУ) 2. Я никогда не имел дела с госзакупками и не хочу, особенно после этого поста. 3. В саду нет квалифицированно сотрудника способного написать ТЗ, ИМХО, он там и не нужен, это избыточно, хватит трёх сотрудников на район города, с парой десятков садов. 4. Эти сотруники есть, где-то...
Суть поста техническая, я описал конкретные косяки, конкретной железяки, конкретного поставщика, не более того.
Для лиги лени: продукт есть, но есть куда расти. Некоторые вещи вызывают недоумение. Медведь годный.
Годный медведь
Учебник по интиму часть 1. Введение Часть 2. Стоит только нам взять телескоп и посмотреть вооружённым глазом Часть 3. Давайте пробовать поставить Часть 4. Немного душноты Часть 5. Gitflic api Заключение
Учебник по интиму часть 1. Введение
Пришли ко мне в личку, в запрещенной в РФ сети, бывшие коллеги с вопросом, а знаю ли я, а могу ли я посмотреть, и им показать, что такое гитфлик (GitFlic). Я про такое первый раз слышу, потому что за импортозамещением в ИТ в РФ не слежу. Нет смысла следить за переименованиями, типа Debian 10-11-12 – Astra, Samba – ALD, Панголин – PostgreSQL, и так далее.
Тут вот, свой продукт.
Погуглил. На сайте новостей Минцифры – две рекламные статьи, обе от 2021 года: Первая - GitFlic. Российский GitHub и вторая, ответ на нее, «GitFlic: нас обвинили в «распиле». На этом все. Остальное – 3 рекламные статьи, и два треда на лоре «как это работает вообще без техподдержки». И, внезапно, статья от 1с – Инфостарт, Автоматизация процесса разработки с помощью сервиса GitFlic. Пока дописывал статью, нашлась еще одна минцифровая статья «Cборка Java-проектов в GitFlic Kubernetes-агентом»
GitFlic не является форком какого-либо решения. Он написан с нуля и создан без иностранного участия, поэтому не зависит от внешних факторов и сторонних разработок.
В отличие от GitLab и GitHub, которые разработаны на Ruby и Ruby on Rails, GitFlic написан на Java. Это обеспечивает стабильность и производительность даже для крупных проектов.
Это Java то про производительность? Ну ладно
В 2023 году продукт был куплен Астрой
ГК «Астра» продолжает реализацию стартовавшей в 2020 году M&A-стратегии и объявляет о вхождении в контур группы ООО «РеСолют», разработчика GitFlic —сервиса для работы с исходным кодом и его хранения. Сделка проводится в два неразрывных этапа, по завершении которых в конце текущего года ГК «Астра» получит мажоритарную долю 51%. Оставшаяся часть акций будет по-прежнему принадлежать основателям компании: Алексею Синицину, Максиму Козлову, Тимуру Миронову, Денису Рамазанову и Константину Леоновичу. Стратегические договоренности компаний предполагают, что в дальнейшем ГК «Астра» сможет еще увеличить свою долю в разработчике.
Ну был и был, мало ли чего скупила Астра.
Часть 2. Стоит только нам взять телескоп и посмотреть вооружённым глазом
Продукт позиционируется как комбайн с вертикальным взлетом – тут и хранение кода (вместо GitLab Self-Managed), и хранение итогов сборок вместо Maven (Реестр пакетов Maven), Nexus, и так далее. С релиза 3 объявили что «Релиз 3.0.0 отличается удобным интерфейсом, развитой функциональностью и способен стать полноценной заменой зарубежных продуктов GitHub, GitLab, Nexus, Artifactory, Jenkins и т.д.»
Пишут, что теперь работает и с OneScript (это для 1с). Обещают замену не только хранению кода, но и CI\CD, почти как в GitLab Runner или в GitHub Actions. В версии 4.6 пообещали что уже добавили: Проксирование реестра пакетов Deb Проксирование реестра пакетов Helm Прочее - 4.6.0 Что нового Обещают, что к проекту подключилось 100500000000 пользователей, но на этом все. Просто все. Зато в 4.4 отобрали манифесты:
Из стандартных пакетов убраны манифесты для k8s. На смену им пришли Helm Charts
При этом примеров «как это работает» и рассказов, кроме «мы внедрили, интерфейс красивый» - нет. Реклама есть. Сообщества нет. Примеров нет. Чат в телеграмме есть.
У продукта два исполнения – облачное и self-hosted. Облачное ни коллегам, ни мне не интересно, а на self-hosted можно и посмотреть.
Дальше я буду попутно сравнивать с GitLab Community Edition. Не потому, что он какой-то супер, а потому что я его видел, и с ним время от времени сталкиваюсь. У GitFlic Self-Hosted возможностей вроде сильно побольше, но посмотрим.
Все. На самом деле нет, если посмотреть Gitlab CE Self-compiled installation, то там английским по белому написано: In GitLab 18.0 and later, PostgreSQL 16 or later is required.
GitFlic Self-Hosted. Требует Redis и PostgreSQL. Зачем им редис – не понимаю. Но, GitLab Community Edition включает NGINX, Postgres, Redis, так что, есть и есть, как и у GitLab CE
Сама web страница загрузки (их репо) малость странное. Сверху указывается «N дней назад», и только внизу указано 2025-11-06, причем зачем-то этот фрагмент как-бы-защищен (нет) от выделения и копирования.
В реестре контейнеров последний бесплатный дистрибутив - gitflic-server-ce Бесплатный дистрибутив GitFlic Версия latest Опубликован 26 марта 2025 г.
Скачан целых 5 (пять) раз.
Дистрибутивы: Gitlab CE в варианте gitlab-ce_18.3.6-ce.0_arm64.deb. GitLab Community Edition (including NGINX, Postgres, Redis) Package Size 1.31 GB Installed Size 3.55 GB MD5 7244b435f26e74991f02a6525c4d3d26 SHA1 11c154d0bb4df6e9be39af864185d0cdfac7ea9e SHA256 6b3e1ae33d8dd89c7344338fc51f98e39d992b2c87e6b6e0167d91b496390868 SHA512 479be83c2f8eb0247637097e5b1863f2eafe1787ed9e9b843e470eed343e8328799187b5153d723b6c756405e64005fd9b4faa59da471ded412a259643e254cf
Дистрибутивы:gitflic .. все сложно. По ссылке – лежит описание по 4.6.0 По другой ссылке Лежит короткий readme, ссылка на сам файл gitflic-server_onpremise_4.6.0.zip, и ничего кроме. MD5 ? SHA? Не завезли. Ссылку для wget ? Не завезли.
Файл gitflic-server_onpremise_4.6.0.zip размером 780590717 байт. MD5 25C91261305A3EDA778684363D1D9D4F SHA256 67DE3A8EFAD516DB39196E9DA6726E4A5287D51F60950951C62106C22CC4301D
На момент начала написания статьи обновление вышло буквально вчера (статья писалась почти 2 недели, работы привалило, откуда не ждали). Буду смотреть сразу свежее.
Часть следующая, давайте пробовать офлайн
У дебиан опять поменялась страница загрузки, так что, например, отсюда https://cdimage.debian.org/debian-cd/current/amd64/iso-dvd/ берем debian-13.2.0-amd64-DVD-1.iso Тестовая VM, 2 vCPU, 4 Гб памяти, 45 Гб жесткий диск, Debian 13. Next-next-без графики-готово-забираем обновления – готово. Правим /etc/network/interfaces и /etc/apt/sources.list Заодно правим /etc/sysctl.conf от ipv6 и /etc/resolv.conf для DNS Убеждаемся в том, что по неведомым причинам /usr/sbin/ так и не прописан в путях по умолчанию, делаем ребут. /usr/sbin/shutdown
Смотрим – получилось меньше 5 Гб всей виртуальной машины. Заливаем туда gitflic-server_onpremise_4.6.0.zip, отключаем сеть на уровне гипервизора и идем читать инструкцию
В инструкции куча слов про создание папок и установку из zip, но ни слова про то, что jar файлы по умолчанию запускать нечем. Между тем, ПО идет как jar - gitflic.jar, размером 444275979, MD5 7ADC17898B22007B71C8C3D305777B42 SHA256 19468BAE05E83ADB6F56792C7BB6C946CE40CFD2F35F47B72BF77CAF879DF7B4
Поэтому, кроме упомянутого в руководстве apt install unzip , нужно сделать и apt install default-jdk. Еще в инструкции по установке везде стоит sudo, его тоже нет в debian по умолчанию. Хотите – ставьте. Дальше хотелось бы делать по инструкции, но так не выйдет. Потому что инструкцию надо было читать с самого начала, раздела «Предварительные условия», а не как я, сразу перейдя к установке приложения.
В предварительных условиях указано: OpenJDK 11 default-jdk на момент написания статьи - openjdk 21.0.9 2025-10-21, OpenJDK Runtime Environment (build 21.0.9+10-Debian-1deb13u1)
Затем, везде в инструкции стоит использование sudo. Его по умолчанию нет в Debian, поэтому apt install sudo
В инструкции указан PostgreSQL 11. Последняя версия, 11.22, вышла два года назад, 2023-11-09. Актуальная версия – 18.1, или хотя бы 17.7. А тут 11.
и дальше пойдем по инструкции из раздела Астры для PostgreSQL 11. Файла мандатного доступа etc/parsec/mswitch.conf у меня нет, и хорошо. В инструкции в пути мелкая опечатка, и в части установки расширений забыли написать \q дальше ставим Redis, ну или keyDB. Я поставил Redis - apt install redis, redis-cli ping отработал.
Остается сразу перевесить порт сервера с 22 на, скажем, 1122. Найду конфиг find / -name "sshd_config" , и поправлю. Потом ребут, и
Перейду к самой установке по инструкции mkdir /tmp/gitflic unzip gitflic_*.zip -d /tmp/gitflic – эта команда не сработает с ошибкой unzip: cannot find or open gitflic_*.zip, gitflic_*.zip.zip or gitflic_*.zip.ZIP.
for d in cicd repo img releases registry; do sudo mkdir -p "/var/gitflic/$d"; done; эта команда .. ну, я от рута делал, так что на sudo ругнется. sudo mkdir -p /opt/gitflic/bin sudo mkdir -p /etc/gitflic sudo mkdir -p /var/log/gitflic sudo cp gitflic.jar /opt/gitflic/bin sudo cp application.properties /etc/gitflic/application.properties sudo mkdir -p /opt/gitflic/cert sudo ssh-keygen -t ed25519 -N "" -q -f /opt/gitflic/cert/key.pem
И так далее. Шаг 13, конечно, тоже не сработает – нужно не useradd, а /usr/sbin/useradd --no-create-home --system --shell /sbin/nologin gitflic
Дальше в инструкции идет раздел «Конфигурация SSH порта». На .. то есть – зачем? Раздел «Конфигурация SSH порта» ссылается на следующий раздел, «Конфигурация и запуск». Это многое объясняет. Если же читать инструкцию с начала, а не с середины, то в разделе «Предварительные условия» написано – зачем:
Для того, чтобы было возможным использовать remote-url вида git@gitflic.ru:gitflic/gitflic.git, необходимо освободить стандартный 22 порт ssh сервера!
Раздел написан корректно, но можно чуть-чуть улучшить. Например, переписав весь список главы «установка под Астру» в раздел «просто установка». Но, можно и не переписывать, продукт куплен Астрой.
Все бы хорошо, но нельзя просто так и сделать только по инструкции. Не работает. Например, сделав systemctl status gitflic-server.service видно, что сервис есть, а веб консоли – нет. Почему? Потому что надо смотреть инструкцию лучше, сервис по умолчанию стартует как [::ffff:127.0.0.1]:8080
В инструкции написано:
После запуска перейдите по адресу, указанному при конфигурировании и проверьте работоспособность сервиса
Но в инструкции нет пункта «адрес конфигурации». Точнее, в самом начале инструкции указано: Перед конфигурацией приложения, ознакомьтесь с назначением параметров на странице Конфигурация application.properties
По пункту 9 инструкции по установке понятно, что параметры лежат в /etc/gitflic/application.properties, и внутри там написано # Дефолтное значение адреса localhost server.address=127.0.0.1 gitflic.base.url=http://localhost:8080 . Заодно и логи указано где хранить, logging.file.name=/var/log/gitflic/server.log
Ну, окей, все понятно, слушаем на локалхосте. Ничего такого. Там же указано: # При необходимости также можно указать порт, на котором будет запущен SSH сервер для работы # SSH транспорта git. Дефолтное значение порта 22 ssh.server.port=2255
Ничего не понятно, но очень интересно.
Ну да ничего. Правим в конфиге IP и делаем systemctl restart gitflic-server.service. Перезапускается пару минут (в ограниченной по ресурсам виртуалке), и появляется WEB консоль. Медведь хороший, мне нравится! Настолько хороший, что я выкинул из черновика картинки Kadabrus. Остается зайти: Стандартный пользователь и пароль Почта - adminuser@admin.local Пароль - qwerty123
Зашло. Работает. И даже работает после перезагрузки.
Итого по установке Медведь выбран удачно. Инструкция достаточна для установки. Есть мелкие недоделки, типа пропущенного в одном месте слеша, или \q для выхода из psql, но ничего критичного. PostgreSQL 11 надо менять на 16, 17 или лучше сразу 18. 11 – устарел. JDK тоже указан старый. В инструкции по LDAP авторизации сделано что-то не очевидное, но сейчас с этим разбираться лень
Часть 4. Немного душноты
С чем у коллег проблемы? Проблемы с тем, что они не разработчики, и им Git не нужен. Зато нужно брать секреты из Vault, и забирать к себе готовые плейбуки, ямл, открытые ключи, скрипты и так далее. И, кстати, контейнеры. Что умеет забирать файлы из онлайна? Если говорить про Linux, то это curl, wget, docker - docker push, далее со всеми остановками вроде Automate Ansible With GitLab и Build enterprise-grade IaC pipelines with GitLab DevSecOps. Если говорить про Windows, то есть Desired State Configuration, но иногда людям хочется интима и единообразия, так что мы получаем invoke-webrequest и Invoke-RestMethod. И то и другое относится к (кажется) System.Net.Sockets, но про это не будем. В Windows есть и wget, но это оболочка для invoke-webrequest, и есть два curl: один как командлет, и отдельный curl как честный curl.exe. Вот с этим всем и надо попробовать, как чего работает.
Начало простое: Отправка любого REST-API метода требует авторизации. Для этого необходимо создать токен доступа и указать его в заголовке запроса в следующей форме .. Создам проект MyNewproject01, в нем ветку master, в нем файл myfile01 с содержанием content01.
Для создания токена доступа через интерфейс необходимо: Перейти в профиль пользователя Перейти в раздел API токены Нажать кнопку Создать
Сказать что инструкция «не очевидная» - это ничего не сказать. Профиль пользователя виден и в левом меню, и в правом верхнем. И токены API генерируются в правом верхнем меню
Вот сюда не надо!
СЮДА НЕ НАДО
Надо вот сюда!
Надо вот сюда!
Токены то есть, но токена «чтобы только читал» там нет. В Gitlab сделано понятно, надо дать read_repository: Grants read-only access to repositories on private projects using Git-over-HTTP or the Repository Files API. read_user (Grants read-only access to your profile through the /user API endpoint, which includes username, public email, and full name. Also grants access to read-only API endpoints under /users. ) read_api (Grants read access to the API, including all groups and projects, the container registry, and the package registry.)
а тут как? Просмотр информации о пользователе – ну, допустим. Просмотр информации о проектах пользователя – окей, Просмотр информации о реестре пакетов Создание пакетов реестра Удаление пакетов реестра
Где простой read_repository_only ? Дам все права сразу, потом разбираться буду.
Замечу, что кроме API токенов и транспортных токенов, в проекте есть еще какие-то токены развертывания, но перечня «есть три типа токенов» в руководстве нет. Или где-то дальше, как транспортные токены.
Впрочем, не важно. сообщение про токен читаемое, в моем случае:
Скопируйте токен. Он показан один раз и при перезагрузке страницы его получить иными способами не получится: af71db42-9683-40b4-b615-d31c9e5f7a16
Что с ними делать?
Для того, чтобы создать REST-API запрос, необходимо обратиться на определенный адрес (endpoint), который должен иметь следующее начало:
api.gitflic.ru для работы с API на gitflic.ru localhost:8080/rest-api для работы с API в self-hosted сборках
Домен и порт при работе с self-hosted решением могут отличаться.
Для взаимодействия с публичным API GitFlic необходимо указать полученный access token в заголовке запроса в следующей форме: Authorization: token <accessToken>
Что мешало написать пример для curl или хоть чего-то?
Делаем пример 01: Invoke-WebRequest -Uri 'http://192.168.21.61:8080/rest-api' -Method 'GET' -Headers $headers01 –Verbose Получим ошибку: Specified value has invalid HTTP Header characters. Parameter name: name
Делаем пример 02: Invoke-WebRequest -Uri 'http://192.168.21.61:8080/rest-api' -Method 'GET' -Headers $headers02 –Verbose Очевидно, тут в токене сознательно сделана ошибка, и результат: The remote server returned an error: (403) Forbidden.
Делаем пример 03 Invoke-WebRequest -Uri 'http://192.168.21.61:8080/rest-api' -Method 'GET' -Headers $headers03 –Verbose Результат: VERBOSE: GET with 0-byte payload Invoke-WebRequest : The remote server returned an error: (404) Not Found.
Ну … ладно. Оно, допустим, работает, но можно же было бы и вернуть «токен ОК, а дальше не знаем». Но ответ (404) Not Found - пугает.
Можно же было сделать пример для запроса «токен ок, запросите чего-то еще». Валидации токена не хватает. Или я не искал и не нашел. А он – есть.
Ответ содержит вполне понятный строчный объект, типа {"disableLdapAuth":false,"disableSamlAuth":false,"disableOidcAuth":false, и так далее}
Уже неплохо. Наверное, его можно даже распарсить в какой-то объект, но это не является темой для статьи
Через curl тоже работает: curl.exe --verbose --header "Authorization:token af71db42-9683-40b4-b615-d31c9e5f7a16" $Ad03 Ключ --verbose, конечно, мне был нужен только для отладки, и в таком виде только для читаемости Так что в windows можно делать $Ret032 = curl.exe --header "Authorization:token af71db42-9683-40b4-b615-d31c9e5f7a16" $Ad03
Ответ несколько непредсказуем. Заголовок – есть, ответ StatusCode: 200 есть, а внутри – ничего нет. Ни массива, ничего. Потому что публичных проектов у меня нет. Хотя бы вернули 200, а не (404) Not Found.
Метод для получения содержимого файла GET /project/{ownerAlias}/{projectAlias}/blob?commitHash={commitHash}&file={fileName} Запрос возвращает содержимое файла, который был изменен в указанном коммите, строкой. Если размер файла больше, чем 15МБ, или же он бинарный/картинка необходимо использовать следующий метод commitHash. Обязательный параметр. Хэш коммита, который хранит необходимое состояние репозитория
И как это понимать? Какой еще хеш коммита? Зачем ? Сравните для Gitlab :
И вот это. Какой еще коммит? Если мне надо не коммит, а всегда latest, то что?
Но, метод работает. Одна проблема, где взять хеш коммита. И вторая, как указать ветку, видимо по хешу. Очень странно. С хешем просто. Его можно получить двумя способами. Первый способ, простой. Нужно зайти в историю коммитов файла в GUI и справа будет 7 значный (почему 7 ?) номер коммита
Второй способ, чуть сложнее. Нужно ткнуть на RAW, откроется длинная ссылка вида http://192.168.21.61:8080/project/adminuser/mynewproject01/blob/raw?file=myfile01&commit=9e12345(длинный хвост) Первые 7 цифр в ID коммита – хеш. Остальное – даже не представляю, UUID какой-то.
--verbose, конечно, мне был нужен только для отладки, и в таком виде только для читаемости
Метод для получения списка файлов GET /project/{ownerAlias}/{projectAlias}/blob/recursive?commitHash={commitHash}&directory={directory}&depth={depth}
Запрос возвращает список файлов с информацией о них, начиная с определенной папки и до определенной глубины. Папки не возвращаются.
Опять commitHash. Опять «Обязательный параметр. Хэш коммита, который хранит необходимое состояние репозитория».
Заключение
Приложение работает, API работает. Документация вызывает ряд вопросов, но их уже без меня пусть бывшие коллеги решают. Получение файла и чего угодно вообще через хеш коммита, а не последней (текущей) версии файла выглядит крайне странно. Как и часть инструкции, где этот хеш коммита упомянут, а где его брать – нет. Не очевидно оформляется токен, где не совсем понятно, как сделать read_repository_only Как это будет работать с докером, ансиблом, и так далее – не проверял, и не хочу. Наверное, как-то работает.
PS. Пока писал статью: оказалось что дело было не в бобине, и коллеги и сами справились. Просто у них опять кое-кто накрутил с сертификатами, проверками, и прочей безопасностью, и не сознавался. Пока писал статью: программа набрала 10000000 очков в рейтинге - GitFlic признана лидером среди российских DevOps-платформ по версии CNews.