PG_HAZEL : Влияние уменьшения autovacuum_vacuum_threshold на производительность СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Разобраться в работе сложного механизма - это очень интересно.
Задача
Проанализировать количественное влияние на производительность СУБД повышения агрессивности настройки autovacuum для очень большой таблицы .
Начало работ
Конфигурация СУБД
CPU = 200
RAM = 1TB
DB Size = 10TB
Количество строк тестовой таблицы ~7 000 000 000
Сценарий нагрузки - смешанный ("Select only" + "Select + Update" + "Insert only")
Минимальная нагрузка = 5 сессий
Максимальная нагрузка = 115 сессии
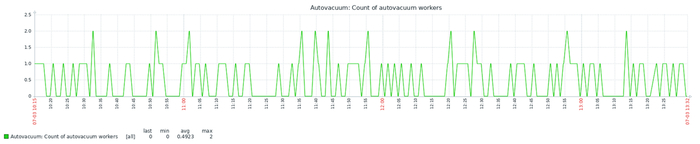
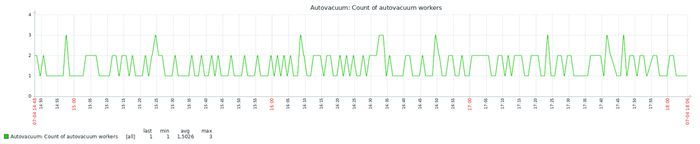
Эксперимент-10K : агрессивные настройки autovacuum
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_insert_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_cost_delay = 0);
Эксперимент-1K : агрессивные настройки autovacuum
Снижение граничного условия в 10 раз.
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 1000);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_threshold = 1000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 1000);
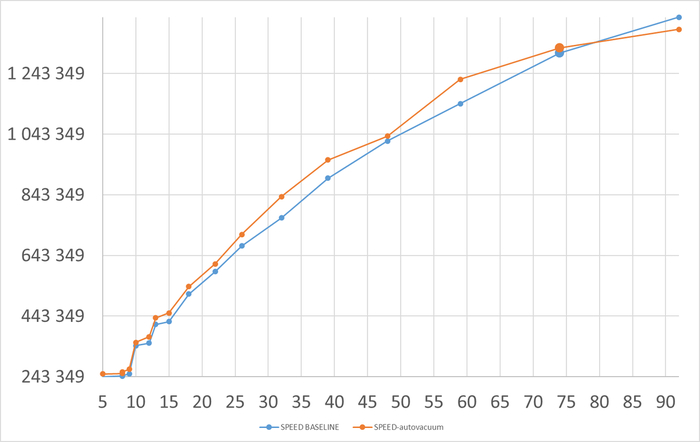
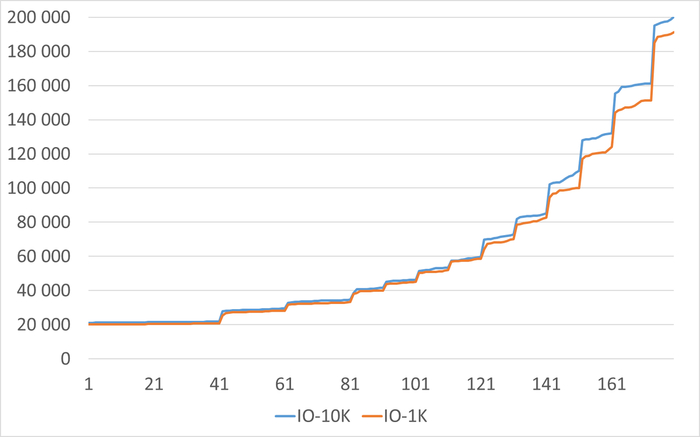
Операционная скорость

Ось X - точка наблюдения. Ось Y - операционная скорость

Ось X - точка наблюдения. Ось Y - относительная разница между скорости в эксперименте-10K и эксперименте-1K
Средний прирост производительности СУБД в эксперименте-1K = 9.5%
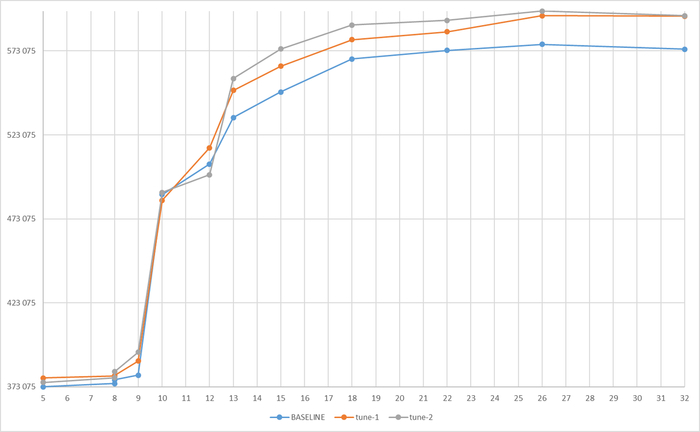
Ожидания СУБД

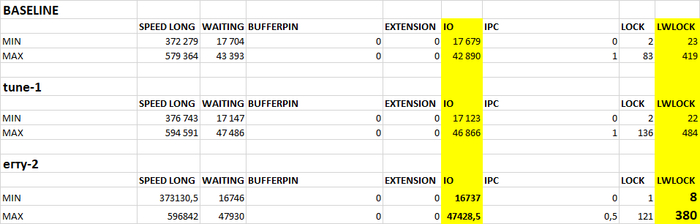
Сводная таблица предельных значений и корреляции ожиданий СУБД.

Ось X - точка наблюдения. Ось Y - ожидания СУБД

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Среднее снижение количества ожиданий СУБД в эксперименте-1K = -4.51%
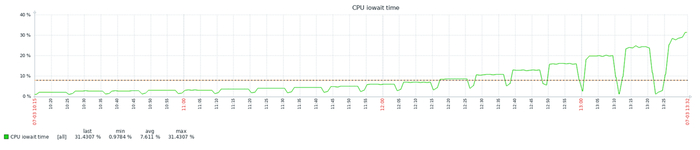
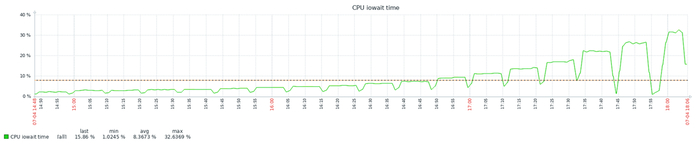
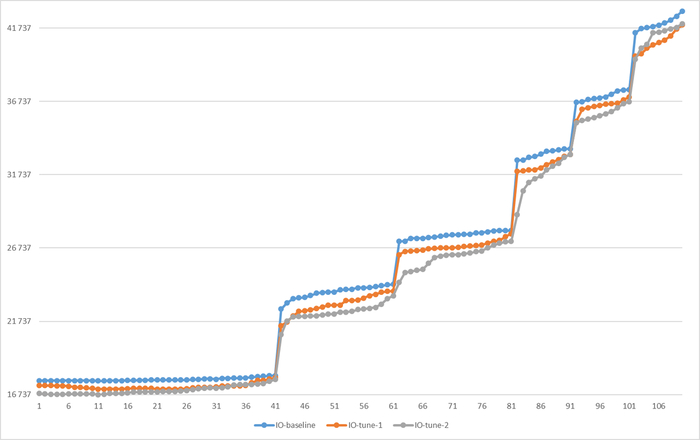
Ожидания IO
Ось X - точка наблюдения. Ось Y - ожидания СУБД типа IO

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Среднее снижение количества ожиданий СУБД типа IO в эксперименте-1K = -4.51%
Ожидания IPC

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа IPC

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Превышение ожиданий IPC в эксперименте-1K при нагрузке близкой к максимальной.
Среднее снижение количества ожиданий СУБД типа IPC в эксперименте-1K = -37.44%
Ожидания Lock

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа Lock
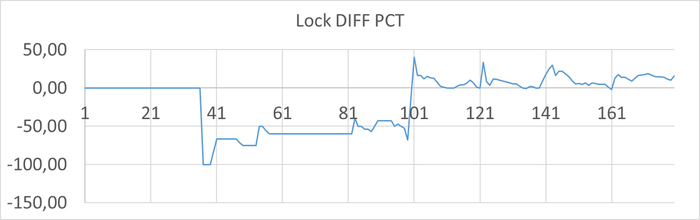
Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
С ростом нагрузки ожидания Lock в эксперименте-1К начинают превышать ожидания в эксперименте-10K.
Среднее снижение количества ожиданий СУБД типа Lock в эксперименте-1K = -17.00%
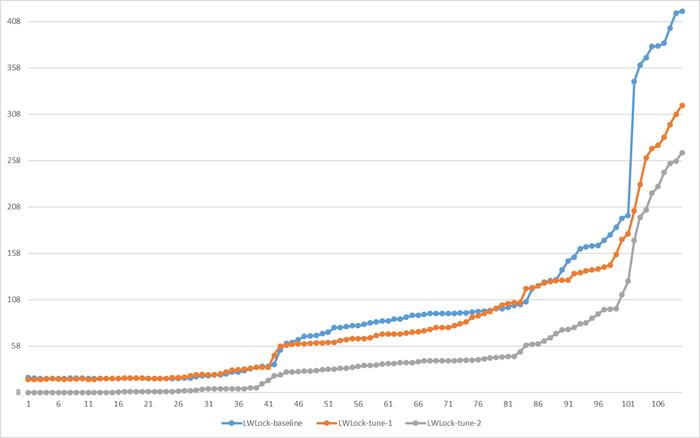
Ожидания LWLock

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа LWLock

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
В целом ожидания Lock в эксперименте-1К превышают ожидания в эксперименте-10K.
Среднее повышение количества ожиданий СУБД типа Lock в эксперименте-1K = 13.46%
Итог
Для данной СУБД и данного сценария синтетической нагрузки. При нагрузке на СУБД с 5 до 115 одновременных соединений :
Снижение граничного условия старта autovacuum с 10 000 до 1 000 мёртвых строк , приводит к повышению производительности в среднем до 9.5%.
Mаксимальный прирост производительности достигает 31%.
P.S.
Корреляционный анализ ожиданий по тестовым сценариям, будет подготовлен позже.