PG_HAZEL : Комплексный анализ инцидента производительности СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

СУБД это не только software но и не менее важное hardware.
Задача
Провести комплексный(СУБД + ОС) анализ причин инцидента производительности СУБД .
Инцидент производительности СУБД
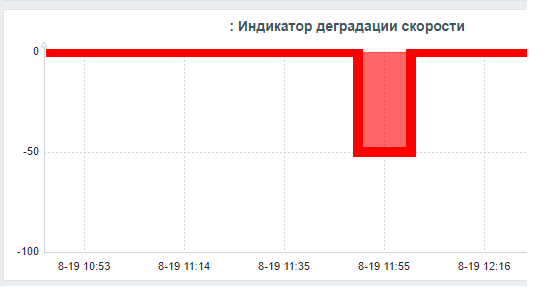
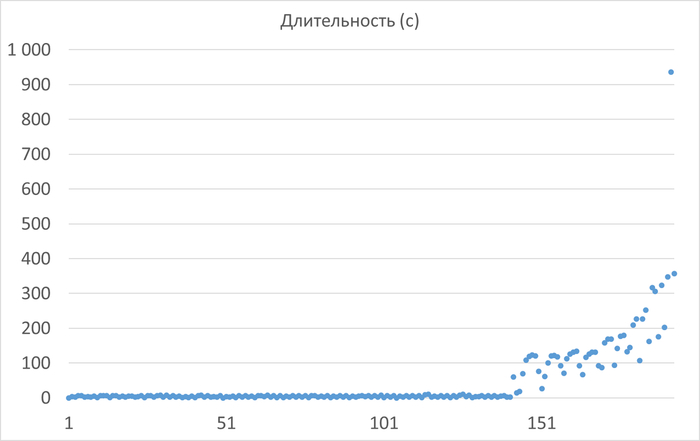
Ось X - точка наблюдения. Ось Y - значение индикатора деградации скорости СУБД
Отчет по инцидентам производительности
incidents_to_timepoint.sh - отчет по инцидентам производительности за период
cd /postgres/scripts/tester/reports/incidents
./incidents_to_timepoint.sh '2025-08-19 10:45' '2025-08-19 12:00'
Время начала инцидента

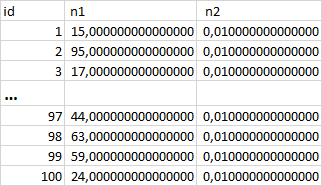
Фрагмент отчета
Начало инцидента : 11:50
Корреляционный анализ ожиданий СУБД
cluster_performance.sh - метрики оценки производительности СУБД
cd /postgres/scripts/tester/reports/detailed
./cluster_performance.sh '2025-08-19 10:50' '2025-08-19 11:50'
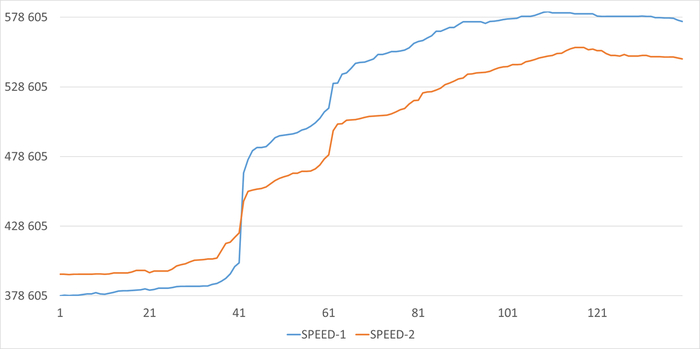
Операционная скорость

Ось X - точка наблюдения. Ось Y - операционная скорость
Ожидания СУБД
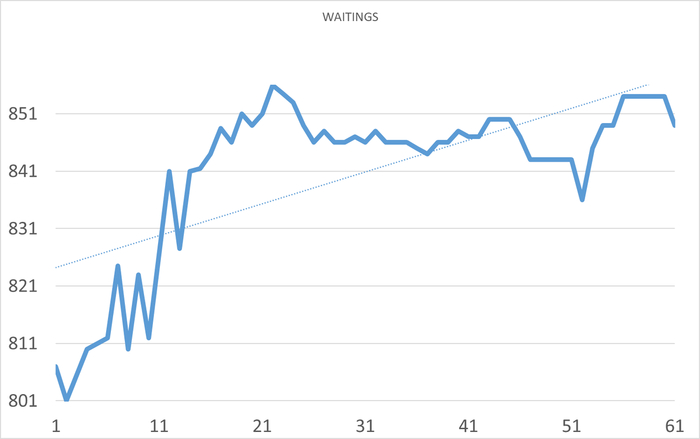
Ось X - точка наблюдения. Ось Y - ожидания СУБД

Абсолютные значения по скорости и ожиданиям СУБД за период в течении часа до начала инцидента
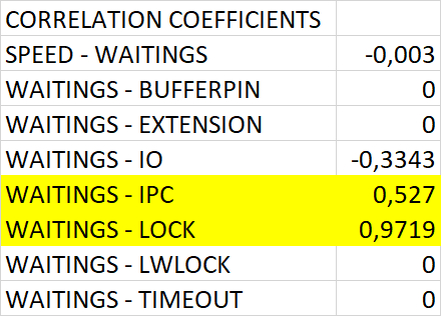
Корреляция по типам ожиданий
Ожидания типа IPC
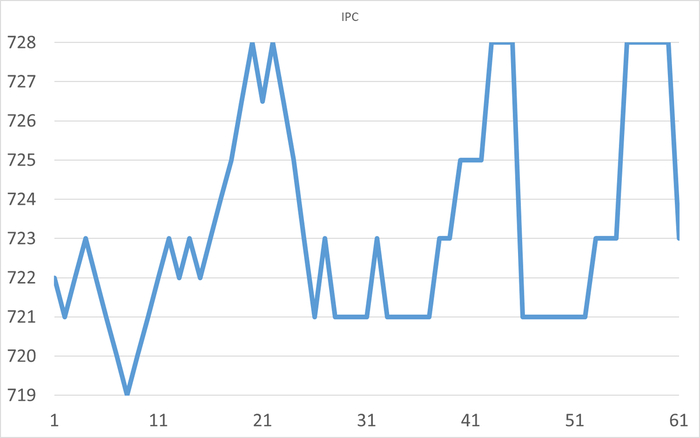
Ось X - точка наблюдения. Ось Y - ожидания типа IPC
Ожидания типа Lock
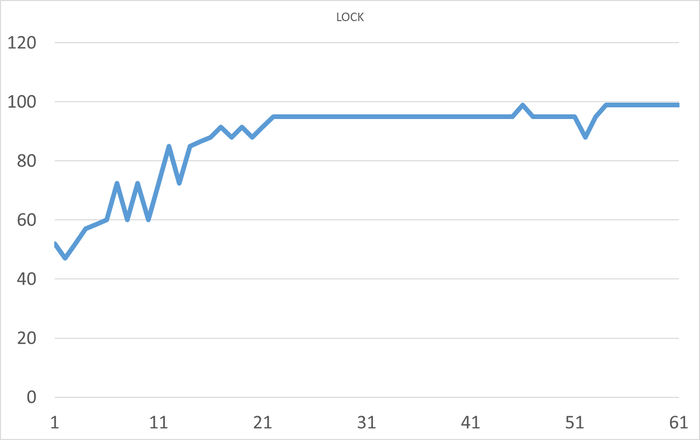
Ось X - точка наблюдения. Ось Y - ожидания типа Lock
Результат корреляционного анализ ожиданий СУБД
Наибольшая корреляция по событиям ожидания и снижением скорости СУБД:
IPC : Серверный процесс ожидает взаимодействия с другим процессом.
Lock : Серверный процесс ожидает тяжёлую блокировку.
Корреляционный анализ метрик оценки производительности инфраструктуры
vmstat.sh - отчет по метрикам vmstat
iostat_cpu.sh - отчет по метрикам iostat для CPU
iostat_device.sh - отчет по метрикам iostat для I/O
./vmstat.sh '2025-08-19 10:50' '2025-08-19 11:50'
./iostat_cpu.sh '2025-08-19 10:50' '2025-08-19 11:50'
lsblk
./iostat_device.sh '2025-08-19 10:50' '2025-08-19 11:50' 'vdb vdc'
VMSTAT

Корреляция между ожиданиями СУБД и метриками vmstat
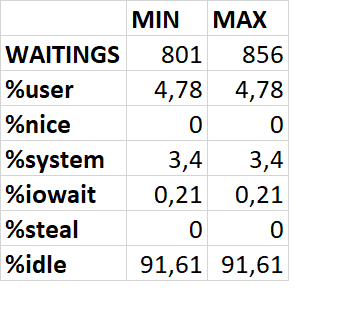
Абсолютные значения метрик vmstat
Корреляция между ожиданиями СУБД и метриками vmstat:
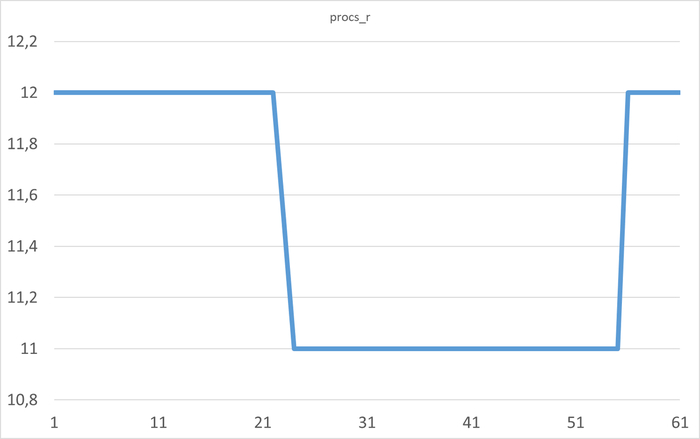
r : процессы в run queue (готовы к выполнению)
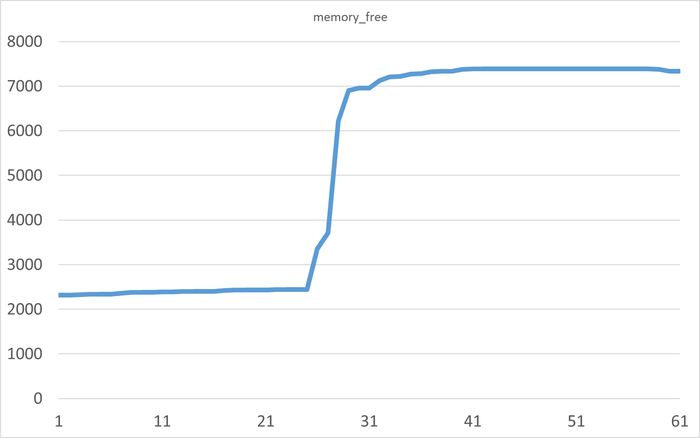
free : свободная RAM
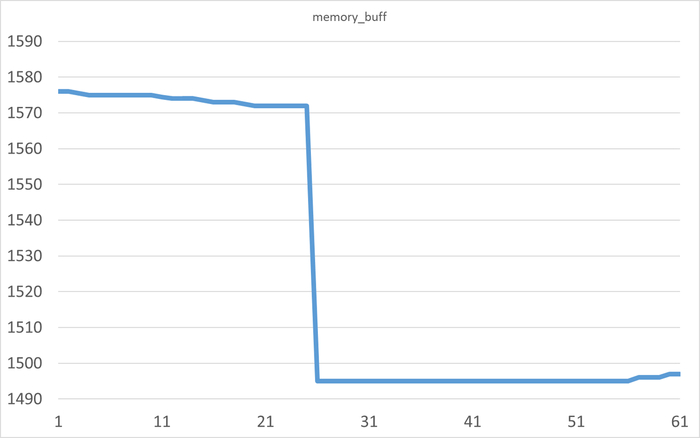
buff : буферы
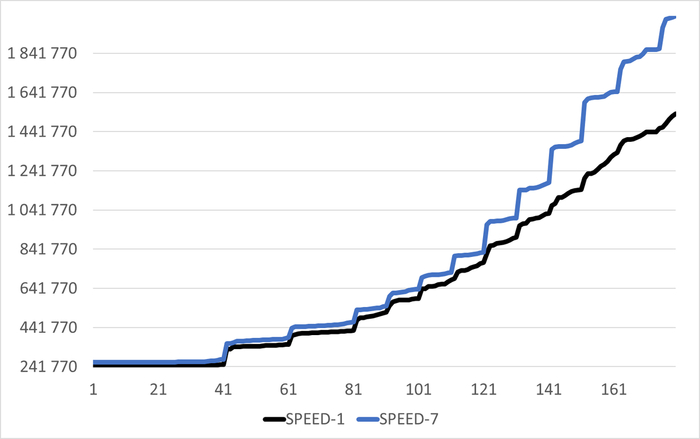
Исторические графики метрик vmstat
r : процессы в run queue (готовы к выполнению)
free : свободная RAM
buff : буферы
iostat_cpu
Корреляция между ожиданиями СУБД и метриками iostat_cpu
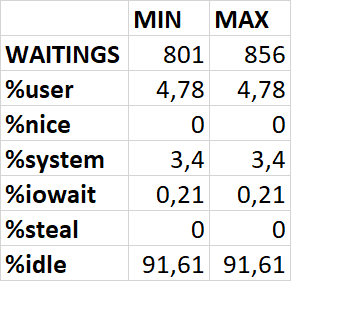
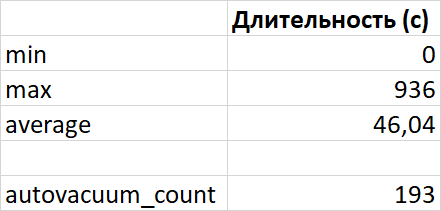
Абсолютные значения метрик iostat_cpu
Корреляция между ожиданиями СУБД и метриками iostat_cpu: отсутствует
iostat_device (файловая система /data)

Корреляция между ожиданиями СУБД и метриками iostat_device(файловая система /data)
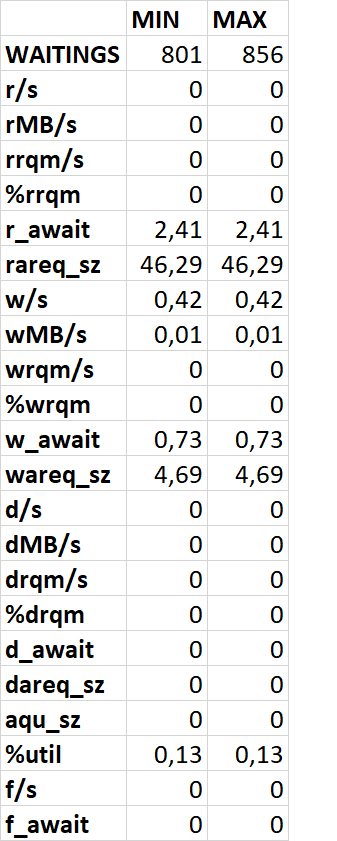
Абсолютные значения метрик iostat_device (файловая система /data)
Корреляция между ожиданиями СУБД и метриками iostat_device(файловая система /data) : отсутствует
iostat_device (файловая система /wal)
Результаты аналогичны.
Корреляция между ожиданиями СУБД и метриками iostat_device(файловая система /wal) : отсутствует
Результат корреляционного анализа метрик оценки производительности инфраструктуры
Аномальная корреляция и влияние инфраструктуры на рост ожидания СУБД - не установлено.
SQL-запросы для оптимизации по результатам отчета incidents_to_timepoint.sh
Ожидания(wait_event_type / wait_event) в ходе инцидента
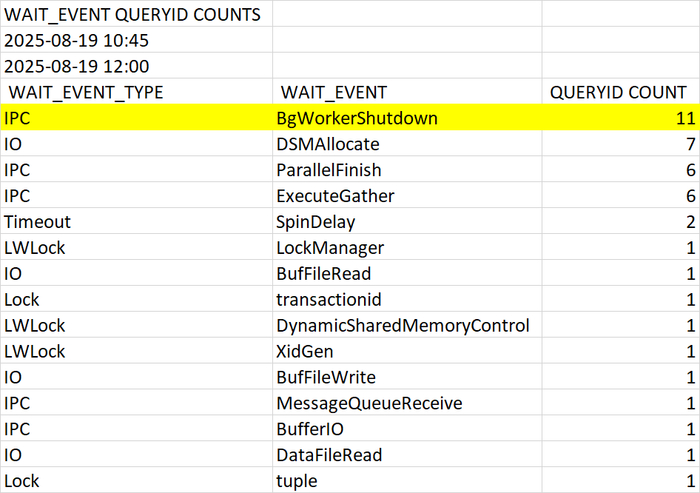
Наибольшее количество запросов в ходе инцидента имеет ожидание IPC / BgWorkerShutdown
SQL-запросы для оптимизации
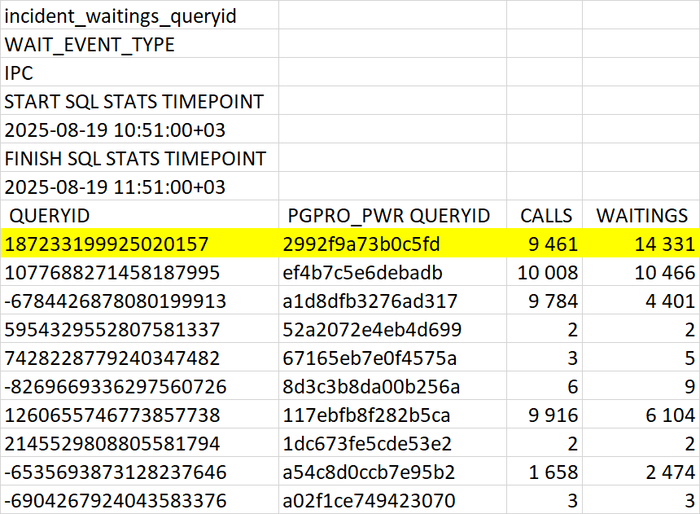
Наибольшая доля ожиданий IPC у SQL запроса 187233199925020157
Текст запроса
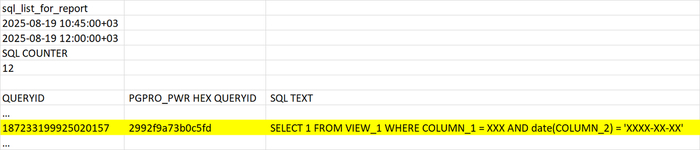
Фрагмент полного списка SQL-запросов
Корреляционный анализ отдельного SQL-запроса
queryid = 187233199925020157
queryid_stat.sh - события ожидания по заданному SQL-запросу за период
cd /postgres/scripts/tester/reports/detailed
./queryid_stat.sh 187233199925020157 '2025-08-19 10:45' '2025-08-19 12:00'
События ожидания по SQL-запросу
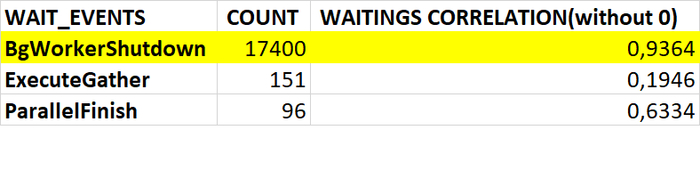
Наибольшая корреляция и наибольшее количество ожиданий:
BgWorkerShutdown: Ожидание завершения фонового рабочего процесса.
План выполнения запроса

Мероприятия для оптимизации SQL-запроса
Добавить индекс в таблицу используемую для представления VIEW_1