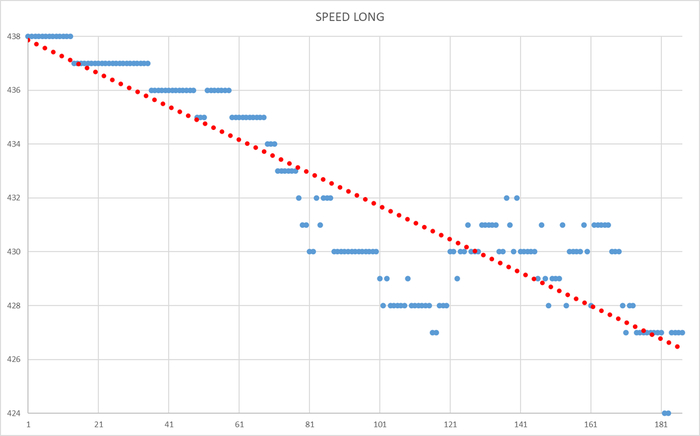
Операционная скорость и ожидания СУБД в ходе выполнения теста
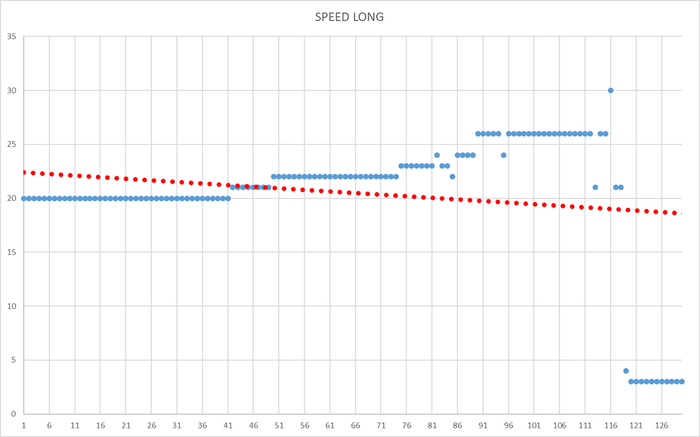
Ось X - точка времени. Ось Y - значение операционной скорости СУБД.
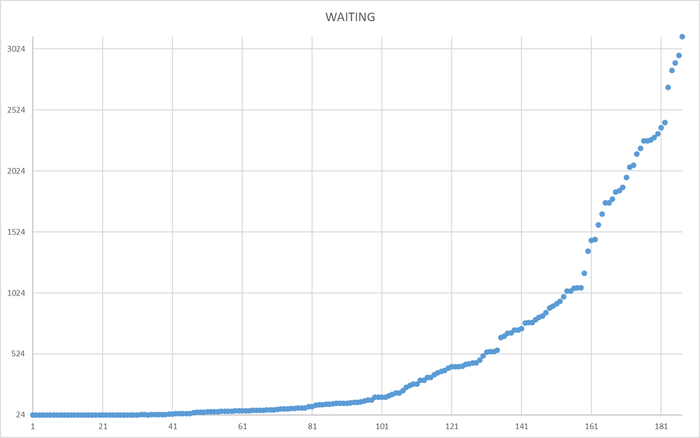
Ожидания СУБД
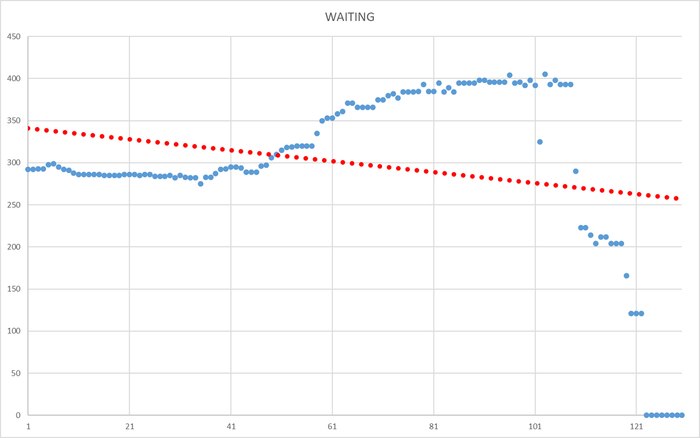
Ось X - точка времени. Ось Y - ожидания СУБД.
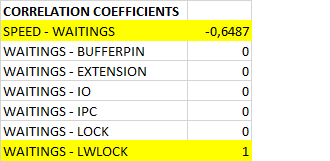
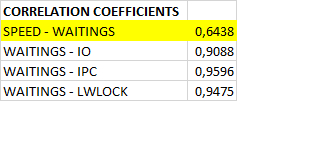
Коэффициенты корреляции
Коэффициенты корреляции между операционной скоростью и ожиданиями.
Сильная корреляция между ожиданиями и ожиданиями типа LWLock свидетельствует о том, что все ожидания вызваны типом LWLock.
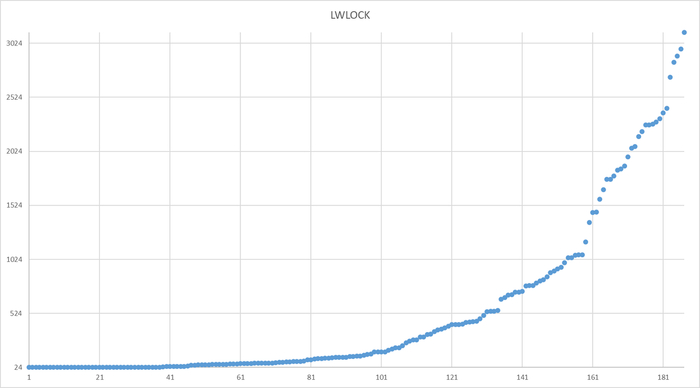
Ожидания типа LWLock
Ось X - точка времени. Ось Y - ожидания типа LWLock
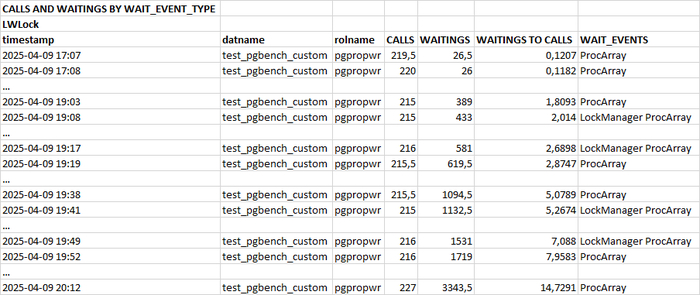
События ожиданий (wait_event) по тестовому запросу
Фрагмент истории выполнения и ожиданий тестового запроса
Столбцы таблицы:
timestamp : точка времени сбора статистических данных уровня SQL.
datname : База данных, в которой выполнялся SQL запрос.
rolname : Роль, под которой выполнялся SQL запрос.
CALLS : Количество выполнений запроса .
WAITINGS : Количество ожиданий типа IO , LWLock .
WAITINGS TO CALLS : количество ожиданий на одно выполнение.
WAIT_EVENTS : события ожидания wait_event , возникающие при выполнении SQL запроса .
SQL : текст SQL запроса (не приведен).
События ожидания возникающие при выполнении SQL запроса:
ProcArray : Ожидание при обращении к общим структурам данных в рамках процесса (например, при получении снимка или чтении идентификатора транзакции в сеансе).
LockManager : Ожидание при чтении или изменении информации о «тяжёлых» блокировках.
Итог
Характерным признаком недостатка вычислительных ресурсов CPU является корреляция между снижением операционной скорости и ростом ожиданий ProcArray .
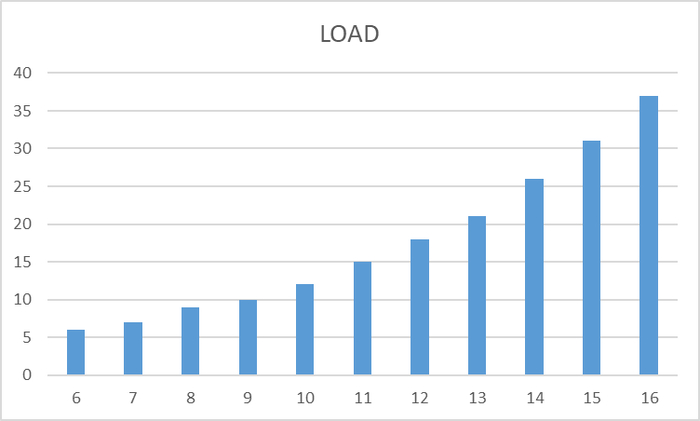
Ось X - номер тестовой итерации. Ось Y - количество сессий (--clints в pgbench)
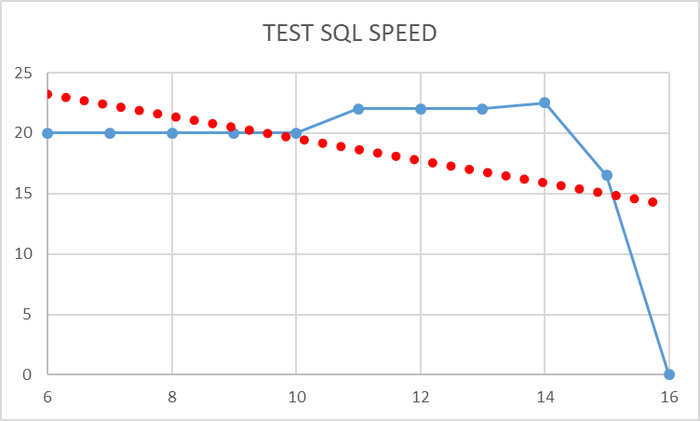
Операционная скорость и время выполнения тестового запроса
Ось X - номер тестовой итерации. Ось Y - значение операционной скорости тестового запроса.
Тест был принудительно завершен после потери работоспособности СУБД после выполнении итерации №16.
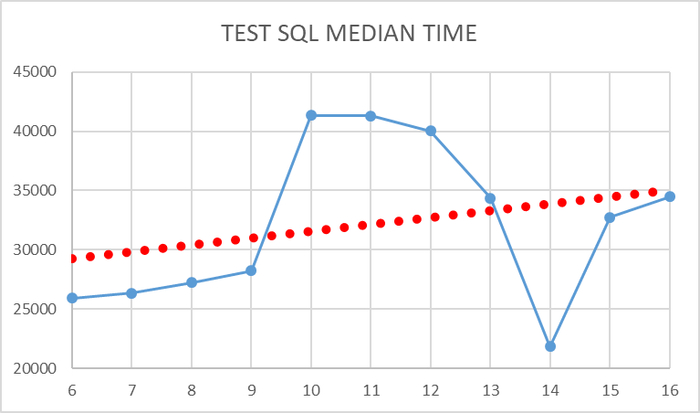
Ось X - номер тестовой итерации. Ось Y - среднее время выполнения тестового запроса
Операционная скорость и ожидания СУБД в ходе выполнения теста
Время выполнения с итерации №6 до итерации №16.
Периодичность сбора данных = 1 минута.
Операционная скорость
Ось X - точка времени. Ось Y - значение операционной скорости СУБД.
Ожидания СУБД
Ось X - точка времени. Ось Y - ожидания СУБД
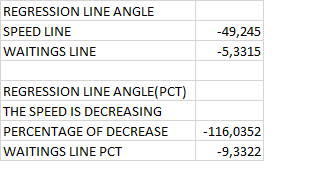
Линия регрессии операционной скорости и ожиданий СУБД
Углы наклона линии регрессии и процентное отношение линии регрессии
Коэффициенты корреляции
Коэффициенты корреляции между операционной скоростью и ожиданиями
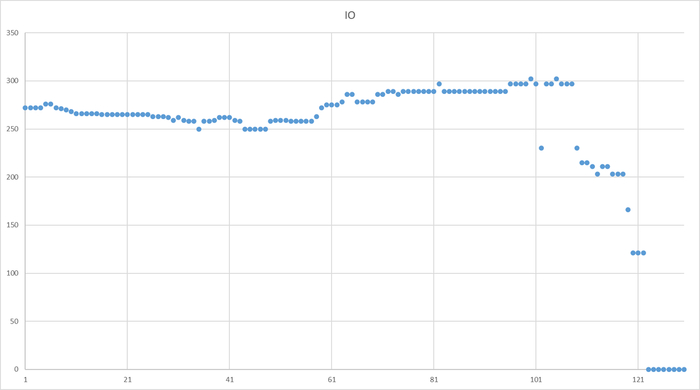
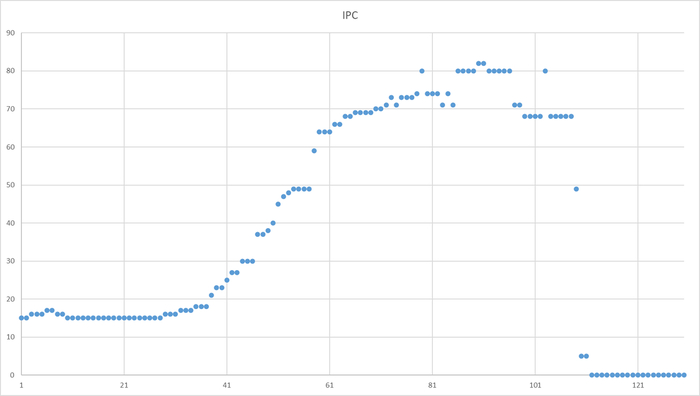
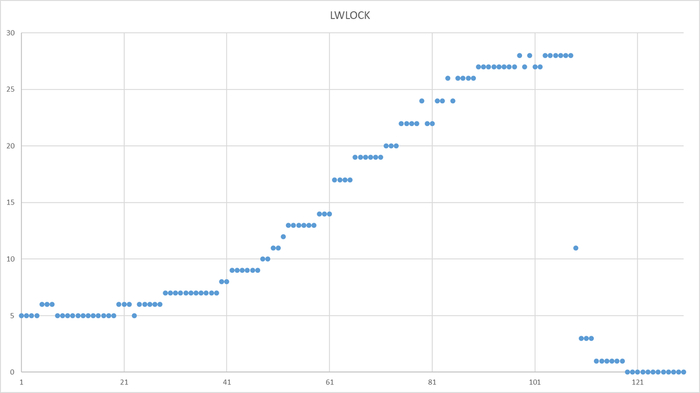
Ожидания типа IO, IPC , LWLock
Ось X - точка времени. Ось Y - ожидания типа IO
Ось X - точка времени. Ось Y - ожидания типа IPC
Ось X - точка времени. Ось Y - ожидания типа LWLock
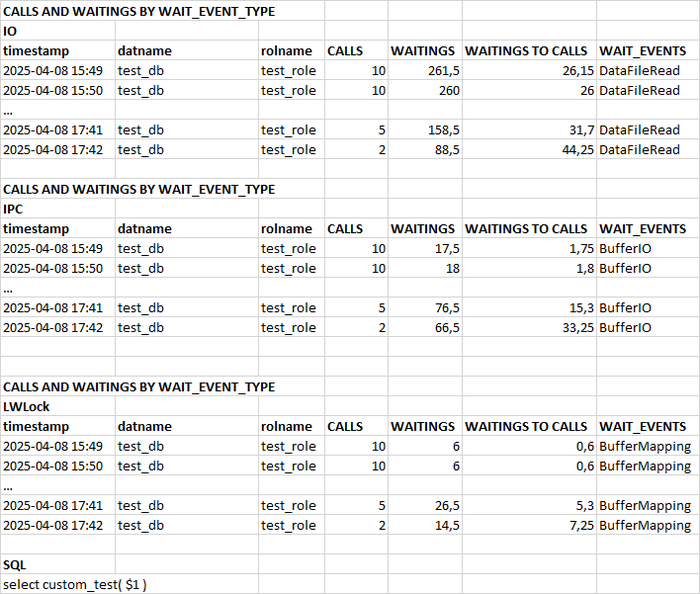
События ожиданий (wait_event) по тестовому запросу
Фрагмент истории выполнения и ожиданий тестового запроса
Столбцы таблицы:
timestamp : точка времени сбора статистических данных уровня SQL.
datname : База данных, в которой выполнялся SQL запрос.
rolname : Роль, под которой выполнялся SQL запрос.
CALLS : Количество выполнений запроса .
WAITINGS : Количество ожиданий типа IO , LWLock .
WAITINGS TO CALLS : количество ожиданий на одно выполнение.
WAIT_EVENTS : события ожидания wait_event , возникающие при выполнении SQL запроса .
SQL : текст SQL запроса (не приведен).
События ожидания возникающие при выполнении SQL запроса:
DataFileRead : Ожидание чтения из файла данных отношения.
BufferIO : Ожидание завершения буферного ввода/вывода.
BufferMapping : Ожидание при связывании блока данных с буфером в пуле буферов.
Итог
Характерным признаком недостаточного размера общей области памяти shared_buffers является корреляция между снижением операционной скорости и ростом ожиданий BufferMapping/BufferIO.
1.Проанализировать инциденты снижения скорости СУБД
Ожидания и корреляция по инцидентам снижения скорости СУБД
Фрагмент таблицы инцидентов снижения скорости СУБД
Столбцы таблицы:
ID : идентификатор инцидента снижения скорости СУБД
START TIME : время начала инцидента
FINISH TIME : время окончания инцидента
№ : порядковый номер
IO : количество ожидания типа IO на время начала инцидента
IO CORRELATION : коэффициент корреляции между операционной скоростью и ожиданиями IO за отрезок [ START TIME - 1 ЧАС ; START TIME ]
LWLock : количество ожидания типа LWLock на время начала инцидента
LWLock CORRELATION : коэффициент корреляции между операционной скоростью и ожиданиями LWLock за отрезок [ START TIME - 1 ЧАС ; START TIME ]
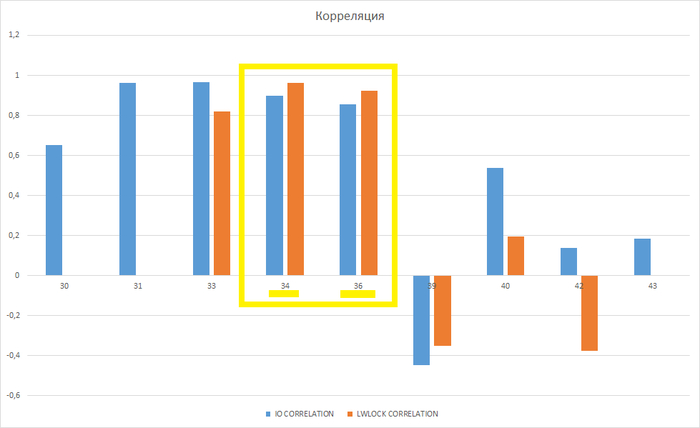
Количество ожидания типа IO , LWLock по инцидентам
Ось X - ID инцидента. Ось Y - количество ожидания типа IO на начало инцидента
Ось X - ID инцидента. Ось Y - количество ожидания типа LWLock на начало инцидента
Ось X - ID инцидента. Ось Y - коэффициент корреляции между всеми ожиданиями и ожиданиями типа IO , LWLock на начало инцидента
Особенности инцидентов 34 , 36 :
Коэффициент корреляции между ожиданиями СУБД в целом и ожиданиями типа LWLock больше , чем между ожиданиями СУБД в целом и ожиданиями типа IO.
Количество ожидания типа LWLockменьше чем количество ожидания типа IO.
Графики операционной скорости и ожиданий по инцидентам снижения скорости
Инцидент 34
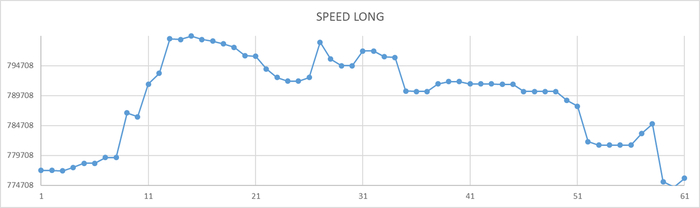
Ось X - точка наблюдения. Ось Y - значение операционной скорости.
Ось X - точка наблюдения. Ось Y - количество ожиданий в целом по СУБД.
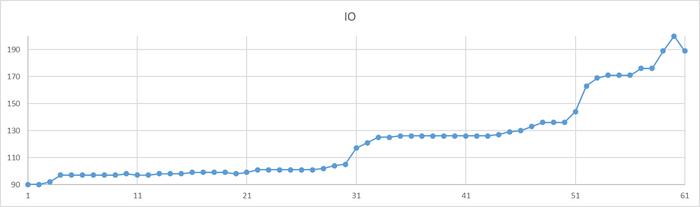
Ось X - точка наблюдения. Ось Y - количество ожиданий типа IO.
Ось X - точка наблюдения. Ось Y - количество ожиданий типа LWLock.
Инцидент 36
Ось X - точка наблюдения. Ось Y - значение операционной скорости.
Ось X - точка наблюдения. Ось Y - количество ожиданий в целом по СУБД.
Ось X - точка наблюдения. Ось Y - количество ожиданий типа IO.
Ось X - точка наблюдения. Ось Y - количество ожиданий типа LWLock.
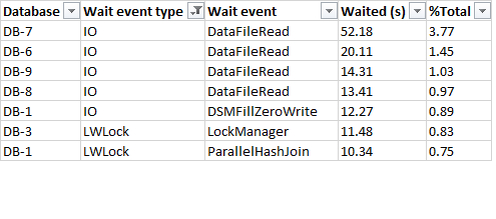
Для справки: ожидания типа IO , LWLock по данным отчета "Top wait events" pgpro_pwr
Инцидент 34
Инцидент 36
2. Установить причины снижения скорости СУБД
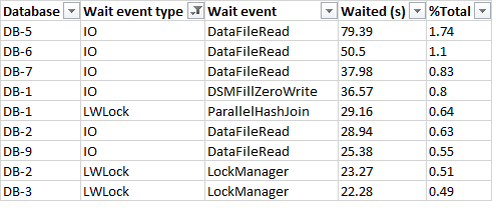
SQL запросы, имеющие наибольшую долю ожидания заданного типа
Инцидент 34
Ожидания типа IO
Статистика вызовов и ожидания по запросам имеющим ожидания типа IO
Ожидания типа LWLock
Статистика вызовов и ожидания по запросам имеющим ожидания типа LWLock
Столбцы таблицы:
QUERYID : queryid SQL выражения , из представления pgpro_stats.
PGPRO_PWR_QUERYID : шестнадцатеричное значение queryid , для использования в отчетах pgpro_pwr.
CALLS : количество выполнений SQL выражения
WAITINGS : количество ожиданий
WAITINGS TO CALLS : количество ожиданий на одно выполнение
WAITINGS PPM : доля(в промилле) ожиданий типа IPC по данному SQL среди всех ожиданий по всем SQL за анализируемый период.
Результат:
Запрос queryid=2092406791392746781 имеет набольшую долю ожидания типа IO и LWLock среди всех запросов имеющих корреляцию ожидания с типом IO, LWLock.
Инцидент 36
Ожидания типа IO
Статистика вызовов и ожидания по запросам имеющим ожидания типа IO
Ожидания типа LWLock
Статистика вызовов и ожидания по запросам имеющим ожидания типа LWLock
Столбцы таблицы:
QUERYID : queryid SQL выражения , из представления pgpro_stats.
PGPRO_PWR_QUERYID : шестнадцатеричное значение queryid , для использования в отчетах pgpro_pwr.
CALLS : количество выполнений SQL выражения
WAITINGS : количество ожиданий
WAITINGS TO CALLS : количество ожиданий на одно выполнение
WAITINGS PPM : доля(в промилле) ожиданий типа IPC по данному SQL среди всех ожиданий по всем SQL за анализируемый период.
Результат:
Запрос queryid=2092406791392746781 имеет набольшую долю ожидания типа IO и LWLock среди всех запросов имеющих корреляцию ожидания с типом IO, LWLock.
Главная причина снижения скорости СУБД
Запрос queryid=2092406791392746781 имеет набольшую долю ожидания типа IO и LWLock среди всех запросов имеющих корреляцию ожидания с типом IO, LWLock.
Текст запроса
Доступен в pgpro_pwr
План выполнения запроса
Доступен в pgpro_pwr
События ожидания при выполнении запроса 2092406791392746781
Инцидент 34
Статистика выполнения и событий ожидания по запросу 2092406791392746781
Столбцы таблицы:
timestamp : точка времени сбора статистических данных уровня SQL.
datname : База данных, в которой выполнялся SQL запрос.
rolname : Роль, под которой выполнялся SQL запрос.
CALLS : Количество выполнений запроса .
WAITINGS : Количество ожиданий типа IO , LWLock .
WAITINGS TO CALLS : количество ожиданий на одно выполнение.
WAIT_EVENTS : события ожидания wait_event , возникающие при выполнении SQL запроса .
SQL : текст SQL запроса (не приведен).
События ожидания возникающие при выполнении SQL запроса:
IO / DSMFillZeroWrite : Ожидание заполнения нулями файла, применяемого для поддержки динамической общей памяти.
LWLock / ParallelHashJoin : Ожидание синхронизации рабочих процессов в процессе выполнения узла плана Parallel Hash Join.
Инцидент 36
Статистика выполнения и событий ожидания по запросу 2092406791392746781
Cтолбцы таблицы:
timestamp : точка времени сбора статистических данных уровня SQL.
datname : База данных, в которой выполнялся SQL запрос.
rolname : Роль, под которой выполнялся SQL запрос.
CALLS : Количество выполнений запроса .
WAITINGS : Количество ожиданий типа IO , LWLock .
WAITINGS TO CALLS : количество ожиданий на одно выполнение.
WAIT_EVENTS : события ожидания wait_event , возникающие при выполнении SQL запроса .
SQL : текст SQL запроса (не приведен).
События ожидания возникающие при выполнении SQL запроса:
IO / DSMFillZeroWrite : Ожидание заполнения нулями файла, применяемого для поддержки динамической общей памяти.
LWLock / ParallelHashJoin : Ожидание синхронизации рабочих процессов в процессе выполнения узла плана Parallel Hash Join.
LWLock / BufferMapping : Ожидание при связывании блока данных с буфером в пуле буферов.
LWLock / ProcArray : Ожидание при обращении к общим структурам данных в рамках процесса (например, при получении снимка или чтении идентификатора транзакции в сеансе).
3. Cписок мероприятий для устранения причин снижения скорости СУБД .
Мероприятия для снижения ожиданий DSMFillZeroWrite
События ожидания DSMFillZeroWrite в PostgreSQL связаны с операциями записи в разделяемую память (shared memory), где необходимо заполнить область нулями перед использованием.
Это может происходить при работе с большими объектами или при высокой нагрузке на систему.
Чтобы снизить количество таких событий, можно рассмотреть следующие шаги:
1. Оптимизация запросов и транзакций:
- Убедитесь, что ваши запросы оптимизированы и не выполняют избыточных операций.
- Сократите длительность транзакций, чтобы уменьшить нагрузку на разделяемую память.
2. Настройка параметров конфигурации:
- Увеличьте размер разделяемой памяти (shared_buffers), чтобы уменьшить частоту операций записи в разделяемую память.
- Настройте параметры, связанные с кэшированием и буферизацией, чтобы уменьшить количество операций записи.
3. Оптимизация использования разделяемой памяти:
- Убедитесь, что ваши приложения и расширения эффективно используют разделяемую память.
- Избегайте создания большого количества временных объектов, которые могут приводить к увеличению операций записи в разделяемую память.
Мероприятия для снижения ожиданий ParallelHashJoin
Ожидания ParallelHashJoin могут возникать из-за того, что PostgreSQL использует параллельные запросы для выполнения операций, таких как Hash Join. Это может привести к увеличению количества ожиданий, особенно если у вас много одновременных запросов или ограниченные ресурсы.
1. Отключить параллельные запросы:
- Вы можете отключить параллельные запросы, установив параметр max_parallel_workers_per_gather в 0. Это отключит использование параллельных рабочих процессов для операций, таких как Hash Join.
2. Оптимизировать индексы:
- Убедитесь, что у вас есть правильные индексы на таблицах, участвующих в запросе. Индексы могут помочь ускорить выполнение запросов и уменьшить необходимость в параллельных операциях.
3. Анализ и вакуумизация таблиц:
- Периодически выполняйте команды ANALYZE и VACUUM для обновления статистики и очистки мертвых строк. Это поможет оптимизатору запросов выбрать более эффективные планы выполнения.
4. Настройка параметров планировщика:
- Настройте параметры, такие как random_page_cost и cpu_tuple_cost, чтобы повлиять на выбор плана выполнения запроса. Например, уменьшение random_page_cost может сделать индексные сканирования более привлекательными.
5. Использование правильных операторов JOIN:
- Попробуйте использовать другие типы соединений, такие как Nested Loop или Merge Join, если они подходят для вашего запроса. Вы можете временно отключить Hash Join, установив параметр enable_hashjoin в off.
6. Оптимизация запросов:
- Проверьте, можно ли оптимизировать сами запросы, например, добавив дополнительные условия в WHERE-clause или используя более эффективные подзапросы.
Примеры команд для настройки параметров:
-- Отключить параллельные запросы
SET max_parallel_workers_per_gather = 0;
-- Отключить Hash Join
SET enable_hashjoin = off;
-- Установить параметры планировщика
SET random_page_cost = 1.1;
SET cpu_tuple_cost = 0.01;
Мероприятия для снижения ожиданий BufferMapping
Ожидания на BufferMapping в PostgreSQL могут возникать из-за интенсивных операций чтения, когда база данных часто обращается к данным на диске вместо кэша. Это может происходить, когда рабочий набор данных превышает доступную память, что приводит к частым операциям ввода-вывода (I/O).
1. Увеличение shared_buffers:
- Увеличение параметра shared_buffers может помочь уменьшить количество операций ввода-вывода, так как больше данных будет храниться в памяти.
2. Оптимизация запросов:
- Проверьте и оптимизируйте ваши запросы, чтобы уменьшить количество операций ввода-вывода. Используйте индексы и другие методы оптимизации для уменьшения количества данных, которые нужно считывать из диска.
3. Увеличение effective_cache_size:
- Параметр effective_cache_size помогает PostgreSQL лучше оценивать доступную память для кэширования данных. Увеличение этого параметра может улучшить планирование запросов.
4. Увеличение work_mem и maintenance_work_mem:
- Увеличение параметров work_mem и maintenance_work_mem может помочь уменьшить количество операций ввода-вывода, особенно при выполнении операций сортировки и хранения данных.
5. Анализ и оптимизация индексов:
- Убедитесь, что у вас есть правильные индексы для ваших запросов. Индексы могут значительно уменьшить количество операций ввода-вывода.
6. Обновление аппаратного обеспечения:
- Если возможно, обновите аппаратное обеспечение, особенно увеличьте объем оперативной памяти и используйте более быстрые диски (например, SSD).
7. Распределение нагрузки:
- Анализируйте и оптимизируйте распределение нагрузки между сессиями, чтобы уменьшить конкуренцию за ресурсы.
Мероприятия для снижения ожиданий ProcArrayLock
Задержки, связанные с блокировкой ProcArrayLock, могут возникать из-за интенсивной активности рабочих процессов, которые создают конкуренцию за доступ к ProcArray. Это особенно актуально при выполнении параллельных запросов и операций, таких как walsender.
Для уменьшения задержек ProcArray можно рассмотреть следующие шаги:
1. Оптимизация рабочих процессов:
- Уменьшите количество одновременно выполняемых рабочих процессов, чтобы снизить нагрузку на ProcArrayLock.
- Оптимизируйте параллельные запросы, чтобы уменьшить их длительность и уменьшить время блокировки.
2. Настройка параметров конфигурации:
- Уменьшите значение параметра max_standby_streaming_delay, чтобы уменьшить задержку репликации.
- Настройте параметры, связанные с параллелизмом, такие как max_parallel_workers_per_gather и max_worker_processes, чтобы управлять количеством рабочих процессов.
3. Оптимизация хранения данных:
- Убедитесь, что у вас используется оптимальное хранилище данных, например, AWS EBS GP3, для уменьшения задержек ввода-вывода.
4. Итог
Использование корреляционного анализа ожиданий с помощью оперативно-тактического комплекса pg_hazel позволяет резко сократить время на поиск корневой причины снижения скорости СУБД и оперативно предоставить мероприятия для устранения причин.
Подготовить примерный шаблон действий выполняемых при анализе инцидентов производительности с использованием оперативно-тактического комплекса "pg_hazel".
Общий алгоритм действий
Обнаружение инцидента производительности СУБД
Отчет по инцидентам производительности
Анализ SQL выражений , имеющих ожидания , оказывающие наибольшее влияние на ожидания СУБД.
История выполнения и ожиданий для SQL , имеющего наибольшую долю ожиданий заданного типа
Использование ChatPPG для начала процесса Problem Management.
Подробное описание шагов на примере реального инцидента производительности продуктивной СУБД
1.Обнаружение инцидента производительности СУБД
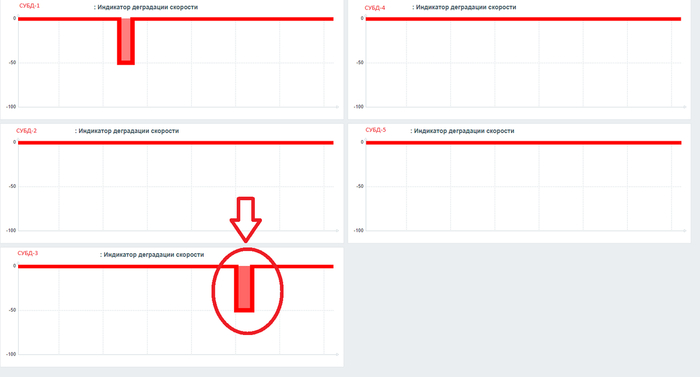
Метрика мониторинга "Индикатор снижения скорости СУБД". Подробнее .
История показаний за прошедший день
Дашборд Zabbix
Результат
Инциденты снижения скорости СУБД с приоритетом 4 по СУБД-1 и СУБД-3.
В качестве примера выбрана СУБД-3.
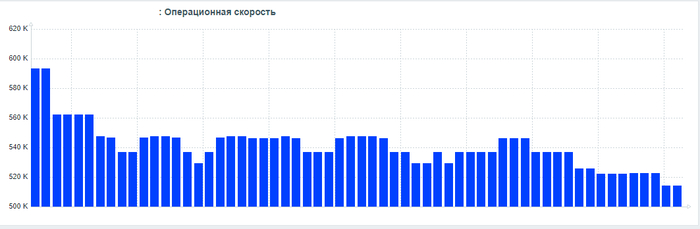
Ось X - точка времени. Ось Y - значение метрики операционной скорости,
2. Отчет по инцидентам производительности
Статистические данные по инциденту производительности. Типа ожиданий с коэффициентом корреляции = 0 : не показаны.
Столбцы таблицы:
ID : идентификатор инцидента
START TIME / FINISH TIME : время начала и окончания инцидента
DURATION : длительность инцидента
PRIORITY : приоритет
SPEED REGRESSION LINE ANGLE : угол наклона линии наименьших квадратов по значениям операционной скорости за отрезок [START TIME;START TIME - 1 час]
WAITINGS REGRESSION LINE ANGLE : угол наклона линии наименьших квадратов по ожиданиям за отрезок [START TIME;START TIME - 1 час]
CORRELATION : коэффициент корреляция между значениями операционной скорости и ожиданий на отрезке [START TIME;START TIME - 1 час]
IPC CORRELATION : коэффициент корреляции между всеми значениями ожиданий и ожиданиями типа IPC.
Промежуточный результат:
Коэффициент корреляции между операционной скоростью и ожиданиями низкий. Несмотря на большой угол наклона линии наименьших квадратов ожиданий. Следовательно - влияние ожиданий на снижение скорости СУБД - незначительно.
Коэффициент корреляции между всеми ожиданиями и ожиданиями типа IPC - наивысший. Следовательно - наибольшее влияние на ожидания СУБД оказывают ожидания типа IPC.
Дальнейший анализ SQL выражений необходимо проводить для SQL выражений имеющих ожидания IPC.
3. Анализ SQL выражений, имеющих ожидания , оказывающие наибольшее влияние на ожидания СУБД.
Таблица статистических данных по SQL выражениям имеющим ожидания IPC
Столбцы таблицы:
QUERYID : queryid SQL выражения , из представления pgpro_stats.
PGPRO_PWR_QUERYID : шестнадцатеричное значение queryid , для использования в отчетах pgpro_pwr.
CALLS : количество выполнений SQL выражения
WAITINGS : количество ожиданий
WAITINGS TO CALLS : количество ожиданий на одно выполнение
WAITINGS PPM : доля(в промилле) ожиданий типа IPC по данному SQL среди всех ожиданий по всем SQL за анализируемый период.
Результаты:
Ожидания типа IPC в течении анализируемого периода имеет только SQL выражение queryid=1622895052665899717 .
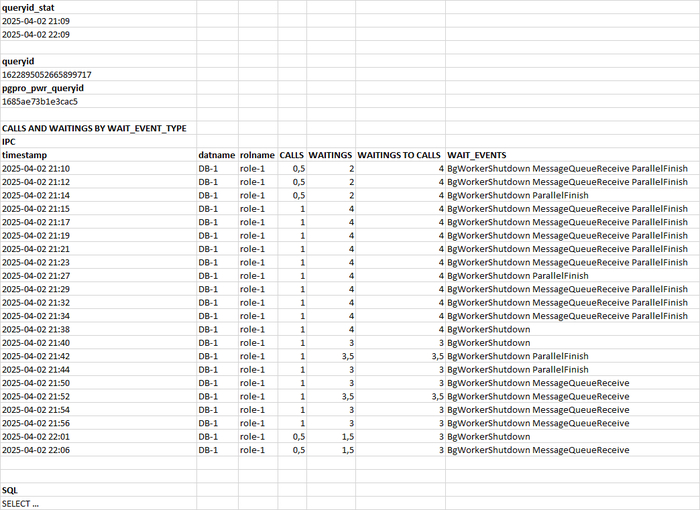
4. История выполнения и ожиданий для SQL , имеющего наибольшую долю ожиданий заданного типа.
История выполнения и ожиданий для queryid=1622895052665899717
Столбцы таблицы:
timestamp : точка времени сбора статистических данных уровня SQL.
datname : База данных, в которой выполнялся SQL запрос.
rolname : Роль, под которой выполнялся SQL запрос.
CALLS : Количество выполнений запроса на точку времени (медианное значение).
WAITINGS : Количество ожиданий wait_event_type = IPC , на точку времени (медианное значение).
WAITINGS TO CALLS : количество ожиданий на одно выполнение.
WAIT_EVENTS : события ожидания wait_event , возникающие при выполнении SQL запроса на точку времени.
SQL : текст SQL запроса (не приведен).
События ожидания возникающие при выполнении SQL запроса:
BgWorkerShutdown : Ожидание завершения фонового рабочего процесса.
MessageQueueReceive : Ожидание получения байтов из общей очереди сообщений.
ParallelFinish : Ожидание завершения вычислений параллельными рабочими процессами.
5. Использование ChatPPG для начала процесса Problem Management
Чтобы уменьшить количество ожиданий типа IPC в PostgreSQL, можно предпринять следующие шаги:
1. Уменьшение числа подключений:
Если количество ожиданий IPC вызвано большим числом подключений, можно уменьшить значение параметра max_connections. Это снизит количество семафоров, которые PostgreSQL использует для управления подключениями. Например:
max_connections = 100
2. Настройка параметров ядра:
Убедитесь, что параметры ядра, такие как SEMMNS и SEMMNI, настроены правильно. Эти параметры определяют максимальное количество семафоров и идентификаторов семафоров, которые могут существовать в системе. Например, для Linux можно изменить эти параметры с помощью команды sysctl:
sysctl -w kern.ipc.semmns=50000
sysctl -w kern.ipc.semmni=1000
Чтобы изменения сохранялись после перезагрузки, добавьте их в файл /etc/sysctl.conf.
3. Использование альтернативных методов IPC:
Если возможно, рассмотрите использование альтернативных методов IPC, таких как POSIX семафоры, вместо семафоров System V. Это может быть полезно, если вы используете систему, где семафоры System V являются ограничением.
4. Оптимизация использования памяти:
Убедитесь, что параметры разделяемой памяти настроены правильно. Например, увеличьте значение SHMMAX и SHMALL, если это необходимо для вашего кластера баз данных. Для Linux это можно сделать с помощью команды sysctl:
sysctl -w kernel.shmmax=17179869184
sysctl -w kernel.shmall=4194304
5. Проверка на наличие других процессов, использующих IPC:
Убедитесь, что другие процессы в системе не используют семафоры и разделяемую память в больших количествах. Вы можете использовать команды, такие как ipcs, чтобы просмотреть текущее использование IPC в системе:
ipcs -s
ipcs -m
6. Использование меньшего числа фоновых процессов:
Уменьшение числа фоновых процессов, таких как автовакуум и передатчик WAL, также может помочь уменьшить количество семафоров. Например, уменьшите значения параметров autovacuum_max_workers, max_wal_senders и max_worker_processes.
Пример настройки параметров ядра для Linux:
sysctl -w kern.ipc.semmns=50000
sysctl -w kern.ipc.semmni=1000
sysctl -w kernel.shmmax=17179869184
sysctl -w kernel.shmall=4194304
Эти шаги помогут уменьшить количество ожиданий типа IPC и улучшить производительность PostgreSQL. Для более точной настройки рекомендуется провести анализ текущего использования ресурсов и оптимизировать параметры в соответствии с конкретными требованиями вашей системы.
Мой любимый вопрос на любой конференции по докладам на тему оптимизации производительности СУБД - "а производительность это что ? Как считается ?". Вопрос, всегда, ставит докладчика в замешательство. Чтобы подобное не повторилось , заранее необходимо дать определение метрике производительности СУБД.
На марафоне "Статистический анализ производительности СУБД PostgreSQL" - прибавились участники
В продолжении мыслей по докладу "Статистический анализ бенчмарка", пока , у меня 2 вопроса : 1️⃣ На чем основана гипотеза о том, что при одинаковой нагрузке на один запрос распределения может иметь разные законы , т.е. не только нормальное распределение ? Почему такое утверждение? . Я в , своих ранних работах исходил из предположения, что при таком сценарии отклонение от нормального распределения вызвано исключительно влиянием инфраструктуры .
2️⃣Итак , в ходе статистического анализа установлены параметры распределения, моды , медианы . Какое практическое применение этих данных ? Что дальше ? Или другими словами - какие выводы можно сделать на основании определения параметров статистического распределения результатов бенчмарка ?
P.S. Пользуясь случаем и возможностью - вопросы задал. Жду ответа.