В принципе доклад, интересный. Хотя и ничего нового . Да и не совсем понятно - оптимизация чего ?
Разумеется, я не мог не задать стандартный вопрос:
- Как вообще определить производительность базы данных ? Что это такое?
На что был получен абсолютно ожидаемый ответ :
-На мой взгляд это , что то индивидуальное .
Окак. Сопрошлого года , со времени начала публикаций на Хабре , по теме производительность - ничего не изменилось.
Как тут не вспомнить классику:
Если вы можете измерить то, о чем говорите, и выразить это в цифрах – значит, вы что-то об этом предмете знаете. Но если вы не можете выразить это количественно, ваши знания крайне ограничены и неудовлетворительны. Может это начальный этап, но это не уровень подлинного научного знания.
У. Томсон (лорд Кельвин) шотландский ученый-физик.
Итак, тема оптимизации производительности СУБД - довольно актуальна .
Конечно же это хорошо , надо более активно собирать материалы на конференцию.
Я удивляюсь, как создатели этой конференции каждый год умудряются делать такой профессиональный праздник. Перезагрузка мозга и прямо лечебное общение с коллегами. Профессиональный санаторий какой-то. Пусть эта музыка будет вечной. В этом году как-то особенно душевно получилось.
При нагрузочном тестировании PostgreSQL бенчмарки замеряют время исполнения запроса (latency). Для более объективного результата запрос выполняется большое количество раз — из этого получается некоторый набор latency. Для оценки производительности PostgreSQL на данном запросе можно использовать стандартные методы, такие как медиана или среднее, но мы предлагаем использовать более комплексный подход. Как показала практика, такие выборки часто бывают мультимодальными и состоят из различных распределений с некоторыми параметрами.
В таких случаях стандартных методов становится недостаточно, необходимо анализировать составляющие по отдельности. Результатом работы является инструмент, позволяющий автоматически проводить статистический анализ результата бенчмарка с учетом особенностей каждого набора данных, в том числе выявлять мультимодальность, количество и границы преобладания каждой моды, а также параметры распределений.
Ну, что ж , без ложной скромности - приоритет в идее за мной. Мне не жалко, пользуйтесь, можете даже спрашивать, там по пути много встретится поворотов и граблей. А я довольно далеко уже ушел от анализа бенчмарков, думаю до лета уже практические работы по PostgreSQL performance engineering начнутся. А сейчас - сбор результатов экспериментов и причёсывание алгоритмов методологии.
Чтобы уменьшить количество ожиданий типа IPC в PostgreSQL, можно предпринять следующие шаги:
1. Уменьшение числа подключений: Если количество ожиданий IPC вызвано большим числом подключений, можно уменьшить значение параметра max_connections. Это снизит количество семафоров, которые PostgreSQL использует для управления подключениями. Например: max_connections = 100
2. Настройка параметров ядра: Убедитесь, что параметры ядра, такие как SEMMNS и SEMMNI, настроены правильно. Эти параметры определяют максимальное количество семафоров и идентификаторов семафоров, которые могут существовать в системе. Например, для Linux можно изменить эти параметры с помощью команды sysctl: sysctl -w kern.ipc.semmns=50000 sysctl -w kern.ipc.semmni=1000
Чтобы изменения сохранялись после перезагрузки, добавьте их в файл /etc/sysctl.conf.
3. Использование альтернативных методов IPC: Если возможно, рассмотрите использование альтернативных методов IPC, таких как POSIX семафоры, вместо семафоров System V. Это может быть полезно, если вы используете систему, где семафоры System V являются ограничением.
4. Оптимизация использования памяти: Убедитесь, что параметры разделяемой памяти настроены правильно. Например, увеличьте значение SHMMAX и SHMALL, если это необходимо для вашего кластера баз данных. Для Linux это можно сделать с помощью команды sysctl: sysctl -w kernel.shmmax=17179869184 sysctl -w kernel.shmall=4194304
5. Проверка на наличие других процессов, использующих IPC: Убедитесь, что другие процессы в системе не используют семафоры и разделяемую память в больших количествах. Вы можете использовать команды, такие как ipcs, чтобы просмотреть текущее использование IPC в системе: ipcs -s ipcs -m
6. Использование меньшего числа фоновых процессов: Уменьшение числа фоновых процессов, таких как автовакуум и передатчик WAL, также может помочь уменьшить количество семафоров. Например, уменьшите значения параметров autovacuum_max_workers, max_wal_senders и max_worker_processes.
Пример настройки параметров ядра для Linux: sysctl -w kern.ipc.semmns=50000 sysctl -w kern.ipc.semmni=1000 sysctl -w kernel.shmmax=17179869184 sysctl -w kernel.shmall=4194304
Эти шаги помогут уменьшить количество ожиданий типа IPC и улучшить производительность PostgreSQL. Для более точной настройки рекомендуется провести анализ текущего использования ресурсов и оптимизировать параметры в соответствии с конкретными требованиями вашей системы.
ChatPPG - чат-бот для помощи в вопросах эксплуатации СУБД PostgreSQL и Postgres Pro. Поддержка - @ChatPPGSupport https://t.me/chatppgbot
В итоге , перспективы у живых специалистов , Service Desc самые скучные . Вот их в первую очередь , чат боты вытеснят.
Практическое применение индикатора для проведения анализа инцидентов снижения скорости СУБД .
Постановка задачи
Провести анализ инцидентов производительности СУБД-1 по данным мониторинга индикатора снижения скорости.
Дашборд в Zabbix.
Порядок проведения анализа инцидентов производительности СУБД
Определение инцидента
Инцидентом снижения производительности СУБД является событие снижения операционной скорости СУБД и одновременный рост ожиданий СУБД в течении заданного периода времени.
Приоритет инцидента определяется абсолютным значением коэффициента корреляции между значениями операционной скорости и ожиданиями :
Приоритет 4 : |коэффициент корреляции| < 0.5
Приоритет 3 : |коэффициент корреляции| >= 0.5
Окончание инцидента - отсутствие корреляции между операционной скоростью и ожиданиями СУБД.
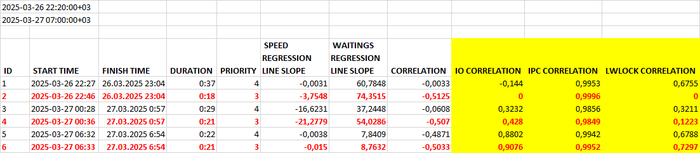
1.Отчет по инцидентам
Таблица по инцидентам за заданный период
Столбцы таблицы
ID : идентификатор инцидента
START TIME : время начала инцидента
FINISH TIME : время окончания инцидента
SPEED REGRESSION LINE SLOPE : угол наклона линии наименьших квадратов для значений операционной скорости СУБД
WAITINGS REGRESSION LINE SLOPE : угол наклона линии наименьших квадратов для значений ожиданий СУБД
CORRELATION : коэффициент корреляции между операционной скоростью и ожиданиями
IO CORRELATION : коэффициент корреляции между ожиданиями СУБД и ожиданиями типа IO
IPC CORRELATION : коэффициент корреляции между ожиданиями СУБД и ожиданиями типа IPC
LWLOCK CORRELATION : коэффициент корреляции между ожиданиями СУБД и ожиданиями типа LWLOCK
Результаты отчета:
Наибольшая корреляция между ожиданиями и типом ожидания IPC
Наименьшая корреляция между ожиданиями и типом IO
Результаты отчета:
Наибольшая корреляция между ожиданиями и типом ожидания IPC
Наименьшая корреляция между ожиданиями и типом IO
Итог:
Наибольшее влияние на снижение операционной скорости в заданный период играют ожидания типа IPC
Серверный процесс ожидает взаимодействия с другим процессом.
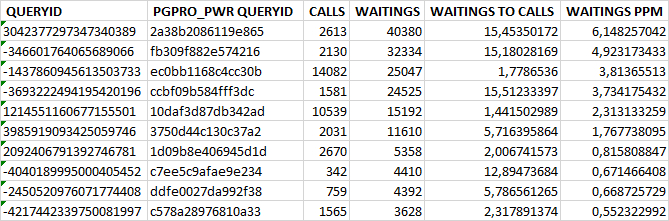
2.Отчеты по SQL запроса и типам ожидания на примере анализа по типу IPC
Ожидания типа IPC
TOP-10 SQL выражений по доле ожиданий по выражению среди всех ожиданий типа IPC
толбцы таблицы:
QUERYID : значение queryid из представления pgpro_stats
PGPRO_PWR QUERYID : шестнадцатеричное значение queryid для использования в отчетах pgpro_pwr.
CALLS : количество выполнений за период инцидентов
WAITINGS : количество ожиданий типа IPC за период инцидентов
WAITINGS TO CALLS : отношение количеств ожиданий типа IPC по SQL выражению к количеству выполнений. Ожиданий на одно выполнение.
WAITINGS PPM : относительное значение( в промилле ) ожиданий по типу IPC для данного SQL выражения ко всем ожиданиям типа IPC.
Результат
В результате анализа данных отчета , можно установить SQL запрос/запросы оказывающие наибольшее влияние на количество ожиданий типа IPC. И оптимизация которых окажет наибольший эффект на скорость СУБД.
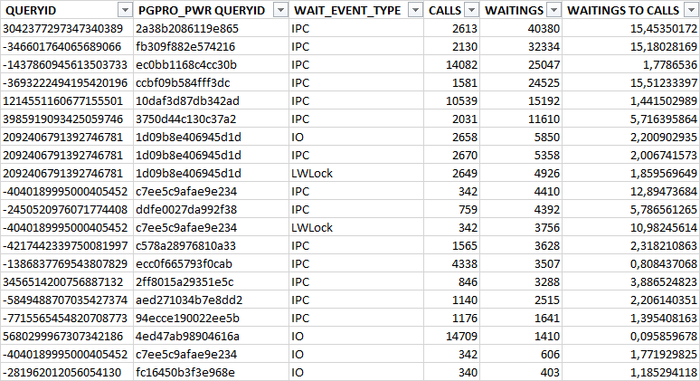
Анализ по типам ожидания IO , LWLock проводится аналогичным образом.
3. SQL выражения, имеющие набольшие значения ожиданий
Сводная таблица по SQL отсортированная по отношению количества ожиданий к количеству выполнений.
В результате анализа данных отчета , можно установить SQL запрос/запросы оказывающие наибольшее влияние на ожидания СУБД . И оптимизация которых окажет наибольший эффект на скорость СУБД.
Итоги и планы развития
Мониторинг инцидентов скорости СУБД и сбор статистической информации по инцидентам позволит собрать начальные данные для проведения анализа производительности СУБД за более длительный период времени - неделя, месяц, квартал. И послужит базой для начала работ по процессу управления проблемами производительности СУБД.
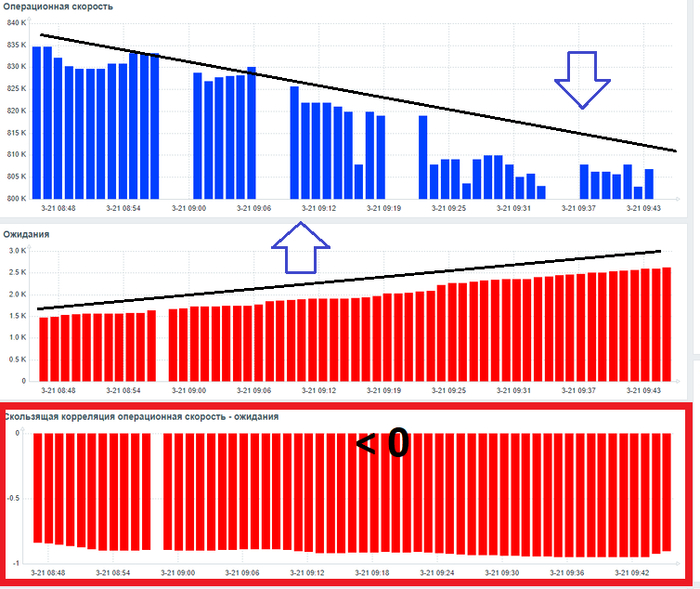
сигналом для начала работ по корреляционному анализу ожиданий СУБД может является отрицательная корреляция между значениями операционной скорости и ожиданий СУБД .
Например:
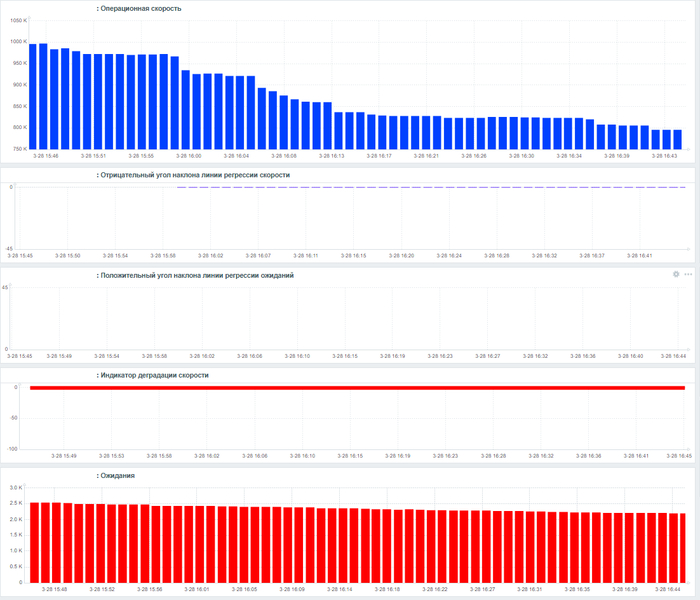
Графики мониторина операционной скорости, ожиданий и коэфициента корреляции.
Однако , важным следствием из определения понятия корреляции является то, что отрицательное значение может быть также и в случае - если операционная скорость растет, а ожидания снижаются. Является ли подобная ситуация инцидентом ? Конечно - нет.
Возможны следующие комбинации роста/cнижения значение операционной скорости и ожиданий:
Скорость растет, ожидания растут => положительная корреляция.
Скорость снижается, ожидания снижаются => положительная корреляция.
Скорость растет, ожидания снижаются => отрицательная корреляция.
Скорость снижается, ожидания растут => отрицательная корреляция.
Только вариант 4 является инцидентом снижения производительности.
Итак, для корректной работы индикатора и создания оповещения мониторинга о возможной проблеме скорости СУБД необходимо определять возникновение ситуации - отрицательная корреляция & операционная скорость снижается.
Признак снижения операционной скорости
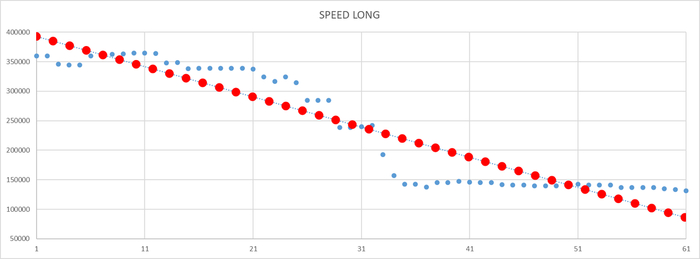
Для определения снижения операционной скорости используется встроенная функция PostgreSQL regr_slope(Y, X)
наклон линии, полученной методом наименьших квадратов по данным (X
, Y)
В качестве выборки X используются значения точки времени наблюдения, в качестве выборки Y - значения операционной скорости.
В результате графически получается примерно следующий график, если выполнить тоже самое в Excel:
Красные точки - линия тренда .
Таким образом, используя значение наклона линии, полученной методом наименьших квадратов и значение коэффициента корреляции между операционной скоростью и ожиданиями , можно сформулировать условие для создания оповещения мониторинга .
Если значение наклона линии наименьших квадратов < 0 ,
И
значение коэффициента корреляции между скоростью и ожиданиями < 0
ТО
Создать оповещение мониторинга "Инцидент деградации производительности".
В качестве уровня важности оповещения , можно использовать абсолютное значение коэффициента корреляции :
< 0.5 : низкий уровень
>= 0.5 : высокий уровень.
Практическая реализация
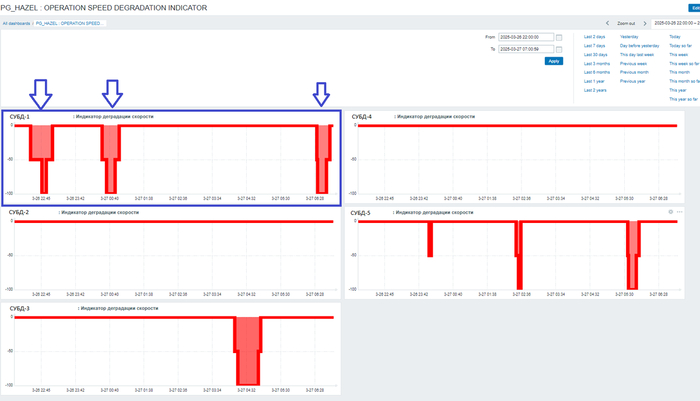
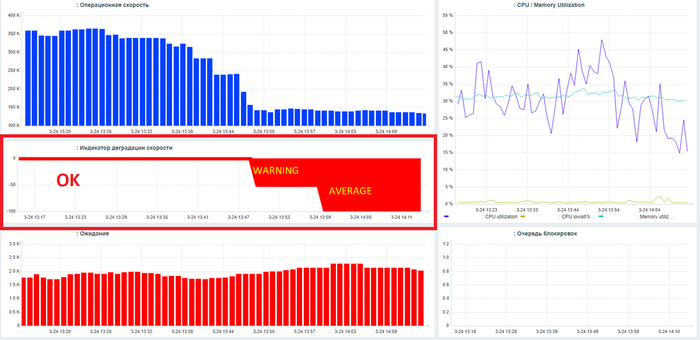
Дашборд мониторинга отдельной СУБД
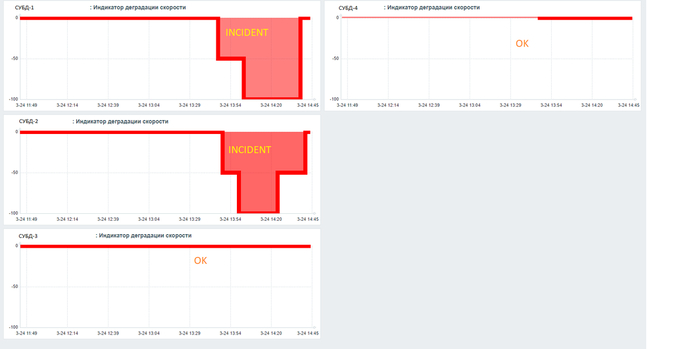
Сводный дашборд по нескольким СУБД
Итог
Использование индикатора снижения скорости СУБД позволяет автоматически создавать инцидент о деградации производительности СУБД и избавляет DBA от необходимости непрерывно следить за показателями метрик производительности и состояния СУБД.
Метрики производительности СУБД доступные для мониторинга
Операционная скорость СУБД.
Ожидания СУБД.
Коэффициент корреляции между операционной скоростью и ожиданиями СУБД.
Индикатор уровня снижения скорости СУБД - заметное снижение /сильное снижение.
Отчеты корреляционного анализа
Скорость , ожидания и типы ожидания кластера .
Статистика выполнения и ожиданий SQL выражений по заданному типу ожиданий wait_event_type.
Статистика выполнения (calls) , ожиданий(wait_event_type), событий ожиданий (wait_event) для заданного SQL выражения(queryid) и типа ожидания (wait_event_type) .
Планы развития
Тестирование методики корреляционного анализа и обнаружения проблемных SQL выражений при продуктивной нагрузке на СУБД.