Корреляционный анализ ожиданий СУБД PostgreSQL - продолжение
Взято с основного технического канала Postgres DBA ( возможны правки и дополнения в исходной статье ).
Хирург и DBA это холодная голова и горячее сердце.
Начало :
Продолжение тестирования методологии использования корреляционного анализа для поиска проблемных SQL запросов при продуктивной нагрузке на СУБД .
Постановка задачи:
Проанализировать причины снижения скорости СУБД и найти проблемные запросы:

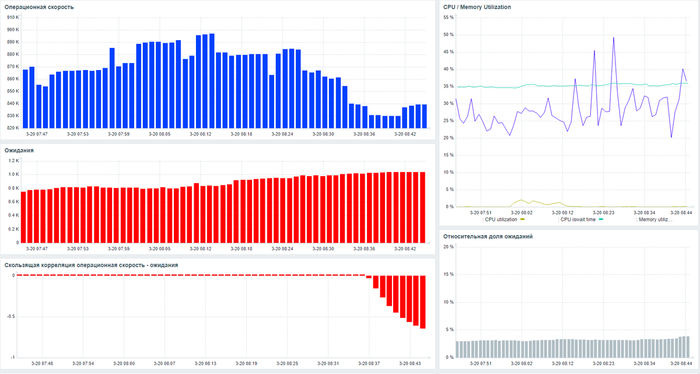
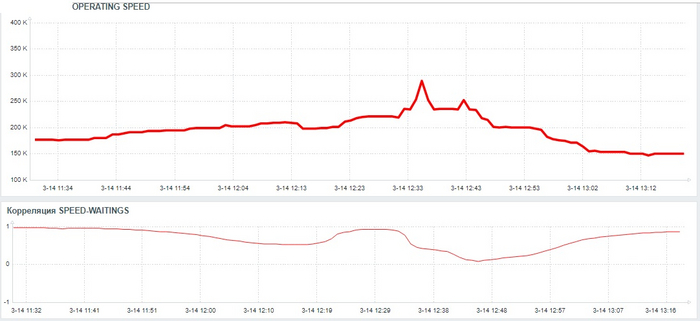
Дашбоард мониторинга производительности СУБД
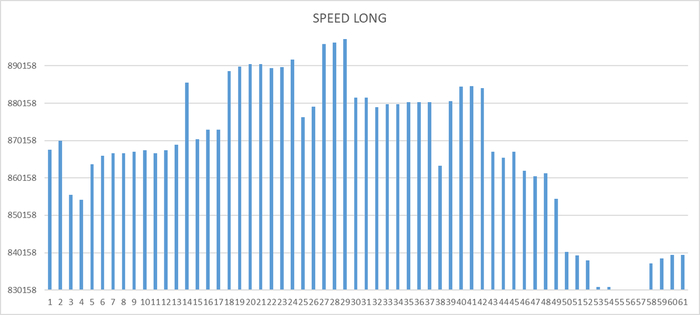
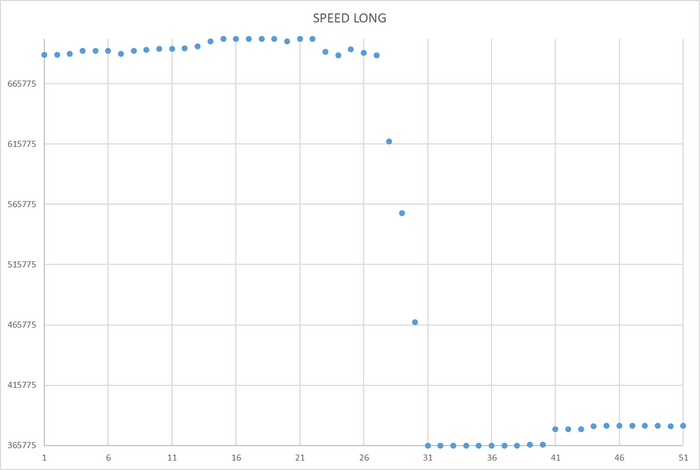
Операционная скорость СУБД - снижается.
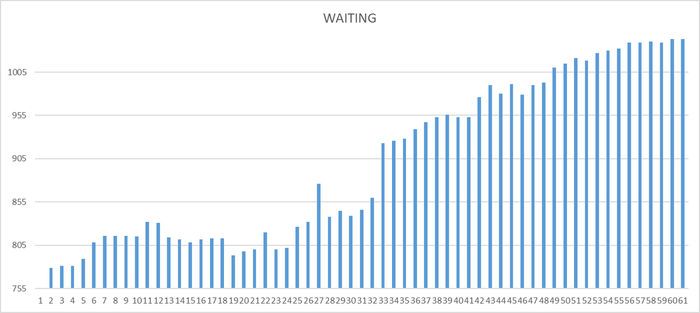
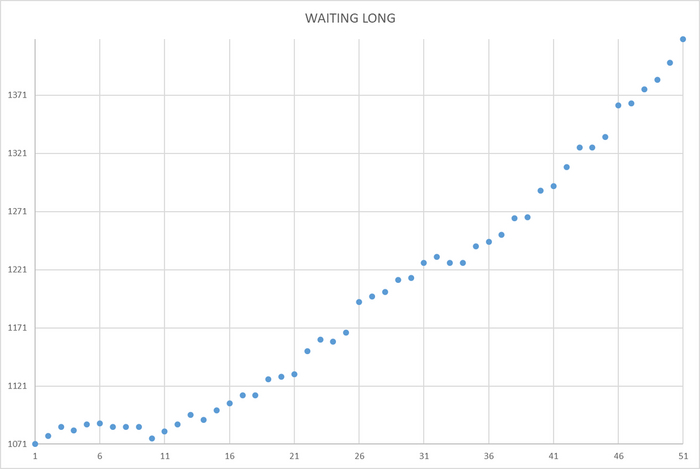
Ожидания СУБД - растут.
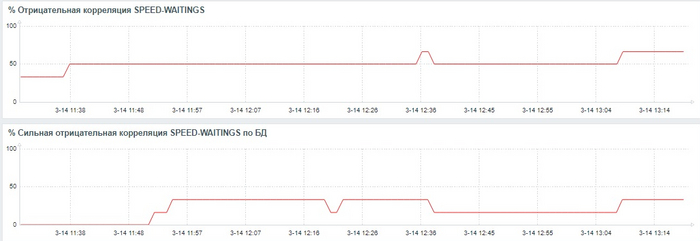
Метрика относительной доли ожиданий - исключена из анализа.
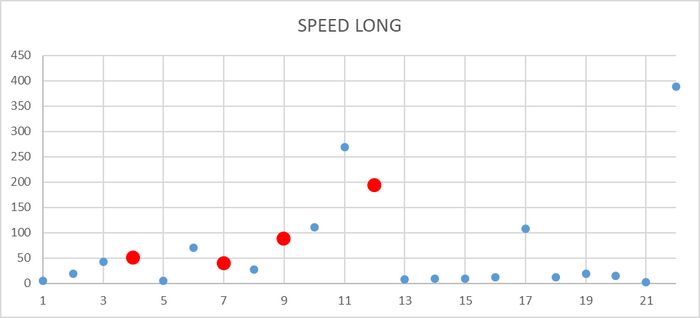
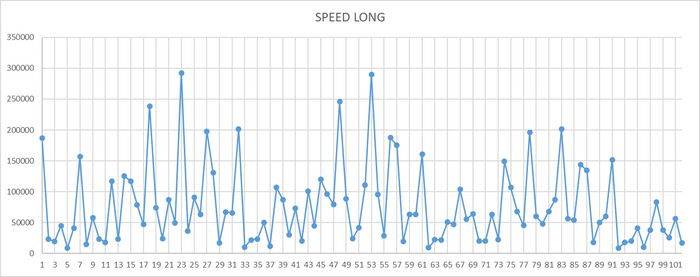
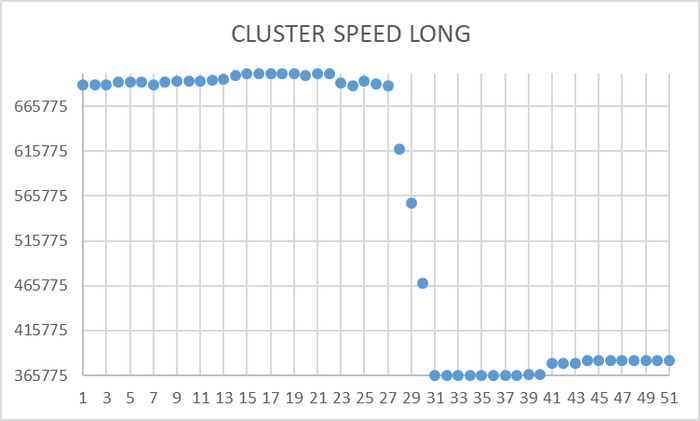
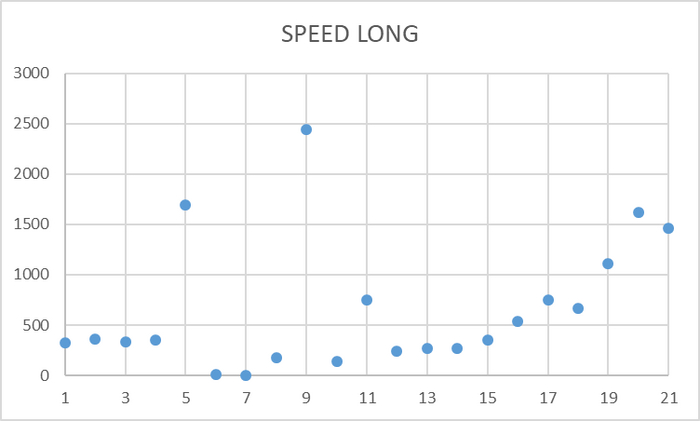
Операционная скорость на уровне кластера

Ось X - точка наблюдения Ось Y - значение операционной скорости
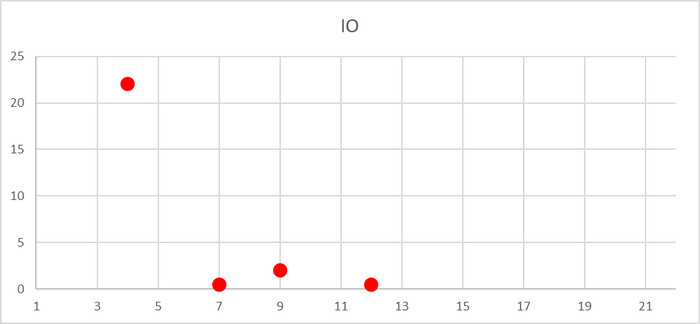
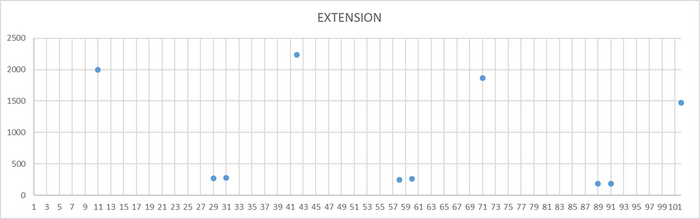
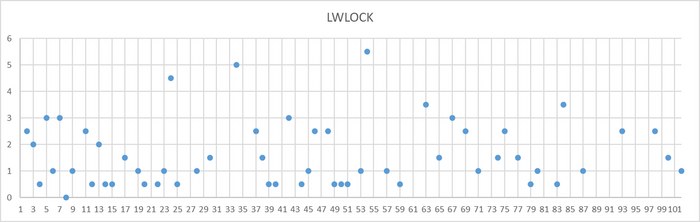
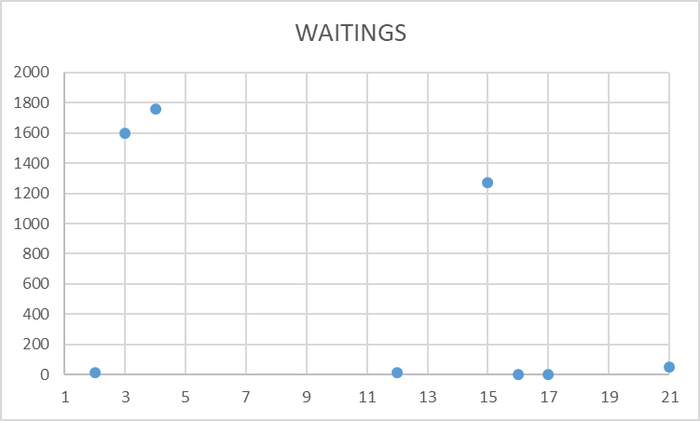
Ожидания на уровне кластера
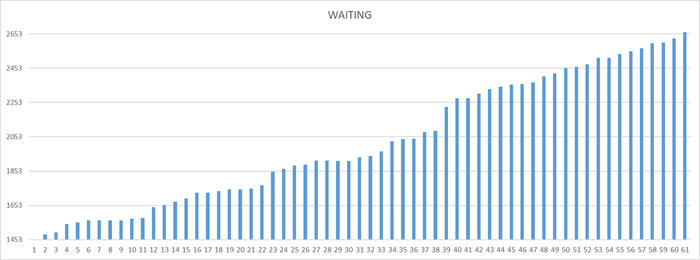
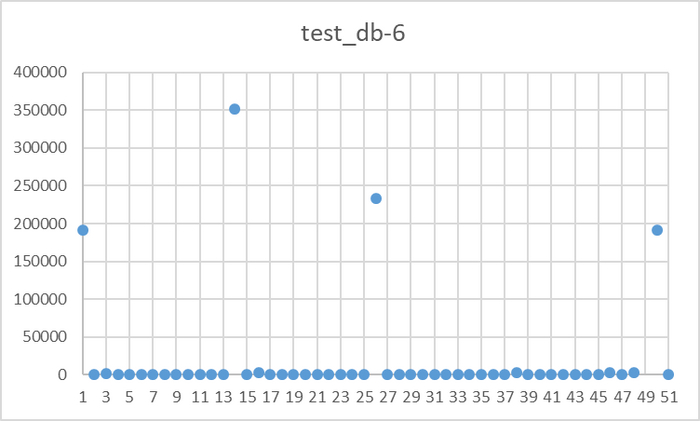
Ось X - точка наблюдения Ось Y - общее количество ожиданий СУБД
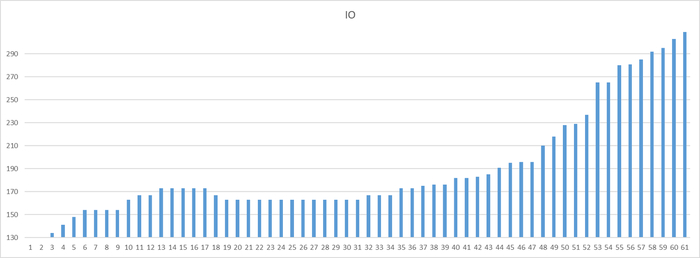
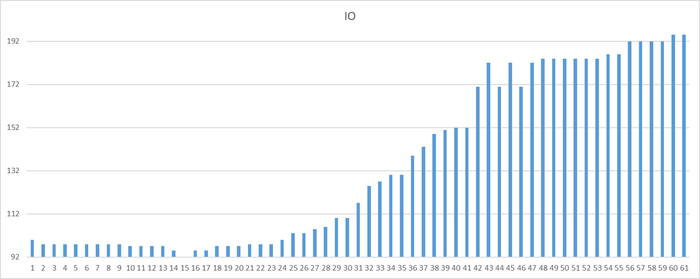
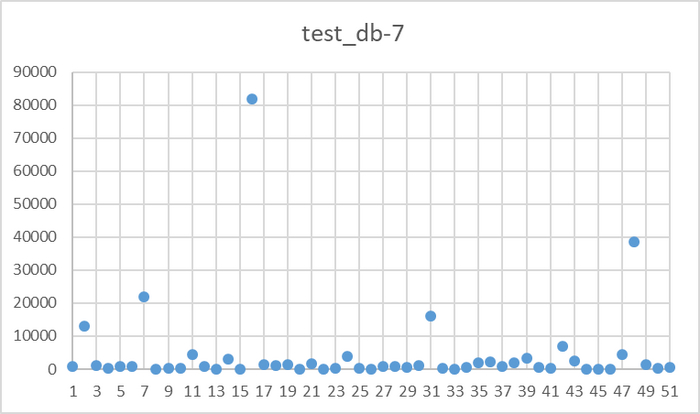
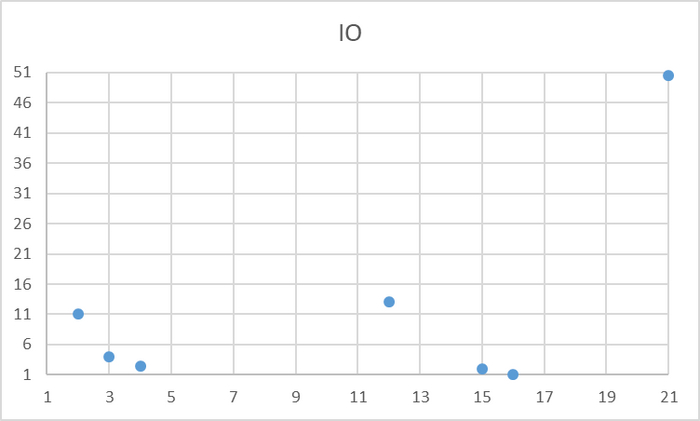
Ось X - точка наблюдения Ось Y - количество ожиданий типа IO
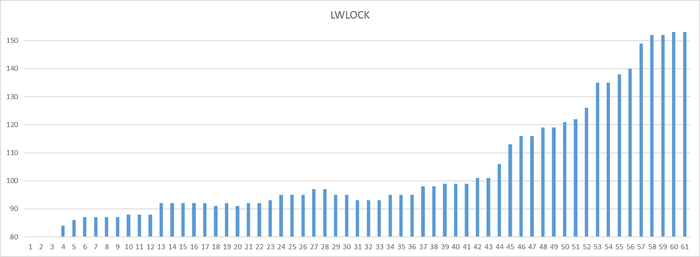
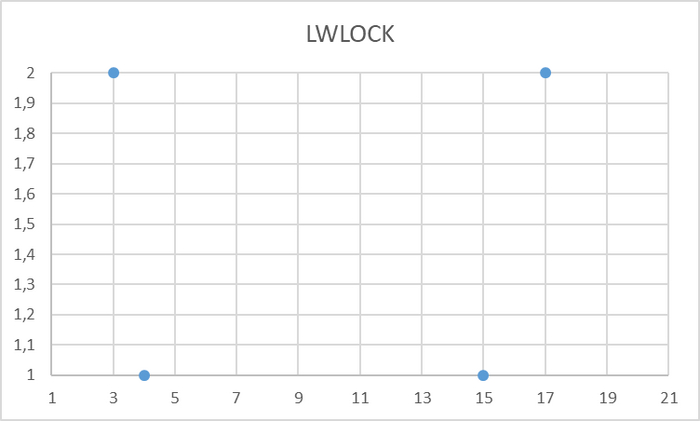
Ось X - точка наблюдения Ось Y - количество ожиданий типа LWLock
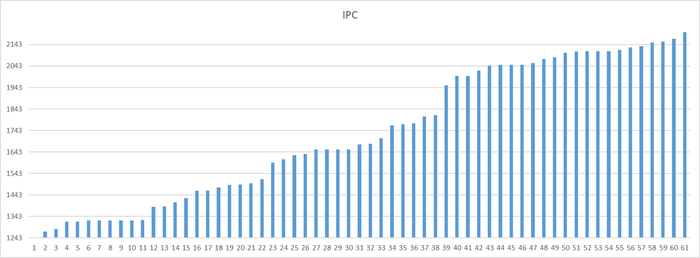
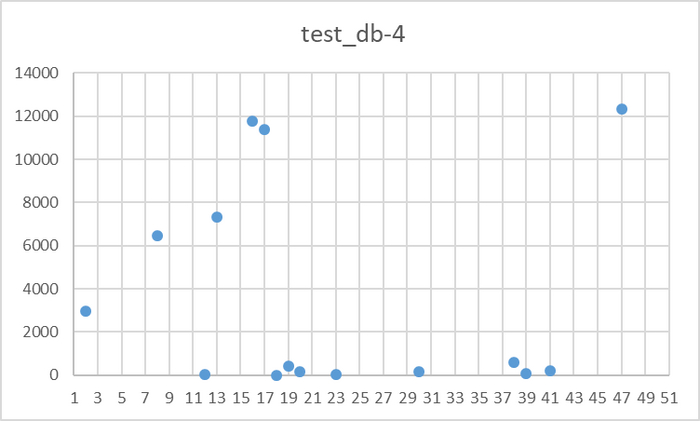
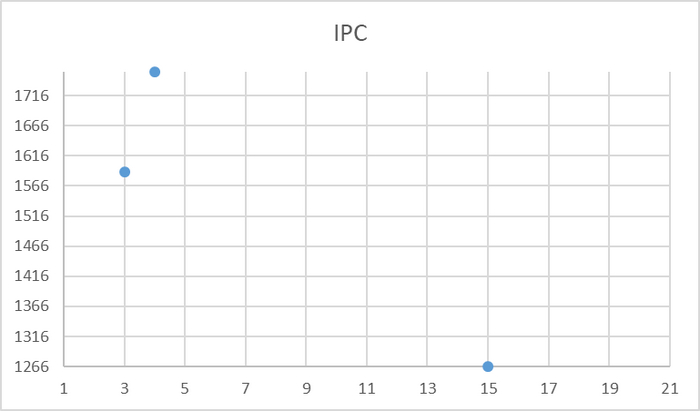
Ось X - точка наблюдения Ось Y - количество ожиданий типа IPC
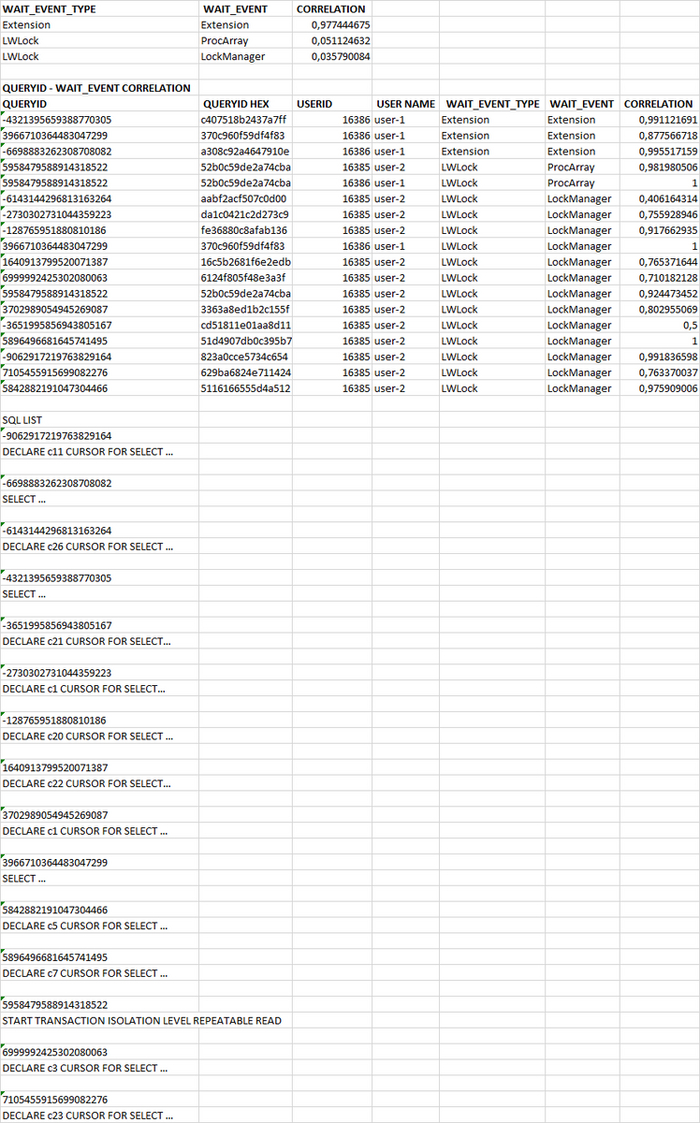
Корреляционный анализ ожиданий и определение потенциально проблемных SQL запросов
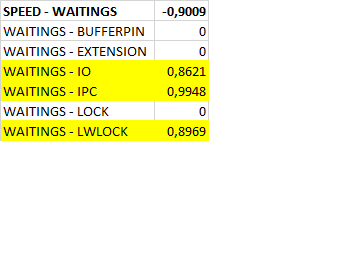
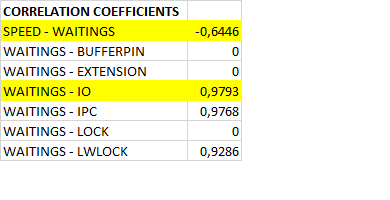
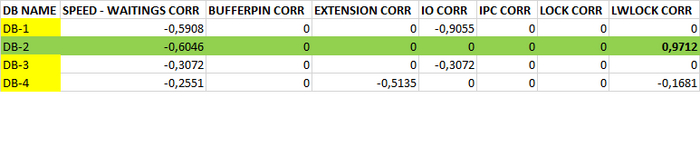
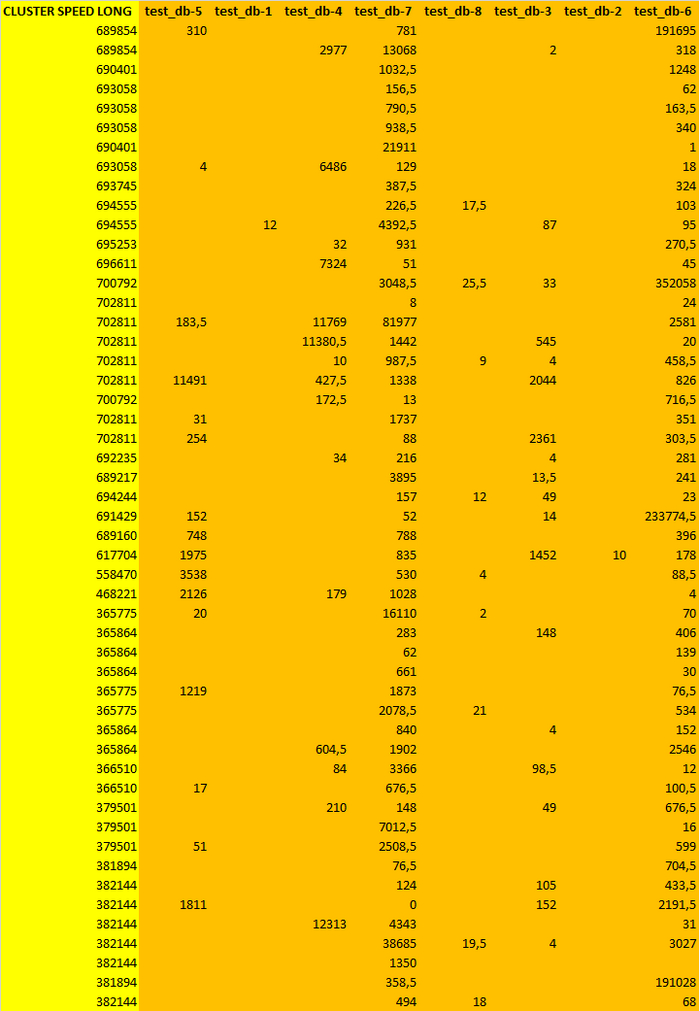
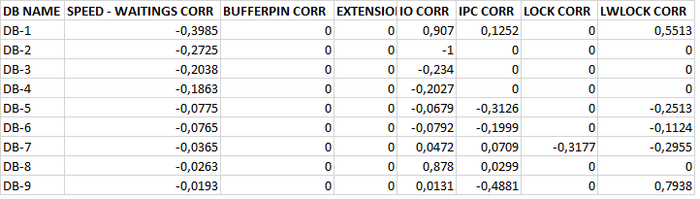
Таблица коэффициентов корреляции
Сильная отрицательная корреляция между скоростью и ожиданиями .
Наиболее сильная положительная корреляция между всеми ожиданиями и ожиданиями типа IPC.
Сильная положительная корреляция между всеми ожиданиями и ожиданиями типа LWLock , IO .
Корреляционный анализ на уровне запросов SQL по ожиданию типа IPC

TOP-10 таблицы коэффициентов корреляции для SQL запросов с ожиданиями типа IPC
Столбцы таблицы
QUERYID : id SQL запроса
PGPRO_WR_QUERYID : HEX значение queryid , для использования в отчетах pgpro_pwr.
CORRELATION : коэффициент корреляции между ожиданиями типа IPC по всем SQL запросам и ожиданиям типа IPC по конкретному запросу.
CALLS : общее количество выполнений запроса за анализируемый период.
WAITINGS : Ожидания типа IPC по конкретному запросу.
WAITINGS TO CALL : Отношение количество ожиданий к количествe выполнений. Среднее количество ожидания за одно выполнение.
WAITINGS PCT : Относительная доля (промилле) количества ожиданий типа IPC для данного SQL запроса в общем количества ожиданий типа IPC по всем запросам.
Таблица отсортирована по столбцам "WAITINGS PCT" DESC , "WAITINGS TO CALL" DESC , "CORRELATION" DESC .
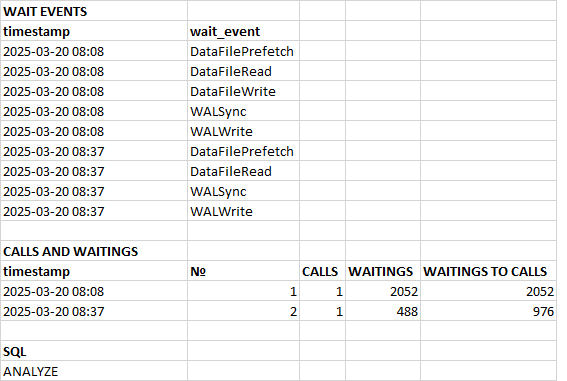
Потенциально проблемный запрос - 3985919093425059746
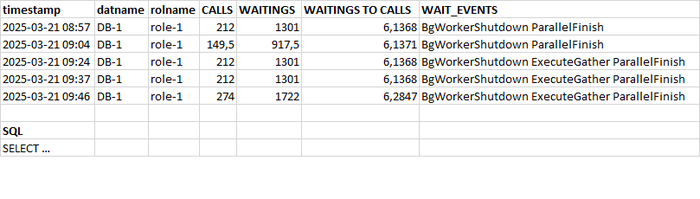
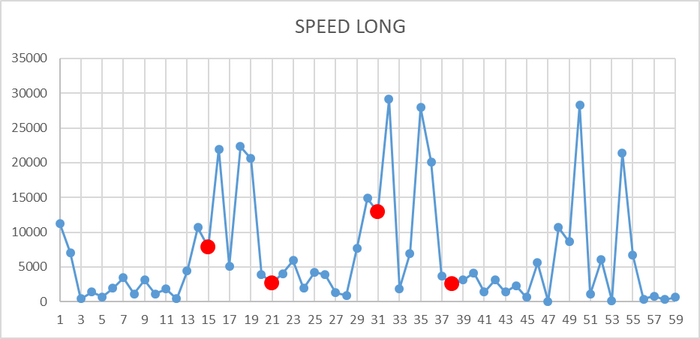
История выполнений и ожиданий запроса 3985919093425059746
События ожидания:
BgWorkerShutdown Ожидание завершения фонового рабочего процесса.
ParallelFinish Ожидание завершения вычислений параллельными рабочими процессами.
ExecuteGather Ожидание активности дочернего процесса при выполнении узла плана Gather.
Корреляционный анализ на уровне запросов SQL по ожиданию типа LWLock
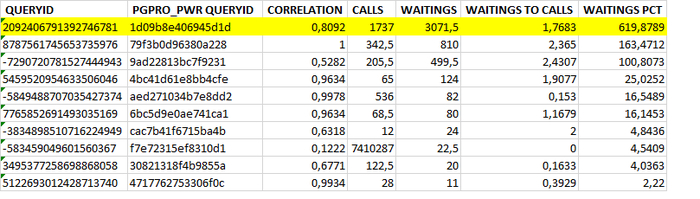
TOP-10 таблицы коэффициентов корреляции для SQL запросов с ожиданиями типа LWLock.
Столбцы таблицы
QUERYID : id SQL запроса
PGPRO_WR_QUERYID : HEX значение queryid , для использования в отчетах pgpro_pwr.
CORRELATION : коэффициент корреляции между ожиданиями типа LWLock по всем SQL запросам и ожиданиям типа LWLock по конкретному запросу.
CALLS : общее количество выполнений запроса за анализируемый период.
WAITINGS : Ожидания типа LWLock по конкретному запросу.
WAITINGS TO CALL : Отношение количество ожиданий к количествe выполнений. Среднее количество ожидания за одно выполнение.
WAITINGS PCT : Относительная доля (промилле) количества ожиданий типа LWLock для данного SQL запроса в общем количества ожиданий типа IPC по всем запросам.
Таблица отсортирована по столбцам "WAITINGS PCT" DESC , "WAITINGS TO CALL" DESC , "CORRELATION" DESC .
Потенциально проблемный запрос - 2092406791392746781
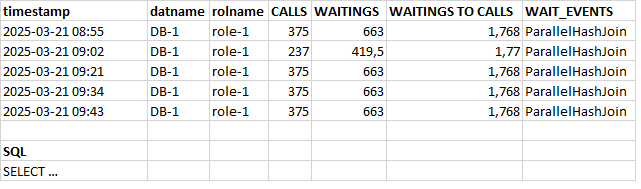
История выполнений и ожиданий запроса 2092406791392746781
События ожидания:
ParallelHashJoin Ожидание синхронизации рабочих процессов в процессе выполнения узла плана Parallel Hash Join.
Корреляционный анализ на уровне запросов SQL по ожиданию типа IO
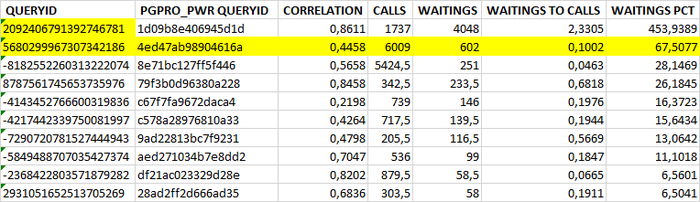
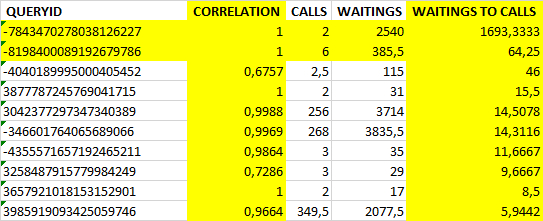
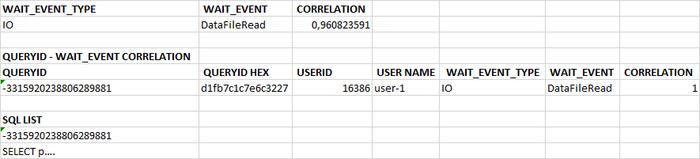
TOP-10 таблицы коэффициентов корреляции для SQL запросов с ожиданиями типа IO
Столбцы таблицы
QUERYID : id SQL запроса
PGPRO_WR_QUERYID : HEX значение queryid , для использования в отчетах pgpro_pwr.
CORRELATION : коэффициент корреляции между ожиданиями типа IO по всем SQL запросам и ожиданиям типа IO по конкретному запросу.
CALLS : общее количество выполнений запроса за анализируемый период.
WAITINGS : Ожидания типа IO по конкретному запросу.
WAITINGS TO CALL : Отношение количество ожиданий к количествe выполнений. Среднее количество ожидания за одно выполнение.
WAITINGS PCT : Относительная доля (промилле) количества ожиданий типа IO для данного SQL запроса в общем количества ожиданий типа IPC по всем запросам.
Таблица отсортирована по столбцам "WAITINGS PCT" DESC , "WAITINGS TO CALL" DESC , "CORRELATION" DESC .
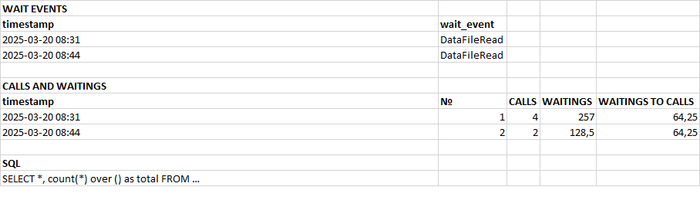
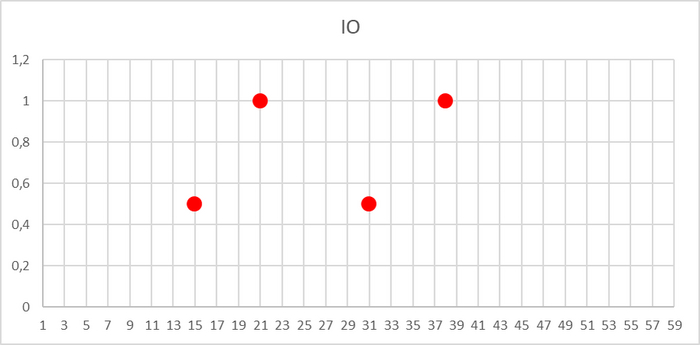
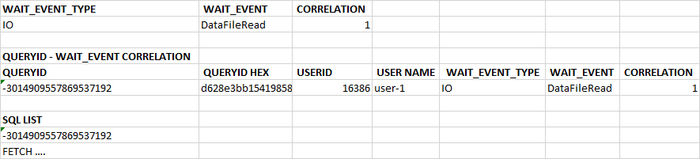
Потенциально проблемный запрос - 5680299967307342186
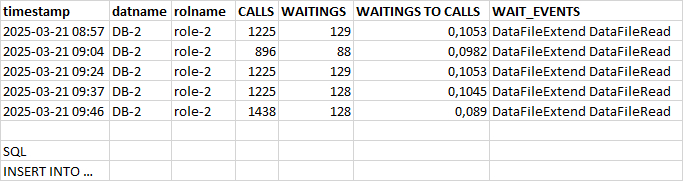
История выполнений и ожиданий запроса 5680299967307342186
События ожидания:
DataFileExtend Ожидание расширения файла данных отношения.
DataFileRead Ожидание чтения из файла данных отношения.
Итог
Корреляционный анализ ожиданий СУБД может быть использован для поиска проблемных SQL запросов и первоначального анализа проблемы и путей оптимизации SQL запросов.