Вы не поверите, но я уже и разработчиков Kandinsky 2.2 спрашивал, что такое CFG Scale в фундаментальном смысле, и нейронщиков всех мастей, однако так не получил внятного ответа. От обывательских блогов меня вообще теперь тошнит, ибо там одно и то же: параметр CFG Scale увеличивает силу следования подсказке... И все как бы, окей — сами разберемся.
Так вот, я начал с базы и открыл научные статьи родоначальников метода classifier free guidance scale. Прикреплю ссылки на них сразу же, чтобы вы тоже могли ознакомиться. Вот статья, посвященная именно CFG Scale для диффузных моделей, а вот статейка о применении данного метода в современных языковых моделях.
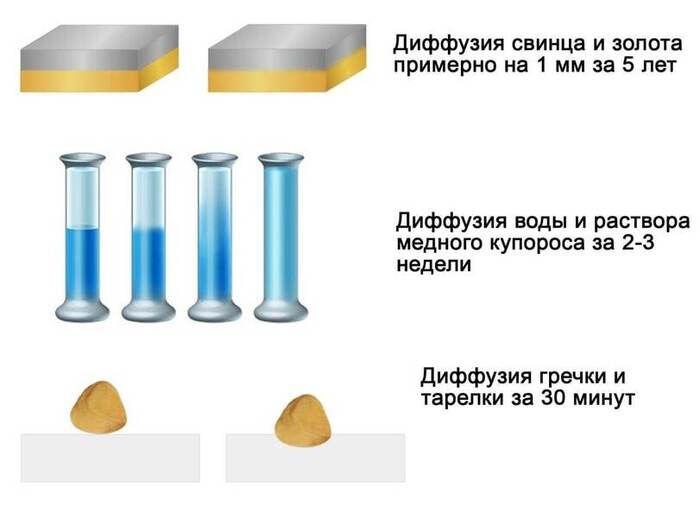
Меня поразил тот факт, что метод CFG Scale и позволил диффузным моделям родиться. До них были GAN-модели, которые совмещали в себе генератор и дискриминатор. Дискриминатор, по-другому, это классификатор. Т.е. моделька сначала генерит изображение, а потом вторая полноценная модель оценивает его на вшивость и корректирует вместе с первой.
Из этого вытекают минусы: например, нужно вместе с одной моделью обучать и вторую (работы в два раза больше). Также нужно, чтобы железо тянуло сразу две модели, ибо они задействуются в паре.
Метод же SFG Scale позволил задействовать только одну модель — диффузнную, т.е. обучать вторую больше не нужно. Чтобы вы понимали, механика описывается парой строк кода. Думаю, вы смекаете, что это намного проще дополнительной полноценной модели, которую еще хранить где-то нужно.
В общем, благодаря CFG Scale мы получили более быстрое и стабильное обучение моделей, которые еще и по точности не уступают GAN-ам, а также могут генерировать изображения в разных разрешениях. Плюс дополнительные надстройки в виде LoRA стали доступны.
Метод Classifier-Free Guidance Scale использует безусловную и условную генерации, которые перемножаются друг с другом. Грубо говоря, сначала создается изображение без учета текстовой подсказки, а затем с ней. Чем выше CFG Scale, тем больше будет доминировать условное изображение.
Это нужно для того, чтобы мы могли получить либо больше вариативности генерации, либо больше точности — того самого следования текстовой подсказке. Получается, что чем ниже CFG Scale, тем нейронка свободнее в своих действиях, а чем больше — наоборот, скованнее.
Так как формула просчета CFG Scale и перемножения двух генераций простая, то и минусы из этого следуют такие же простые и очевидные. Всем ясно, что математематические формулы можно совершенствовать до бесконечности, повышая точность и скорость. И это делают, сейчас разберем как.
Вот вам наглядная демонстрация влияния CFG Scale на качество генерации.
Как вы можете видеть, первое изображение при низком CFG Scale близко к безусловному, т.е. не учитывающем классы из текстовой подсказки. При высоком же значении этого параметра мы получаем те самые минусы математики, о которых я говорил выше. Нейросеть как бы пытается достать генерацию, выдавить ее через трафарет, максимально четко охарактеризовать объект.
Помните лизуна в сетке? Представьте, что когда вы сжимаете его, то увеличиваете тем самым CFG Scale. Т.е. вы проталкиваете подсказку через некий трафарет (сетка — это безусловное базовое изображение, а лизун — это условное изображение, сформированное подсказкой).
Теперь посмотрим на чрезмерное увеличение контрастности изображения в Photoshop. Принцип по сути очень похож: мы пытаемся усилить цвета и как бы выделить на фоне остальных, т.е. выжать, как того самого лизуна.
Снова возвращусь к минусам математики и ее бесконечном улучшении. Взгляните на примеры выше и сравните с предыдущими. Высокие значения уже не так коверкают генерацию, как раньше, а помогло в этом расширение CFG Dynamic trashholing, которое не выдавливает, а спиливает ненужные части. Вместе с лишним уходит и освещенность, но это все же лучше артефактов. Суть метода в том, чтобы как бы отодвигать яркие пиксели назад, тем самым уменьшая эффект ярких артефактов.
Про данное расширение и другие способы увеличить качество ваших генераций в десятки раз у меня, кстати, есть ролик.
Еще одной иллюстрацией механики CFG Scale можно считать два негативных промпта у нейросети Kandinsky 2.1, один из которых является безусловным, а другой условным. При CFG Scale < 1 отрицательная подсказка игнорируется.
По ссылке вы можете найти официальную документацию Kandinsky 2.1, а также прочитать буклет Google о classifier-free guidance scale, на который ссылаются разработчики Кандинского.
А по итогу мы имеем представление о методе, который является одним из родителей диффузных моделей, к примеру, Stable Diffusion или Midjourney.
Теперь нам не нужен дискриминатор, а модель генерирует изображение за несколько шагов, что дает массу простора в контроле генерации. Мы можем и ControlNet подрубать, и LoRA, всякие разные расширения, дополнения.
Но не только ControlNet-ом хороши современные нейронки, но и целыми каскадами других, не менее масштабных сетей. У Midjourney, к примеру, есть сеть-генератор формы объекта, граней, апскейла, раскраски и много чего еще. С GAN-моделями такое было бы практически невозможно совместить.
Если вы хотите глубже погрузиться в диффузные нейросети, то советую прочитать этот материал, который мне также помог в изучении темы. Также продублирую статью о методе CFG Scale в диффузных моделях, а также статью о применении методики в языковых моделях.
Congratulations, вы выжили!
Теперь вы разбираетесь в том, что такое CFG Scale в нейросетях. Буду рад обратной связи и вашим комментариям, а также приглашаю в свой телеграм чат, где отвечу на все вопросы касаемо SD.
Буду рад видеть вас в телеграм-канале, где я собираю лучшие гайды по Stable Diffusion. А если не найду, то пишу сам.