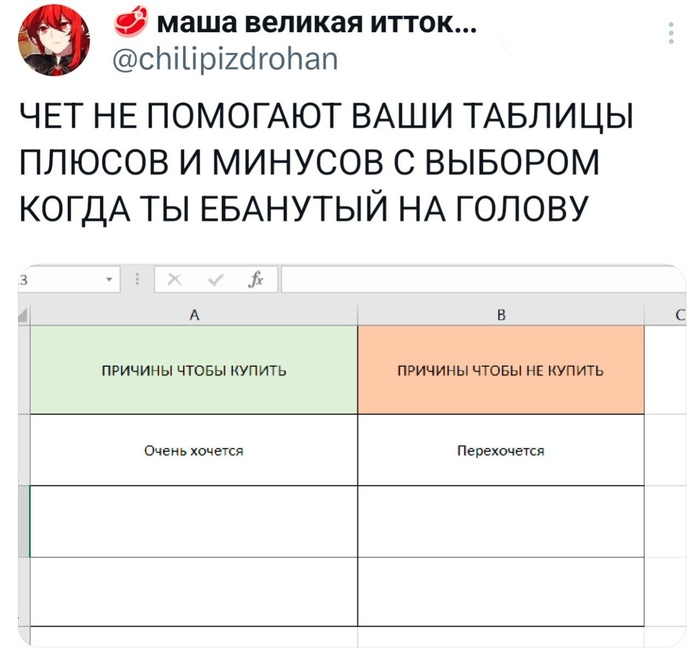
Утильсбор. Табличка
Занимательная табличка по утилю. Оставлю тут на память.
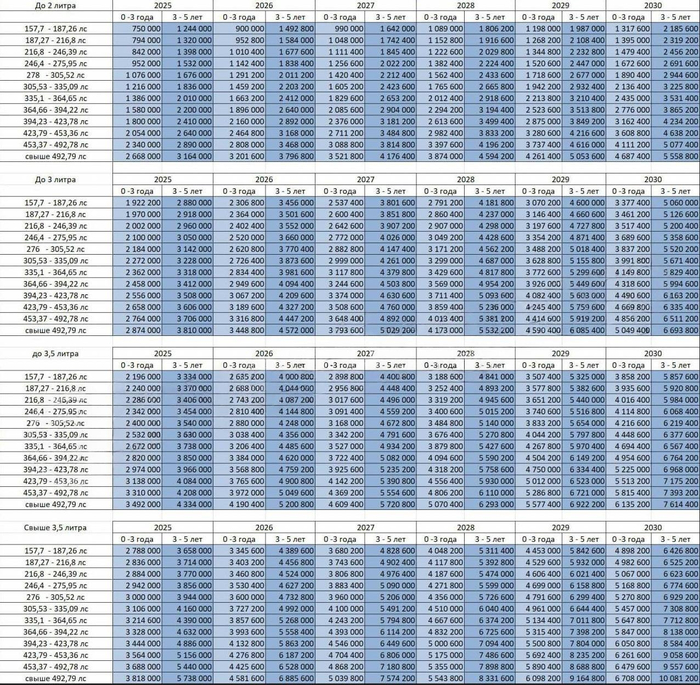
Занимательная табличка по утилю. Оставлю тут на память.

... или чем ещё можно заменить
Я всё ещё продолжаю писать открытую энциклопедию Юникода и замену стандартной Таблице символов. Качать тут.
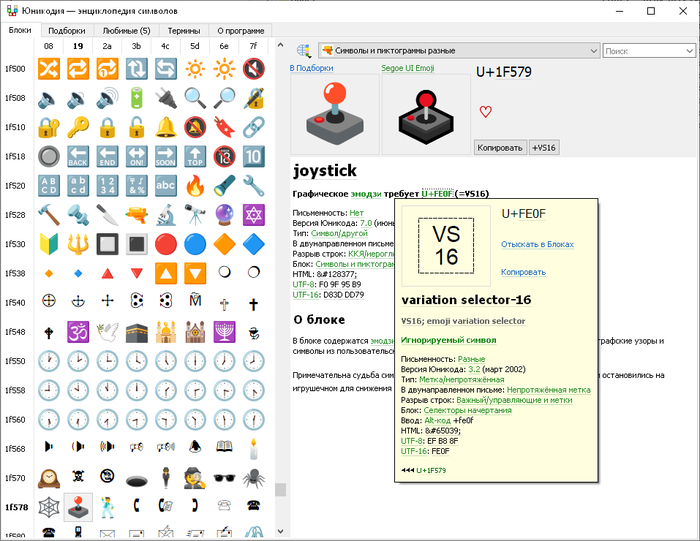
Скриншот
Вот отчёт за последние полгода.
Теперь, чтобы увидеть символ и скопировать тривиальную информацию по нему, можно просто ткнуть на ссылке.
Панель Подборок из синей стала зелёной: теперь это не переход.
Внизу ссылочка «◀◀◀ U+FE0F». Она во всех всплывающих окнах: если вдруг вы закрыли, или любопытство завело вас непонятно куда, вы легко можете вернуться туда, где были. История запоминается на целых 100 шагов.
Эмодзи. Обратите внимание на балерину выше: подтянул свежую библиотеку Google Noto. Только косатку оставил свою: ну не получился у Гугла хищный зубатый кит.

Эмодзики Google Noto
Флаг Сирии заменил на бенладенский, вслед за Ябблом.

Бенладенский флаг Сирии
Египетские. Сейчас они обслуживаются тремя шрифтами.
Google Noto: проверен египтологами. Низкие кегли совсем не держит. Покрывает базовый блок 2009 года.
NewGardiner: нарисован египтологом, но единичные ошибки есть. Низкие кегли отлично держит. Коряв как чёрт. Покрывает подтверждённые иероглифы (600 расширенных намеренно опущены).
Мой, основанный на JSesh (программе-редакторе египетских текстов). Низкие кегли неплохо держит. Покрытие рандомное. Пришлось проверять и перерисовывать, но такая красотища! Разногласия решались простым большинством из трёх источников: изображения Юникода, описания Юникода и NewGardiner.
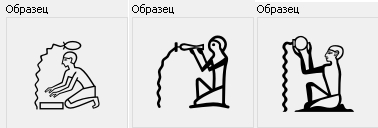
Жанровые сцены (разные, но близкие) тремя шрифтами: Noto, GewGardiner, JSesh
Шрифт буду потихоньку расширять, пока буду жив, и последовательность такая.
Стадия 1. Три шрифта в сумме покрывают все египетские иероглифы. Выполнено в июле, нарисовано и перерисовано несколько десятков иероглифов.
Стадия 2. Все символы моего шрифта проверены на простейшую корректность. Выполнено только что, сделано более 600 иероглифов. Главный вопрос — борода: у египтян короткая, у фараонов длинная, у богов крючком.
Стадия 3. Шрифт растяну на 1100 символов основного блока. Будет ХЗ когда, предполагаемый срок — после Нового года. Рассчитываю на 200…300 иероглифов работы.
Стадия 4. Буду поддерживать все египетские иероглифы. Будет минимум через полтора года и 800 иероглифов.
Поставил на свой шрифт такие требования: 1) если человек держит что-то, оно всегда будет изображаться гипертрофированно; 2) если минимальная причёска и ничего не говорится про бороду — то бороды нет; 3) только очень близкие символы приводятся в единый стиль.
Тангутские. Просто нашёлся человек, нарисовавший всё, что было.

Новые тангутские иероглифы
Арабский. Он же нарисовал временные изображения арабских лигатур.
И Сулейман ибн Дауд — мир с ними обоими! — приказал принести два сосуда: один медный, а — другой глиняный, и заточил меня в глиняном сосуде, а брата моего, Омара Хоттабовича, — в медном.
Лазарь Лагин. Старик Хоттабыч. — М: 1959
Вот такие стандартные фразы часто заменяются лигатурами (склейками), примерно такими.

Слева — профессиональная (Scheherezade New). Справа — затычка, сделанная тем китайцем
Китайские. Китаевед Эндрю Уэст стал более публично работать над своим шрифтом, я с ним советовался, проверял его на ошибки… и вдруг он неожиданно помер! Что с ним дальше делать, просто не знаю: шрифт-то отличный, просто больше никем не поддерживается. Оставил небольшую «пасхалку» в его память, кто найдёт…
Нашёл более удачную библиотеку преобразования GlyphWiki→SVG, и теперь китайские подскочили в качестве.
Плохие новости для Windows 7 и необновлённой 10-ки: теперь самый-самый резервный китайский шрифт — новый стандартный SimSun-ExtG. Простите уж, и до этого были тофу — будет больше.
Нашёлся турок, и мы с ним вместе сделали неплохой перевод.
Турецкий перевод
А вот японский несколько застоялся: японец выхаживает серьёзно больную жену.
И тут получилась проблема: я не могу быстро изменить языки, которые не знаю. А ведь есть фразы типа «в базовой плоскости Юникода осталось 16 нераспределённых символов», или «изобретатель маджонг-пасьянса прикован к коляске, но жив» — пока истинны, но может измениться. Вот приходится писать что-то вроде «жив на 2025», и это 2025 — особый шаблон. Если узнаю, что умер,— напишу. А не известные мне языки продолжат гласить: жив на такой-то год.
Обнаружилась ошибка: поиск неизвестного флага давал ошибочную строку. После разговоров с пользователем решил не убирать, только облагородил.

Поиск «XA»
Докрутил поиск в египетских иероглифах. Иероглифы намеренно имеют пониженный приоритет.
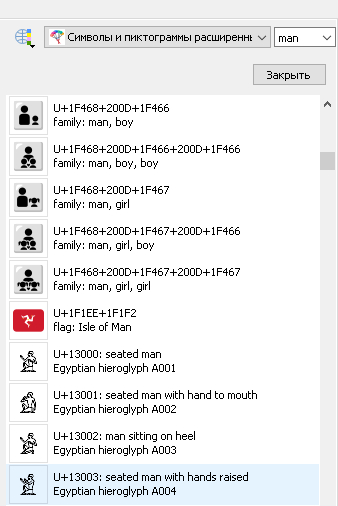
Поиск «man»
Перебраны короткие словечки: где они играют роль, а где нет.
Поиск «by»
Почему сверху Белоруссия, понятно. Почему второй — именно этот слог письма и? А потому, что именно там BY — не предлог, а нечто значимое!
И… довольно странная просьба. Дело в том, что за обработку эмодзи отвечают сразу три подсистемы: вписанная в шрифт программа, типографский движок и высокоуровневая типографская библиотека где-то в прикладной проге. В результате такого разделения ответственности получается, что определённые нестандартные последовательности, тем не менее, корректно отображаются картинками-эмодзиками. Такие последовательности делятся на 1) минимально квалифицированные (скорее всего, отобразятся), 2) неквалифицированные (отобразятся, если будет угадан шрифт), и 3) странные (полагаются на особую реализацию эмодзи-шрифта).
Просили декодировать такие странные эмодзи.
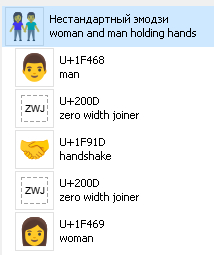
Стандартный код для него — просто 1F46B
Все такие нестандартные эмодзи у меня делятся на три категории: 1) поменяны местами мужчина/женщина, мальчик/девочка; 2) существует более короткая последовательность; 3) оба сразу.

Минимально квалифицированный: не хватает VS16 после сердечка
Спасибо за внимание!
INSERT — это оператор для добавления новых строк в таблицу.
Классика выглядит так:
INSERT INTO customers (name, age, city)
VALUES ('Оля', 28, 'Москва');
Главные слова:
INSERT INTO — куда добавляем,
VALUES — что именно добавляем.

А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
При вставке значений в таблицу можно выделить одиночную вставку и массовую вставку.
Одиночная - это когда в запросе содержится вставка одной строки, а массовая - нужно вставить больше чем одну строку.
INSERT INTO products (name, price) VALUES ('Яблоки', 100);
INSERT INTO products (name, price) VALUES ('Груши', 120);
-- и так 1000 раз 😅
INSERT INTO products (name, price)
VALUES
('Яблоки', 100),
('Груши', 120),
('Бананы', 150);
Один INSERT на 1000 строк работает быстрее, чем 1000 отдельных запросов, потому что база открывает и закрывает транзакцию только один раз.
Транзакция — это логическая единица работы с базой данных, набор действий (обычно INSERT, UPDATE, DELETE и т. д.), которые выполняются как одно целое.
База гарантирует, что или все действия внутри транзакции будут выполнены, или не выполнится ни одно.
Например:
Перевод денег с карты на карту.
Снять деньги с карты А.
Зачислить деньги на карту Б.
Если выполнить только первый шаг, а второй не получится — деньги «пропадут».
Транзакция гарантирует, что либо оба шага выполнятся, либо оба отменятся.
Так вот, даже если мы явно в коде не прописываем начало и окончание транзакции, то наша база автоматически оборачивает наш запрос началом и окончанием транзакции
BEGIN;
INSERT INTO products (name, price) VALUES ('Яблоки', 100);
COMMIT;BEGIN;
INSERT INTO products (name, price) VALUES ('Груши', 120);
COMMIT;-- и так 1000 раз 😅
BEGIN;
INSERT INTO products (name, price)
VALUES
('Яблоки', 100),
('Груши', 120),
('Бананы', 150);
COMMIT;
Но при этом вставлять одним запросом млн строк - это плохо. Можно словить блокировку. Поэтому для большого объема вставки - лучше дробить на несколько маленьких частей.
Оптимальный размер батча — подбирается экспериментально. Обычно от 5k до 50k строк за один заход.
При вставке данных в таблицу у нас часто используется уникальный идентификатор строки, часто этот идентификатор является автоинкрементом, т.е. база сама записывает значение в это поле.
CREATE TABLE users (
id SERIAL, -- автоинкремент
name TEXT
);
INSERT INTO users (name) VALUES ('Оля'); -- id = 1
INSERT INTO users (name) VALUES ('Маша'); -- id = 2
Каждый INSERT добавляет новую запись, а автоинкремент гарантирует уникальный идентификатор для этой строки.
Без него нужно было бы самому считать, какой следующий номер ставить.
Автоинкремент экономит время и предотвращает ошибки.
Но автоинкремент не гарантирует, что значения в поле id будут "последовательными", он гарантирует, что значения в этом поле будут уникальными.
Получается, что при INSERT в поле с автоинкрементом могут быть "дырки".
Это получается, например, в следующих кейсах:
1. отмененная вставка:
- Сделали INSERT, база выделила id = 5.
- Транзакцию откатили (ROLLBACK).
- Id 5 пропал, следующие вставки идут с 6.
2. Удаление строк:
- Если удалить записи, то номера исчезнут, но новые не «подтянутся» к освободившимся.
3. Параллельная вставка:
- Две транзакции одновременно вставляют строки.
- Каждая получает свой id, даже если одна потом откатится → тоже появляются пропуски.
В PostgreSQL номера генерируются через объект SEQUENCE.
Если ты вручную добавил строку с id = 9999, а sequence «застрял» на 5000.
То, когда при следующих попытках осуществить вставку строки БД дойдет до значения 9999 - этот INSERT упадёт с ошибкой: «дубликат ключа». Потому что sequence не обновляется автоматически! Sequence не смотрит на максимальный id в таблице. Он просто отдаёт своё следующее число.
Решение может быть:
ALTER SEQUENCE … RESTART WITH <нужный номер>.
На вставку строк в таблицу может быть вызов триггера. Потому что вставка строки - это новая информация. А в зависимости от новой информации у нас могут быть разная логика подсчета того или иного показателя. Например, расчет бонусов для клиента зависит от суммы заказа. Поэтому при каждой вставке в таблицу заказов будет вызван триггер по расчету бонусов для клиента.
CREATE TRIGGER bonus
AFTER INSERT ON orders
FOR EACH ROW
EXECUTE FUNCTION bonus_cnt();
Каждая новая строка вызовет bonus_cnt().
Даже если ты вставляешь 1000 строк, триггер вызовется 1000 раз.
Есть еще такое понятие как UPSERT.
UPSERT = INSERT + UPDATE, т.е. «вставить новую запись, а если такая запись уже есть — обновить существующую».
Пример: у нас есть таблица users с колонкой id. Мы хотим добавить пользователя с id = 1.
Если пользователя нет → вставляем.
Если пользователь есть → обновляем его данные.
Но такой INSERT + UPDATE в каждой СУБД реализуется по разному.
Одна и та же логика «вставить или обновить» в коде не переносится напрямую между базами. То, что называется UPSERT в PostgreSQL, будет работать иначе в MySQL и совсем иначе в SQL Server.
INSERT ... ON CONFLICT (id) DO UPDATE ... -- Вставляет запись, если id ещё нет; иначе обновляет эту запись. PostgreSQL
INSERT ... ON DUPLICATE KEY UPDATE ... -- MySQL
MERGE ... -- SQL Server
По сути, UPSERT — это концепция, а не единый универсальный оператор.
На скорость INSERT влияет наличие индексов в таблице. Чем больше индексов, тем долше будет выполняться вставка. Каждая новая строка должна обновить все индексы. При массовых загрузках индексы иногда отключают, а потом создают заново
А еще, иногда база говорит: «Вставка прошла успешно», но на диск ещё ничего не записано.
PostgreSQL и MySQL (InnoDB) используют write-ahead log: запись сначала идёт в журнал, потом — на диск.
Если прямо в этот момент выключить сервер → можно потерять часть данных.
Решается настройкой fsync, commit и уровней надёжности транзакций.
INSERT — это не просто «добавить данные». Это про индексы, блокировки, автоинкременты, батчи и даже про то, как СУБД пишет на диск.