Разработка своей программы, суровые реальности и как такое продавать?
Начнем пожалуй с предыстории.
В далеком прошлом я работал менеджером по логистической инфраструктуре одной крупной компании. В один из рабочих дней, руководство департамента назначает встречу где мы обсуждаем что:
- Нам нужно создать модель которая посчитает нам условия закрытия одного из объектов и как это может повлиять на инфраструктуру, сроки вчера. Чем быстрее тем лучше.
И в этот момент целый департамент принялся проводить анализы, рассчитывать долгосрочную прибыль, затраты и все в этом ключе.
В тот же момент я задумался "А есть ли вообще аналогичная программа, что бы не сидеть и не считать все в табличках, не писать большие запросы в БД?" - ответ был "Есть, но дорого и компания не пойдет на такие затраты".
Спустя время мы конечно закрыли проект со всеми расчетами, применили изменения. Но только вдумайтесь, целый департамент на протяжении пары месяцев считает рентабельность изменения целой инфраструктуры и влияние на него всего лишь закрытием 1-2 объектами. Это колоссальные затраты для компании.
Со временем я перешел в IT, сменил свою сферу деятельности, в свободное время изучал различные языки программирования, фреймворки и понял "А что если разработать аналог для логистической инфраструктуры. Да, конечно дизайн будет не броский, но нам важна лишь функциональность и работоспособность данной программы". Соответственно в начале 25г мною было принято решение начать разработку. Как раз время AI инструментов, не идеальные, но какие-то нюансы они могут подтянуть что бы не лезть в тех доку на изучение той или иной функции/метода/условия.
Язык: Python.
Библиотеки для интерфейса: PyQt6.
Хранилище всей информации: SQLite3.
Частично использовалось: HTML, JS.
И множество второстепенных библиотек для кодирования информации, реализации возможности подключения внешних БД, работы с таблицами и т.п.
Python — язык не самый лучший, да и PyQt библиотека своеобразная и довольно хорошо нагружает систему, сама программа начинает весить тоже немало. Но ведь мы не гонимся за «вау-эффектом».
Перед началом создания программы мною были проведены анализы существующих аналогов. Были варианты на европейском рынке, но все не то либо очень дорого. В основном по моим запросам выдавались программы для
«Оптимизации доставок», «1С:Транспорт», «SAP», «Транспортный анализ» и т.п. Но ни одной подходящей под мое описание программы не было.
Что включало в себя мое виденье всей системы:
Интерактивная карта с маркерами объектов.
Автоматический расчет зонирования регионов в зависимости от исторических данных продаж с доставками.
Отображение линий снабжения объекта прям на карте в формате «Объект А -> Объект Б -> Объект С».
Планирование маршрута при выборе определенных объектов.
Возможность построение интерактивных дашбордов.
Возможность создание различных интерактивных виджетов и их настройка.
Внутренний аналитический куб.
Подключение к внешним БД как к источнику данных и тонкая настройка самим пользователем с маппингом полей.
Создание регионов по складам (ручное выделение самого региона на карте).
И прочие функции, по типу DAX-языка при создании вычислительных полей.
Вишенка на торте всей программы:
10. Анализ инфраструктуры автоматически на ядре программы в формате «Что если?».
А что, если мы закроем магазин на Савеловской — как это повлияет на зону доставок ближайших магазинов/складов. А куда перевозить товар? Сколько машин надо и какая утилизация будет? А какие магазины есть в регионе? А что будет с инфраструктурой, если мы закроем целый склад? Кто теперь будет снабжать товаром магазины? А какая матрица товара есть сейчас? Как изменится структура поставок от основного склада на магазин, будем ли мы задействовать транзитные склады?
Первое, что я начал делать — накидывать БД, да, мы не имеем сервера, поэтому нам надо хранить данные для работы программы локально. Почему не сделать под клиента? Ну-у-у... Возможно, потому что у всех своя структура хранения, а аналитики есть везде, написать SQL-запрос и выгрузить данные по шаблону куда проще, чем делать программу с адаптивом. Имея опыт в работе с логистикой и инфраструктурой, я понимал, какая +- система хранения у всех компаний, труда собрать хранение мне не составило.
Вторым моим шагом стало изолирование всех действий с БД в программе. Т.е. все методы программы не должны общаться на прямую с хранением, а ходить через выделенный файл (ресурс).
Третий шаг — создание интерфейса, вкладок, виджетов и т.д. Можно было сделать через WebView, писать отдельно файлы форм, настраивать JS-логику, передавать сигналы в .py-файлы и т.д. Но это слишком усложняет весь проект, расширяя его код. В таком случае один я уже не смог бы вывести. Поэтому выбрал PyQt6. Долго анализировал, как лучше сделать, но ничего умнее не придумал. Так и родился первый интерфейс программы:
Один из вариантов левого меню.
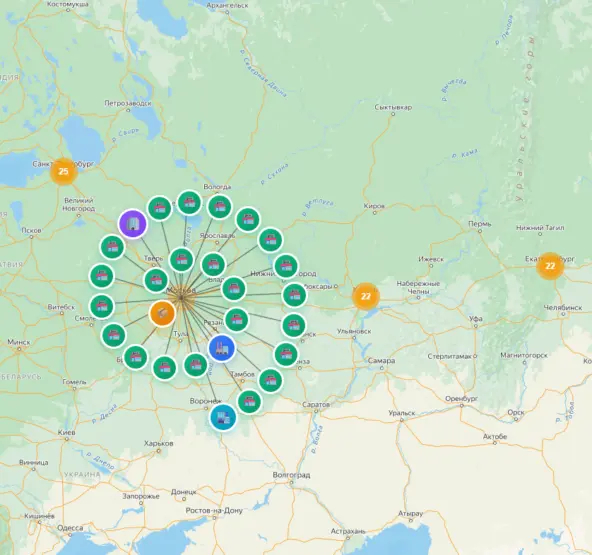
Возможность группировать объекты в рамках ближних зон и разгруппировать при приближении.
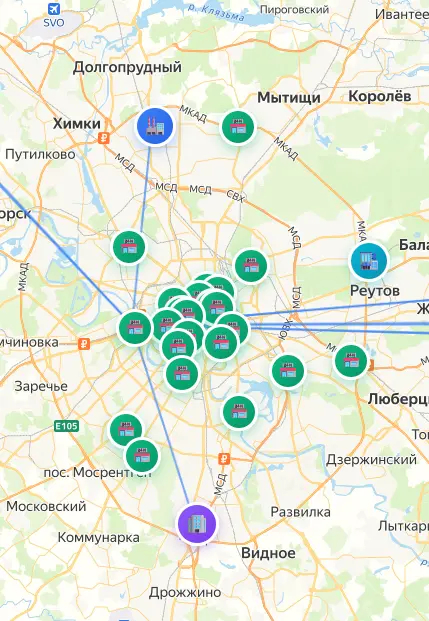
Система отображения линий снабжения.
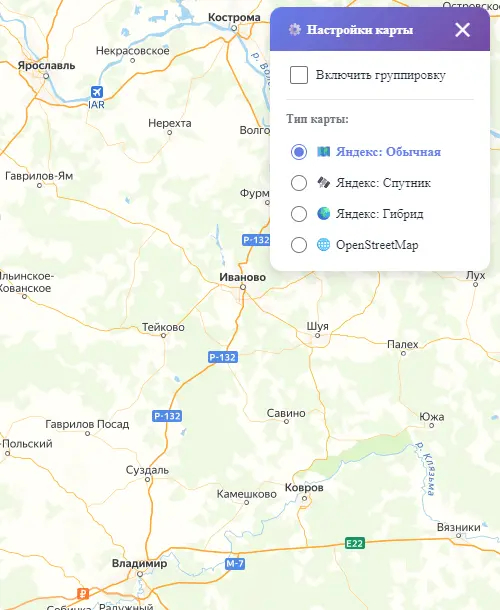
Возможность выбрать среди нескольких типов карт.
Построение тепловой карты по зонированию доставки с учетом исторических данных. К сожалению, данные были сгенерированы через бота, поэтому есть проблемы в формате историчности.
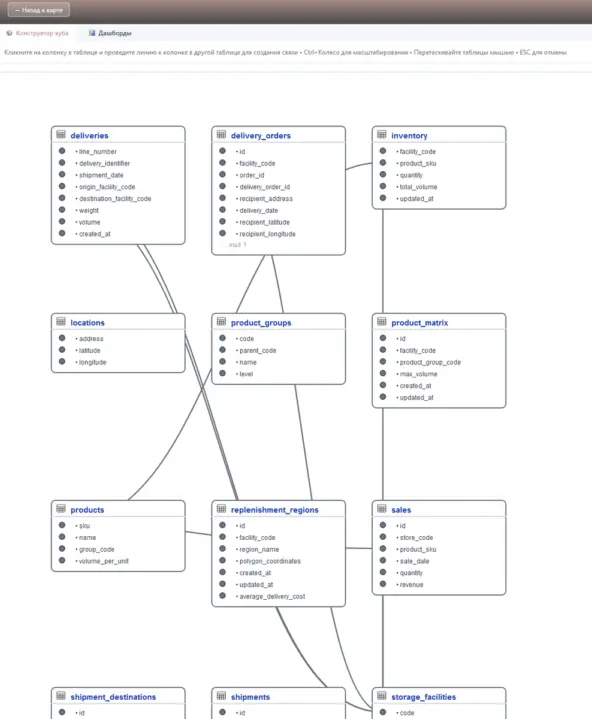
Создание отдельных связей между нестандартными таблицами, на этой основе можно построить запросы.
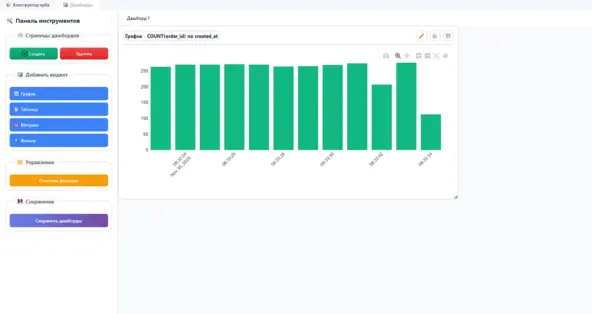
Возможность построить свои дашборды. Перемещать, настраивать и т.д.
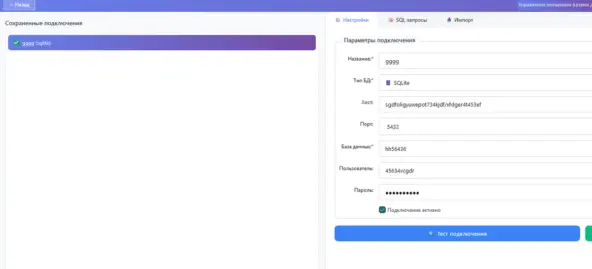
Подключить внешнюю БД (на примере sqlite как заглушка).
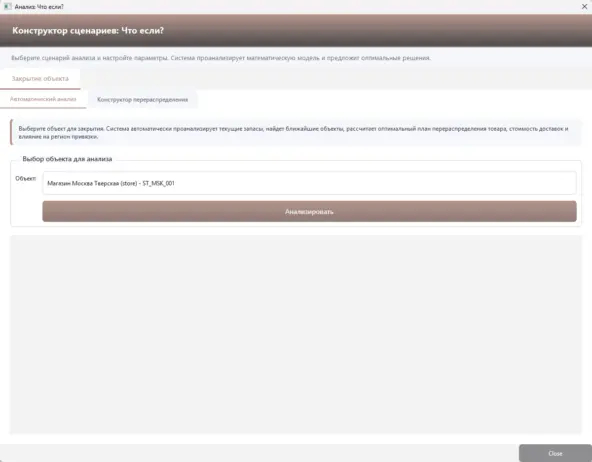
Анализ «Что если?». В анализе пока что реализована лишь один тип «Закрытие объекта», в будущем планируется добавить еще множество конструкторов и методов.
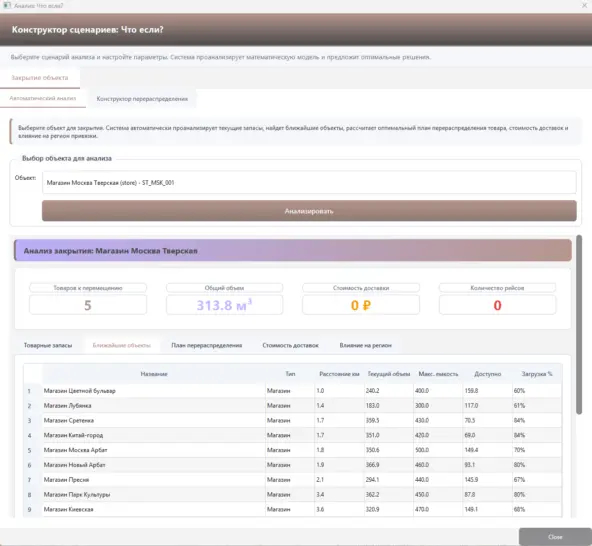
Пример работы анализа. Данные не фактические, лишь заглушки для проверки работы.

Также есть toolbar с интерактивностью. Наводя на кнопки, они расширяются в бок, показывая текст кнопки.
Скриншотами выше я показал лишь часть того, что реализовано в программе. В действительности функционал гораздо больше.
Четвертый шаг — создание ядра всего мыслительного процесса, пользователь нажал на кнопку, а что дальше? Дальше как раз таки отдельные компоненты, которые получают запрос и идут по логике дальше, забирают/обновляют/удаляют данные через шаг 2, интерпретируют их и отдают ответы на модули, которые вызывали.
Да, конечно, с ядром программы я возился довольно долго. Ввиду того что это не 1С, а свой, по сути, уникальный продукт, мне на 80% удалось создать полный конструктор ядра. Что это значит? Значит то, что всю дальнейшую логику мне надо лишь описывать в исполняемых файлах core. Это дало прирост к написанию более качественного кода, более чистого. Да, репозиторий программы увеличился с 15 mvp файлов до 80. Отдельный исполняемый файл практически на каждую форму и отдельно логический файл. Зато мы сразу имеем максимально декомпозированную структуру, которую легко править и изменять процессы.
Далее было много различных шагов, криптография подключения к БД, логирование действий для отслеживания ошибок программы, перевод карты на формат HTML+JS. Получение API ключей и т.д.
В последний момент я задался вопросом: «Как распространять обновления программы? Ведь если я внесу новые правки — пользователь должен их получить. Также я должен делать логирование для использования программы».
Долго я думал над тем, как сделать это все на бесплатном формате. Получилось сделать обновление через Яндекс Диск, авторизацию выделено и рассылку информации о грядущих обновлениях пользователям.
Окно авторизации.
Провал авторизации.
Окно после успешной авторизации с новостной панелью.
Интерфейс для лаунчера я накидал быстро с помощью нейронки, вручную написал код для авторизации на js с py. Настроил всё и протестировал. И «О чудо!» не имея большого бюджета у меня получилось реализовать это всё, над безопасностью авторизации еще, безусловно, стоит потрудиться.
Через некоторое время написал тест кейсы, написал алгоритм для тестирования всех модулей, поправил баги, которые вызывали сбои. Сейчас готова версия 0.5.8. До релиза v1.0.0 еще далеко, много разделов, которые моя голова хочет реализовать.
Что делать дальше? Когда я только начинал, был уверен, что проект можно продать. Я видел такие кейсы и раньше. Думал, что смогу развивать его сам, возможно, еще на год разработки в свободное время меня хватит, и я не погрязну во всей архитектуре. Но год спустя сомнения все чаще берут верх. Может, я зря трачу время?
Возможно, данным постом я смогу найти тех, кого воодушевит мой проект или просто он кому-то приглянется. А возможно, просто получу дельные советы.
Если у вас есть идея и желание реализовать её самостоятельно, смело действуйте.
В скором времени постараюсь выложить еще пост о новых функциях программы.
Делитесь своими комментариями и мнениями.